istio: Pilot crash under performance test resulting in abnormal behavior of Istio applications
Describe the bug
Pilot performance test scenario:
Static configuration:
Pilot discovery resource requests: 2CPU 13G
Each sidecar resource requests: 1CPU 2G
Dynamic configuration:
-
During the initial test period, we deployed:
- 500 services and corresponding 500 pods inside the Istio mesh(with Istio sidecar injected)
- 160 services and 900 pods outside the Istio mesh
Pilot memory usage gets a steady increase during the initial deployment process. Finally pilot works normally after some times.
Check the below pilot metrics from Grafana(the part before 17:08):
-
During the pressure test period, we do:
- Firstly create 50 namespaces
- Create 20 services(2 ports for each service), corresponding 20 pods, 20 serviceaccounts into each namespace.
Note: All applications deployed during this step are outside Istio mesh. This is reasonable in production environment, because applications size in the cluster can be very huge while the mesh is small.
Then we found that Pilot crashes due to OM killed and try to restart, but no good, please check the above pilot metrics from Grafana(the part after 17:08).
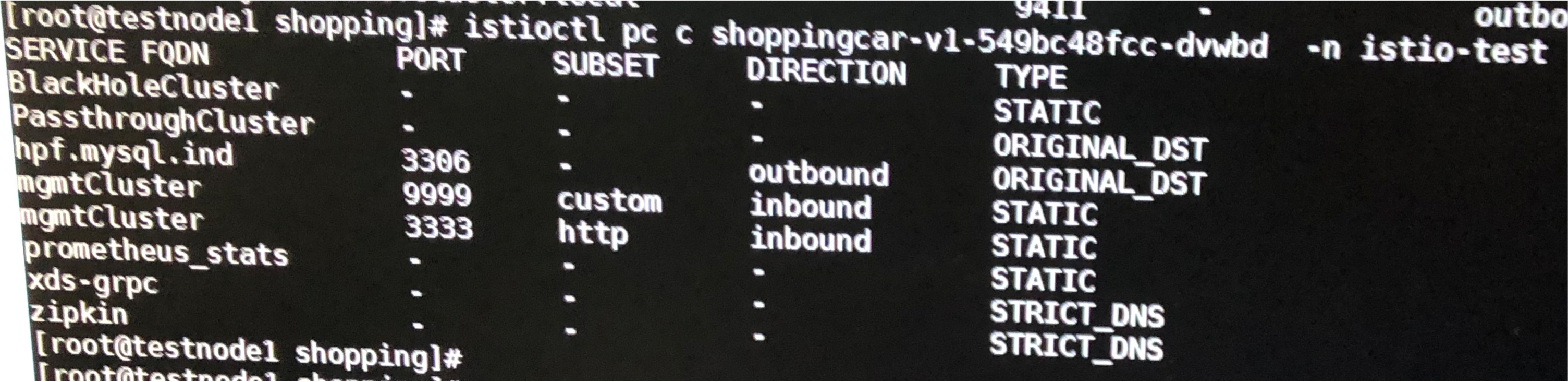
What’s weird is that after pilot crashed, we found that all envoy endpoints with type EDS are missing from istioctl proxy-config cluster and the Istio application can’t be accessed.
Check the below diagram:
Istio data plane(applications and sidecar) is supposed to be working, even the pilot is down, isn’t it?
We then dump the envoy configuration from 15000 admin port of sidecar:

As you can see, we only get endpoints of type ‘ORIGINAL_DST’ and STATIC, all others are gone.
Expected behavior Even pilot crashes, all istio applications should also work without traffic drops.
Steps to reproduce the bug {{ Minimal steps to reproduce the behavior }}
Version istio-1.1.0-snapshot.6
[root@master istio-1.1.0-snapshot.6]# istioctl version
version.BuildInfo{Version:"1.1.0-snapshot.6", GitRevision:"14777199b85ba56ebca2a4516afff33c97199eb4", User:"root", Host:"f0f1db73-2fb5-11e9-86e9-0a580a2c0304", GolangVersion:"go1.10.4", DockerHub:"docker.io/istio", BuildStatus:"Clean", GitTag:"1.1.0-snapshot.5-156-g1477719"}
Installation
Istio installed with kubectl apply -f istio-demo-auth.yaml
About this issue
- Original URL
- State: closed
- Created 5 years ago
- Comments: 35 (32 by maintainers)
Thanks @rshriram, let me explain in more details.
OOM. And during that period, part of endpoints for envoy sidecar were gone. However, If we uninstalled the services and pods outside of the cluster, the pilot restarted and envoy endpoints came back. Envoy sidecars are supposed to be working even pilot isn’t running, isn’t it?OOM.Actually some customers are in badly need of watching namespace list for pilot, especially these with on-premises cluster. They have much more services running in single cluster outside of the Istio mesh in which
sidecarconfiguration doesn’t helps a lot. I have raised a PR for this.@ayj when galley directly delivers endpoints and goes down, how is the galley client handling this? It should also not eject state because of loss of connectivity.
I just want to add that the same thing happens when the pilot cannot talk with the masters nodes. This leads to 404 or 503 response codes. I think this is exactly the same point of this issue, in case of pilot failure the proxies must maintain the last configuration applied