longhorn: [BUG] Volume restoration will never complete if attached node is down
Describe the bug (🐛 if you encounter this issue)
During volume restoration in progress, shutdown the attached node, volume restoration will never complete and volume will stuck at attaching state.
Happened in longhorn mastre-head e1ea3d and v1.4.1-rc1 but not in v1.4.0
To Reproduce
Steps to reproduce the behavior:
- Create a backup.
- Restore the above backup.
- Power off the volume attached node during the restoring.
- Wait for the Longhorn node down.
- Wait for the restore volume being reattached and starting restoring volume with state Degraded.
- Volume stuck at
attachingstate and the restore will never complete
Expected behavior
Volume attached to another node then restore complete after awhile
Log or Support bundle
supportbundle_2c216df5-e12c-4b2e-8373-0833d6802812_2023-03-02T03-46-21Z.zip
Environment
- Longhorn version: master-head
e1ea3dand v1.4.1-rc1 - Installation method (e.g. Rancher Catalog App/Helm/Kubectl): kubectl
- Kubernetes distro (e.g. RKE/K3s/EKS/OpenShift) and version: v1.24.7+k3s1
- Number of management node in the cluster: 1
- Number of worker node in the cluster: 3
- Underlying Infrastructure (e.g. on AWS/GCE, EKS/GKE, VMWare/KVM, Baremetal): AWS
- Number of Longhorn volumes in the cluster: 1
Additional context
N/A
About this issue
- Original URL
- State: closed
- Created a year ago
- Comments: 31 (30 by maintainers)
@weizhe0422 is the status of the engine also unknown? If yes, because
r.Status.CurrentStateis also unknown, there is no chance to make the replica fail./controller/volume_controller.go#L543-L566
It seems when a node is down or not ready, the current implementation will make the status of the instance manager unknown (https://github.com/longhorn/longhorn/issues/2650), and it would cause the engine/replica on that node to have unknown status as well. I thought when a node is really down, the status should be error (
InstanceManagerStateError) instead./controller/instance_manager_controller.go#L322-L330
/controller/instance_handler.go#L56-L70
cc @derekbit @shuo-wu @c3y1huang
Update: the issue and https://github.com/longhorn/longhorn/issues/5477 are both passed after applying the solution.
@weizhe0422 @shuo-wu @innobead Can you help check if there is any concern? Thank you.
@innobead @derekbit Using the version that adding this logic to skip replica on the down node, I execute the test step as below:
rep-a,rep-bservice k3s-agent stopon node containing one of the replica and the node doesn’t have the volume engine:rep-arep_abecomesstoppedand therep_bkeeps restoringrep_baccomplish restoring, both two replicas becomesstoppedservice k3s-agent startto recover the k3s. Therep_awill becomerunningat first for a second then thenstopped. But there is no rebuilding operation forrep_aand it is also not create another replica on the other node.I think this is related to this change; it will continue keep waiting without attach on the node since the status of replica on the stopped node is
stopped.https://github.com/longhorn/longhorn-manager/blob/c29563ca46a476b4ebc52cdfe9e6b8126a31ec10/controller/volume_controller.go#L1609-L1611
Before this modification, the time will be recorded in the
FailedAtfield of the replica on the stopped node https://github.com/longhorn/longhorn-manager/blob/9e4630586a9484d63d0c6f6826d0568b10391afe/controller/volume_controller.go#L1498-L1500so it will be skipped in the checking mechanism and then attach according to the node where the volume is located. https://github.com/longhorn/longhorn-manager/blob/9e4630586a9484d63d0c6f6826d0568b10391afe/controller/volume_controller.go#L1521-L1523
Maybe it need also bypass check the replica which is on the stopped node.
cc @innobead @derekbit
My concern is: when the node is unknown (like kubelet down/network disconnection) but the workload & engine & replica are still storing new data, should we mark the replica as Failed rather than how can the replica be marked as Failed? At that moment, I am thinking if we could clean up the unknown replica when it really blocks the attachment. In brief, marking it as Failed then deleting it during attachment.
Then I just had a discussion with Derek. He mentioned that the cluster is messy when there are this kind of nodes then emphasizing data integrity at that moment may be meaningless. But with my idea, the risk of attachment flow would increase. We have to do a trade-off. Relying on the existing fix is good enough.
In this case, engine process marks the replica as mode ERR as you mentioned, and it’s later deleted.
The node down is detected here .
I’m thinking if the solution is reasonable or not.
When the engine is not in
attachedmode, the replica can be marked as failed if the node is down directly. Except for theattachedmode, we should not rely on the data plane’s connectivity status. Does it make sense?Well, after applying the patch, the unknown replica is deleted from the
engine.status.replicaModeMap. That means the io cannot go to the unknown replica. It breaks the fix in 5340…@innobead No, the engine state is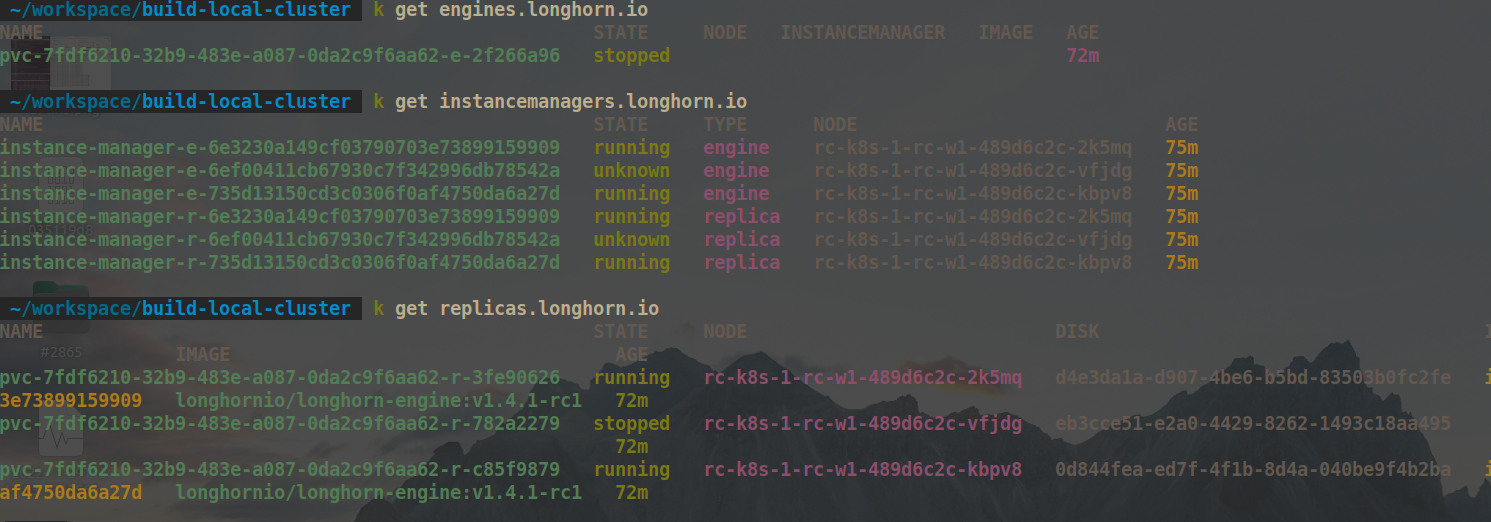
stopped. I think it is because when synchronize the im-e status to engine but the engine is not started (status.Started==false)And I think you might be right if the node is down then the status should be marked as
error, so it can update the spec fields of replica and engine. I’ll go into the details and do some testing.Yeah, something like that.