harvester: [BUG] Automatic disk provisioning result in unusable ghost disks on NVMe drives
Steps
- Install Harvester 1.0.0-rc2 on hardware servers with multiple NVMe disks
- Add all the disks to Harvester using the global setting:
system_settings:
auto-disk-provision-paths: /dev/nvme*
Issue
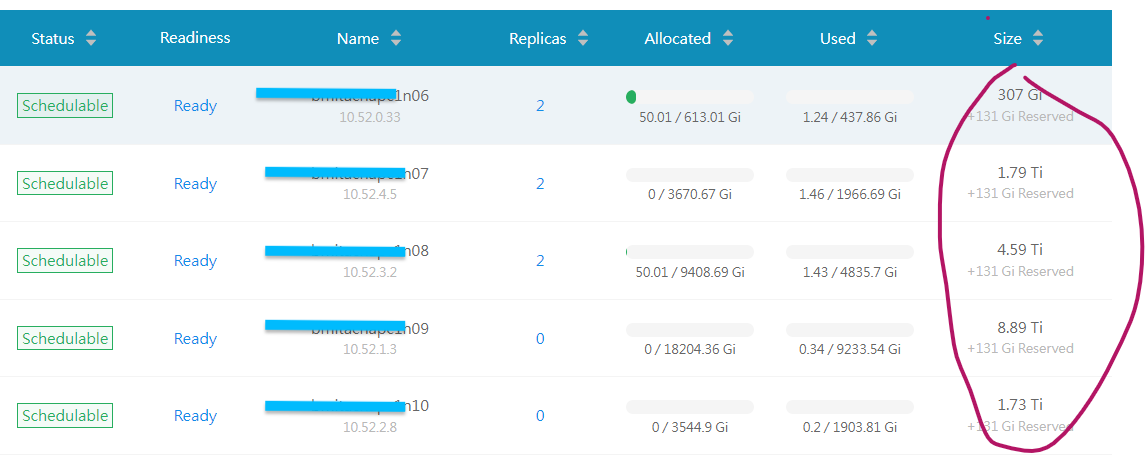
- All the internal nvme drives seem to be active, but there are some ghost disks in the ui, that don’t show up on the system or in blockdevices.harvesterhci.io
- Even though all nodes have identical disks, the UI shows different amount of storage for each node
Extra Info
sandboxc1n10:~ # mount|grep extra-disk
/dev/nvme0n1p1 on /var/lib/harvester/extra-disks/8b964ba6f099f9c37ad67f7e0dcfbc88 type ext4 (rw,relatime,errors=remount-ro)
/dev/nvme1n1p1 on /var/lib/harvester/extra-disks/9a2271cb4fe2209b47d01bc330294418 type ext4 (rw,relatime,errors=remount-ro)
/dev/nvme2n1p1 on /var/lib/harvester/extra-disks/12df0e8f129b4bac41cb464be4f18c61 type ext4 (rw,relatime,errors=remount-ro)
/dev/nvme3n1p1 on /var/lib/harvester/extra-disks/c0e69dd92a250119fc1acf9ee386587f type ext4 (rw,relatime,errors=remount-ro)
/dev/nvme5n1p1 on /var/lib/harvester/extra-disks/c3c3365dfe86e88b61d0fa0a6bb275fa type ext4 (rw,relatime,errors=remount-ro)
/dev/nvme4n1p1 on /var/lib/harvester/extra-disks/7f95ff328dda0610d5386f0e9b33447b type ext4 (rw,relatime,errors=remount-ro)
sandboxc1n10:~ # blkid|grep nvme
/dev/nvme3n1p1: UUID="24bd3f55-268b-4bbd-8f3e-7775e6c29609" BLOCK_SIZE="4096" TYPE="ext4" PARTLABEL="primary" PARTUUID="df093500-30e2-4537-9a76-9d924a1f429a"
/dev/nvme2n1p1: UUID="2ce9698f-2ffb-463c-8851-329f9e504b9d" BLOCK_SIZE="4096" TYPE="ext4" PARTLABEL="primary" PARTUUID="09e97962-91da-4495-af08-c1c939b0c0e6"
/dev/nvme5n1p1: UUID="0a82ba4a-e41d-4947-b2f4-22717316257e" BLOCK_SIZE="4096" TYPE="ext4" PARTLABEL="primary" PARTUUID="0655ebc5-e9c2-4d9b-b75a-85200aa1f63b"
/dev/nvme4n1p1: UUID="02fc138d-1bdf-4d3d-8ade-b0d5485d4ae6" BLOCK_SIZE="4096" TYPE="ext4" PARTLABEL="primary" PARTUUID="bf4ba988-055e-4f12-934f-1abb0d68691c"
/dev/nvme0n1p1: UUID="e1a1fb70-f364-48e1-bf98-b72f0e5ef87b" BLOCK_SIZE="4096" TYPE="ext4" PARTLABEL="primary" PARTUUID="507fccff-b985-475d-8a94-5723416d5d24"
