harvester: [BUG] Adding a third node mades the second one to fail
Describe the bug When adding a third node the second one starts failing. SSHing into the failing node shows that a promotion was triggered by the cluster and it failed. rke2 agent is down and rke2 server fails to start.
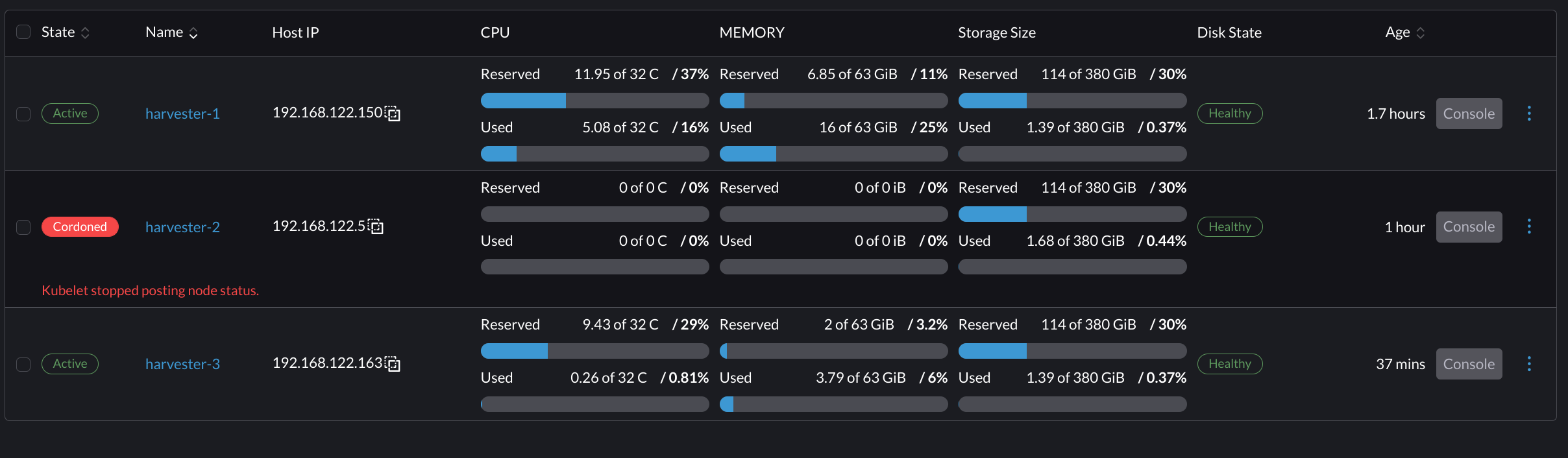

Oct 25 23:16:41 harvester-2 systemd[1]: rke2-server.service: Scheduled restart job, restart counter is at 402.
Oct 25 23:16:41 harvester-2 systemd[1]: Stopped Rancher Kubernetes Engine v2 (server).
Oct 25 23:16:41 harvester-2 systemd[1]: Starting Rancher Kubernetes Engine v2 (server)...
Oct 25 23:16:41 harvester-2 sh[1695]: + /usr/bin/systemctl is-enabled --quiet nm-cloud-setup.service
Oct 25 23:16:41 harvester-2 sh[1701]: Failed to get unit file state for nm-cloud-setup.service: No such file or directory
Oct 25 23:16:41 harvester-2 harv-update-rke2-server-url[1707]: + HARVESTER_CONFIG_FILE=/oem/harvester.config
Oct 25 23:16:41 harvester-2 harv-update-rke2-server-url[1707]: + RKE2_VIP_CONFIG_FILE=/etc/rancher/rke2/config.yaml.d/90-harvester-vip.yaml
Oct 25 23:16:41 harvester-2 harv-update-rke2-server-url[1707]: + case $1 in
Oct 25 23:16:41 harvester-2 harv-update-rke2-server-url[1707]: + rm -f /etc/rancher/rke2/config.yaml.d/90-harvester-vip.yaml
Oct 25 23:16:41 harvester-2 rke2[1711]: time="2022-10-25T23:16:41Z" level=warning msg="Unknown flag --apiVersion found in config.yaml, skipping\n"
Oct 25 23:16:41 harvester-2 rke2[1711]: time="2022-10-25T23:16:41Z" level=warning msg="Unknown flag --kind found in config.yaml, skipping\n"
Oct 25 23:16:41 harvester-2 rke2[1711]: time="2022-10-25T23:16:41Z" level=warning msg="Unknown flag --omitStages found in config.yaml, skipping\n"
Oct 25 23:16:41 harvester-2 rke2[1711]: time="2022-10-25T23:16:41Z" level=warning msg="Unknown flag --omitStages found in config.yaml, skipping\n"
Oct 25 23:16:41 harvester-2 rke2[1711]: time="2022-10-25T23:16:41Z" level=warning msg="Unknown flag --rules found in config.yaml, skipping\n"
Oct 25 23:16:41 harvester-2 rke2[1711]: time="2022-10-25T23:16:41Z" level=warning msg="not running in CIS mode"
Oct 25 23:16:41 harvester-2 rke2[1711]: time="2022-10-25T23:16:41Z" level=info msg="Starting rke2 v1.24.7+rke2r1 (5fd5150f752a663efa16ac3ae2aac5d6bba6c364)"
Oct 25 23:16:41 harvester-2 rke2[1711]: time="2022-10-25T23:16:41Z" level=info msg="Managed etcd cluster bootstrap already complete and initialized"
Oct 25 23:16:42 harvester-2 rke2[1711]: time="2022-10-25T23:16:42Z" level=warning msg="Cluster CA certificate is not trusted by the host CA bundle, but the token does not include a CA hash. Use the full token from the server's node-token file to enable Cluster CA validation."
