longhorn: [BUG] Scalability issue of volumes in Longhorn
Describe the bug
According to the scalability benchmark for Longhorn v1.0.1 and the scalability benchmark for Longhorn v1.2.0 , Longhorn v1.2.0 has worse scalability performance than Longhorn v1.0.1.
In Longhorn v1.0.1 the graph looks linear util 900 volumes. However, in v1.2.0 the graph looks linear for the first 410 volumes and shoot up.
Additional context Support bundle and Kubectl top are provided in the comment https://github.com/longhorn/longhorn/issues/2986#issuecomment-929751211
About this issue
- Original URL
- State: closed
- Created 3 years ago
- Comments: 18 (11 by maintainers)
Reproducing steps:
Test plan:
The Longhorn installation part will be improved when the new design for https://github.com/longhorn/longhorn/issues/2582 is introduced. I will write down the design as a LEP once I start to work on it. In brief, before each manager pod becomes running, it needs to acquire the leadership and walk through all upgrade paths. This behavior greatly slows down the installation.
Once both this and the issues mentioned by Joshua are fixed, we can re-visit the scalability.
The numbers are looking good. We are able to handle thousands of volumes now. After this issue, the future improvement could be:
The estimates for the scalability issues are in the air and shouldn’t be considered final (rough guideline only), we already identified some specific scalability issues which we plan on addressing afterwards we can do another evaluation pass to see if there are additional issues. (i.e engine-binary invocation, installation / upgrade process)
Validation - PASSED