/dev/nvme1n1p1: UUID="1bc37ba2-581b-40f6-b645-64551fb705b6" BLOCK_SIZE="4096" TYPE="ext4" PARTLABEL="primary" PARTUUID="54e2f0f7-efce-4cdc-b2b6-a13da4927bbf"
sandboxc1n10:~ # kubectl get blockdevices.harvesterhci.io -A|grep sandboxc1n10
longhorn-system 066f7b2201a401ef819539085ed39e6e part /dev/nvme0n1p1 /var/lib/harvester/extra-disks/8b964ba6f099f9c37ad67f7e0dcfbc88 sandboxc1n10 Active 168m
longhorn-system 12df0e8f129b4bac41cb464be4f18c61 disk /dev/nvme2n1 sandboxc1n10 Active 169m
longhorn-system 530df031e9355e37aec1e5be797258d1 part /dev/nvme3n1p1 /var/lib/harvester/extra-disks/c0e69dd92a250119fc1acf9ee386587f sandboxc1n10 Active 168m
longhorn-system 7f95ff328dda0610d5386f0e9b33447b disk /dev/nvme4n1 sandboxc1n10 Active 169m
longhorn-system 7ff2488850ed2651bbf3c3ac3b1e4a94 part /dev/nvme2n1p1 /var/lib/harvester/extra-disks/12df0e8f129b4bac41cb464be4f18c61 sandboxc1n10 Active 168m
longhorn-system 863c7902d6a315a93d856e305ad9a005 part /dev/nvme5n1p1 /var/lib/harvester/extra-disks/c3c3365dfe86e88b61d0fa0a6bb275fa sandboxc1n10 Active 168m
longhorn-system 8b964ba6f099f9c37ad67f7e0dcfbc88 disk /dev/nvme0n1 sandboxc1n10 Active 169m
longhorn-system 9a2271cb4fe2209b47d01bc330294418 disk /dev/nvme1n1 sandboxc1n10 Active 169m
longhorn-system ae2ee5767aa38eaea20bcdd9d9115224 part /dev/nvme4n1p1 /var/lib/harvester/extra-disks/7f95ff328dda0610d5386f0e9b33447b sandboxc1n10 Active 167m
longhorn-system aefb46d3eceb78afdaead2fe35d070d7 part /dev/nvme1n1p1 /var/lib/harvester/extra-disks/9a2271cb4fe2209b47d01bc330294418 sandboxc1n10 Active 168m
longhorn-system c0e69dd92a250119fc1acf9ee386587f disk /dev/nvme3n1 sandboxc1n10 Active 169m
longhorn-system c3c3365dfe86e88b61d0fa0a6bb275fa disk /dev/nvme5n1 sandboxc1n10 Active 169m
Support bundle
Available on request
About this issue
- Original URL
- State: closed
- Created 3 years ago
- Comments: 29 (23 by maintainers)
@lanfon72 @weihanglo I think we can consider adding it as a note to the harvester doc, but the
qemu-kvmis not for production use, will only target it for dev/testing purposes.After another investigation, the root cause of this issue is “forgetting to persist the change of blockdevice CR after partitioning”.