Oct 25 23:16:42 harvester-2 rke2[1711]: time="2022-10-25T23:16:42Z" level=info msg="Reconciling bootstrap data between datastore and disk"
Oct 25 23:16:42 harvester-2 rke2[1711]: time="2022-10-25T23:16:42Z" level=fatal msg="/var/lib/rancher/rke2/server/tls/service.key, /var/lib/rancher/rke2/server/tls/etcd/server-ca.crt, /var/lib/rancher/rke2/server/tls/etcd/server-ca.key, /var/lib/rancher/rke2/server/cred/encryption-state.json, /var/lib/rancher/rke2/server/tls/request-header-ca.crt, /var/lib/rancher/rke2/server/tls/request-header-ca.key, /var/lib/rancher/rke2/server/tls/etcd/peer-ca.crt, /var/lib/rancher/rke2/server/cred/ipsec.psk, /var/lib/rancher/rke2/server/tls/server-ca.key, /var/lib/rancher/rke2/server/tls/client-ca.crt, /var/lib/rancher/rke2/server/tls/client-ca.key, /var/lib/rancher/rke2/server/cred/passwd, /var/lib/rancher/rke2/server/tls/server-ca.crt, /var/lib/rancher/rke2/server/tls/etcd/peer-ca.key, /var/lib/rancher/rke2/server/cred/encryption-config.json newer than datastore and could cause a cluster outage. Remove the file(s) from disk and restart to be recreated from datastore."
Oct 25 23:16:42 harvester-2 systemd[1]: rke2-server.service: Main process exited, code=exited, status=1/FAILURE
Oct 25 23:16:42 harvester-2 systemd[1]: rke2-server.service: Failed with result 'exit-code'.
Oct 25 23:16:42 harvester-2 systemd[1]: Failed to start Rancher Kubernetes Engine v2 (server).
To Reproduce Steps to reproduce the behavior:
- Create 3 vms using virt-manager with 32 cores / 64 gb ram / 500 gb of storage / single nic, using the master, 1.1.0 or 1.0.3 iso to boot the system, waiting until one node is fully installed before installing the next one.
- When the third node is added the second node will get cordoned when the promotion is triggered and then kubelet stops responding.
Expected behavior We expect the second node not to fail the promotion process.
Support bundle
supportbundle_5c04607a-f1df-4da1-b131-87db50c43651_2022-10-25T22-55-24Z.zip scc_harvester-2_221025_2256.txz.zip (generated with supportconfig -k -c on the node that failed the promotion)
Environment
- Harvester ISO version: master (as of 2022-10-25), 1.0.3 and 1.1.0
- Underlying Infrastructure (e.g. Baremetal with Dell PowerEdge R630): qemu, each vm with a single nic, 32 cores, 64 gb ram, and a 500gb disk
Additional context Add any other context about the problem here.
About this issue
- Original URL
- State: open
- Created 2 years ago
- Comments: 23 (13 by maintainers)
@rajesh1084 @lkoba I am able to reproduce the issue easily. Environment:
Attaching a lot of files, if any kubelet - journalctl - or containerd logs from the second node help:
(the video is sped up)
https://user-images.githubusercontent.com/5370752/198406663-c7d96461-caf5-4e6b-a487-2eac64df6bd7.mp4
(logs) node-2-kubelet.log node-2-containerd.log log-node-2-large-journalctl-tail-log.log
Support Bundle: supportbundle_68f9c6f7-1e17-429c-9e67-4aac29379d39_2022-10-27T21-35-20Z.zip
I did note, that it does seem to resolve itself after a while. While the second node did become cordoned & unschedulable for a period of time - it did return to a management status node after a period of time. But yes, the second node did “go offline” so to speak for a period of time. Without any work-around, preventing the second node from going offline for a period of time.
In an upgrade, it also seems to be noted that the second node went into a cordoned / unschedulable state here, tho this may not be related: https://github.com/harvester/harvester/issues/3041#issuecomment-1291845922