Tested with v1.3.0-rc2 image , longhorn-manager no longer slows down after 500 volumes.
Notes for QAs,
Test workload:
Node spec:
Validation Status Update: non_io
Testing with master-head with non_io test from scale_test.py on 3+10 rke2 cluster with following steps:
Resource change can be referenced in the figures below:
Pod-Time chart: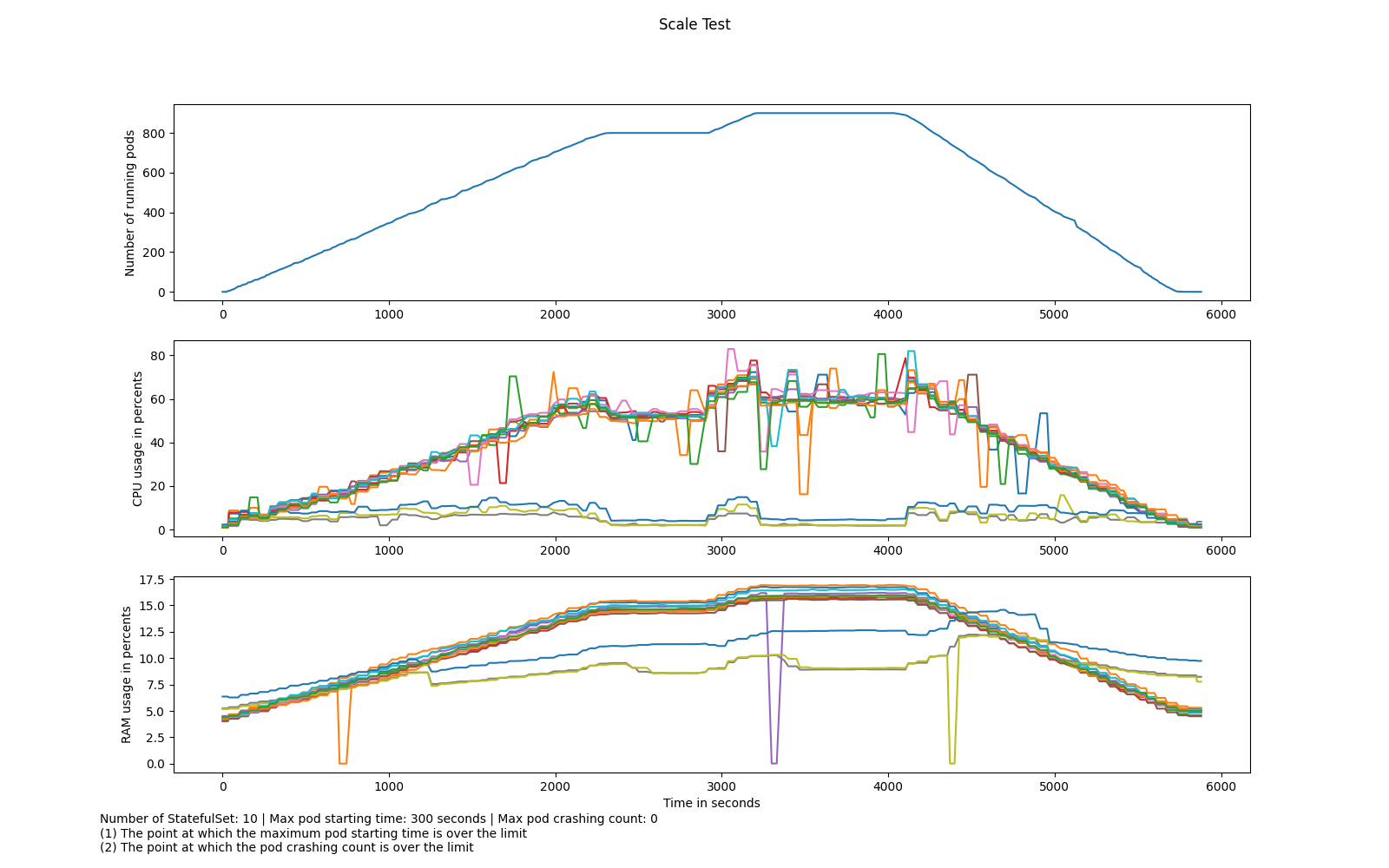
Total workqueue chart: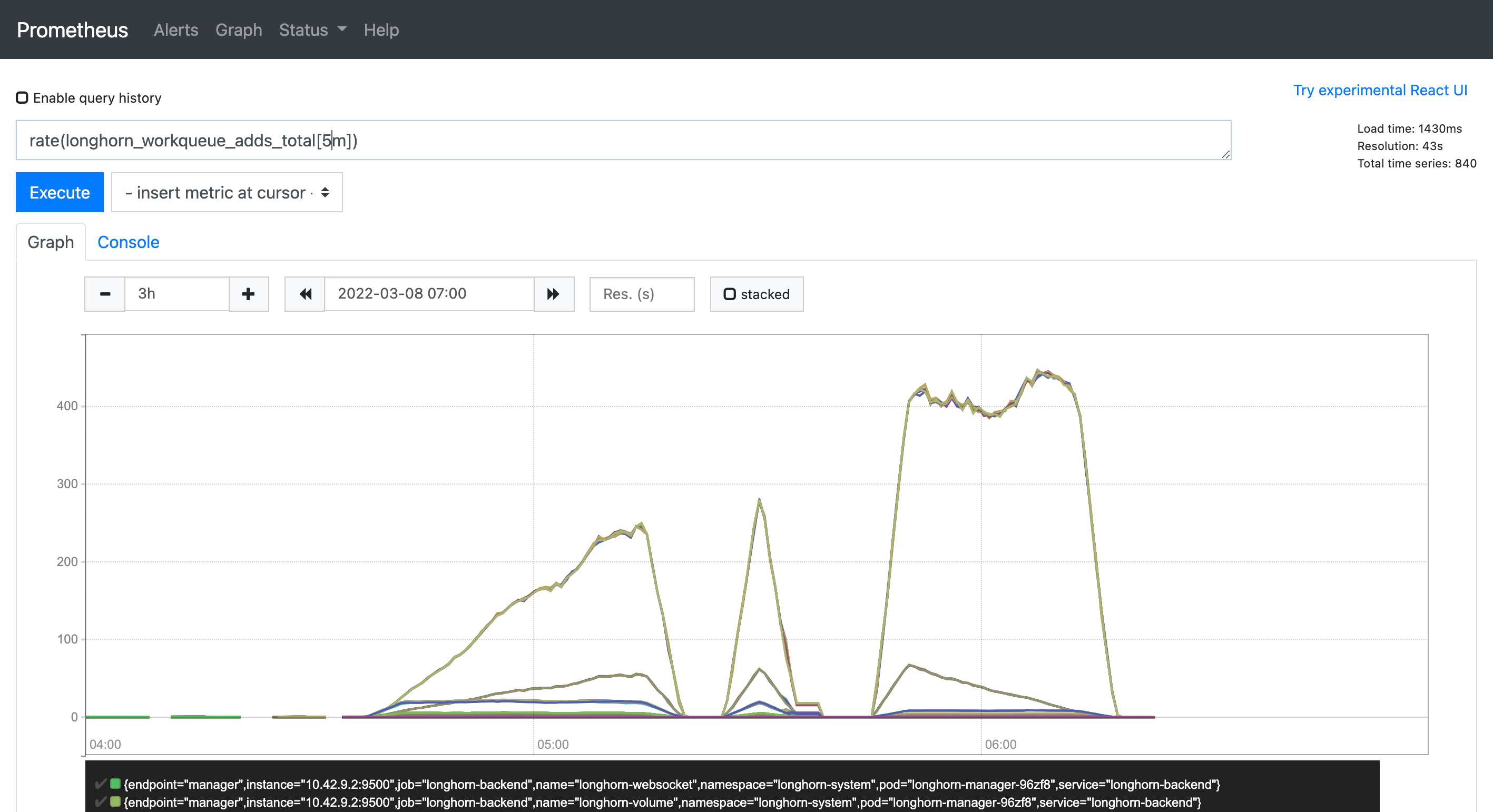
Just leaving a note here: I previously discussed the workqueue issue with @PhanLe1010 and asked him to see if he can expose the metrics, that come with the work queue, that should allow us to identify the culprits and cases that lead to long queue times. I further asked him to start his testing with a long resync period since the resync period currently hides issues as well as could lead to issues if the calls are not idempotent or the processing of all the resources takes longer than the resync period eventually.
The binary invocations which we are addressing in #3546 as well as some resource monitoring refactorings we need to do remove the resource modifications and eval out of the controller workers ref #2441 should reduce the time per resource eval loop in the controllers since at the moment their might be some slow operations which need to be done outside of the controller and only synced against the states, we did part of this for the new backup monitoring routines.
The biggest scalability issue that is currently present is the engine binary invocation which leads to many socket opening/closings in a short time frame. #2778 https://github.com/longhorn/longhorn/issues/2818#issuecomment-887865452