Consider this part, the
forceFormatDiskreturns anewDevicebut the caller forgets to persist it. To solve this, we only need patch as the following,I’ve tested the issue under KVM with single-node harvester attached with twenty 20GB SCSI disks. Before this fix the issue is reproducible, but cannot be reproduced after that.
Note that there is still some condition update logic need to change accordingly. Also, since we are going to support direct provision of raw block device. The timeout problem of waiting for partitioning will also be eliminated.
@lanfon72 we may ask for some verification support after the
v1.0.1-rc1 release, should be fine to keep this one on the testing stage.I think it’s more than persisting the change. It’s still a race condition problem.
We’re passing a pointer to
forceFormatDiskFirst of all, because
forceFormatDisktakes the pointer to thedeviceCpystruct,deviceCpyis still being updated without assigning the returned value back todeviceCpy.Why did ghost disks appear?
The appearance of ghost disks is caused by NDM keep repartitioning the disk, even if it’s been done before. Then, because every partitioning action would create a child partition with different
PARTUUID, they are considered as “new” partitions, even if they ultimately represent the same thing: “the first partition of the disk, e.g./dev/sda1”. These new partitions will be picked up by NDM and added as newBlockDevicecustom resources, then provisioned onto Harvester/Longhorn.Theoretically, after a new
BlockDevicefor the partition is created, the oldBlockDevicerepresenting the same thing should be deleted and unprovisioned from Harvester/Longhorn, but here it’s not, thus these oldBlockDeviceare showing as the “ghost disks”. I haven’t figured out why they are not deleted yet but I suspect it’s related to the repartitioning.Reproducing
It seems like after
forceFormatDisksucceeded, the information for indicating the disk has been successfully partitioned is not updated to the disk’sBlockDevicecustom resource. Thus NDM would repartition the device again in the next scanning cycle.After adjusting the disk scanner period and
forceFormatDiskpolling period, I can reproduce the disk repartitioning issue with one only disk. Here’s my explanation of how it occurred:OnBlockDeviceChangedetects the disk should be provisioned, then callforceFormatDiskto partition the disk.forceFormatDiskexecutes the partitioning command to the disk, then waits for the child partition to appear, usingwait.PollImmediate.ScanBlockDevicesOnNodegot triggered by a timer, whileforceFormatDiskis still waiting for the child partition to appear. It scans the Node for the disk’s status, and updates theBlockDevicecustom resource of the disk.forceFormatDiskfound the child partition, updated thedeviceCpystruct using the pointer with necessary information to indicate the disk has been force-formatted. One critical piece of information is theLastFormattedAtfield.forceFormatDiskfinished execution,OnBlockDeviceChangeeventually tries to update the disk’sBlockDevicecustom resource with thedeviceCpystruct modified byforceFormatDisk. However, because it’s been modified byScanBlockDeviceOnNodein step 3, the update will fail due to the resource conflict issue: Because this update failed,LastFormattedAtwill not be updated and will always be empty, so NDM would keep reformating the disk because of this emptiness.Why we didn’t notice this update failure before?
We expect returning error here would cause Wrangler to log an error and requeue the event for retrying. However, no error messages were logged in our case here, so we never noticed the update is failing. We added a line of code to log the
errand then realized it failed with resource conflict error.Reference
cc @weihanglo @yasker
There is a probable fix harvester/node-disk-manager#23 that I believe the re-entry of critical sections in blockdevices reconcilation is the root cause.
A quick simplified analysis, the node-disk-manager and its 30s ticker routine looks needing coordination and race control, especially those hardware related operations.
Another point is about the formatting and mounting of a disk with partitions (e.g.
/dev/nvme4n1,/dev/nvme4n1p1), remove all partitions or keep those partitions or let user control. After formatting/dev/nvme4n1, it will also try to format/dev/nvme4n1p1.