harvester: [BUG] Flapping Cluster Network bond interface every ten hours, causing VM outages if they write to disk when bond is down
(This appears isolated to bonds managed by the harvester network components, and does not happen to standard opensuse bonds (mgmt bond) on the same hardware (nic and switch))
In a freshly installed Harvester 1.1.1 cluster installed from ISO and no configuration file, with a cluster network bond created post-install via the web interface, the associated bond flaps every ten hours on every node in the cluster, e.g. as showed here:
3:/home/rancher # dmesg -Tw |grep "device vm-bo left"
[Wed Mar 29 16:13:37 2023] device vm-bo left promiscuous mode
[Thu Mar 30 02:13:37 2023] device vm-bo left promiscuous mode
[Thu Mar 30 12:13:37 2023] device vm-bo left promiscuous mode
[Thu Mar 30 22:13:38 2023] device vm-bo left promiscuous mode
[Fri Mar 31 08:13:38 2023] device vm-bo left promiscuous mode
We experience this across a variety of machine classes and hardware (intel/amd cpu, dell/lenovo servers). Switches are various Juniper switches (QFX5120-48Y-8C, EX4300 across multiple physical server rooms - no central management plane, both using MC-lang and virtual chassis). Networking hardware (all affected, all optical with various transceivers):
- FastLinQ QL41000 Series 10/25/40/50GbE Controller
- Ethernet Controller X710 for 10GbE SFP+
Each flap is also associated with a spike in CPU load on the node:
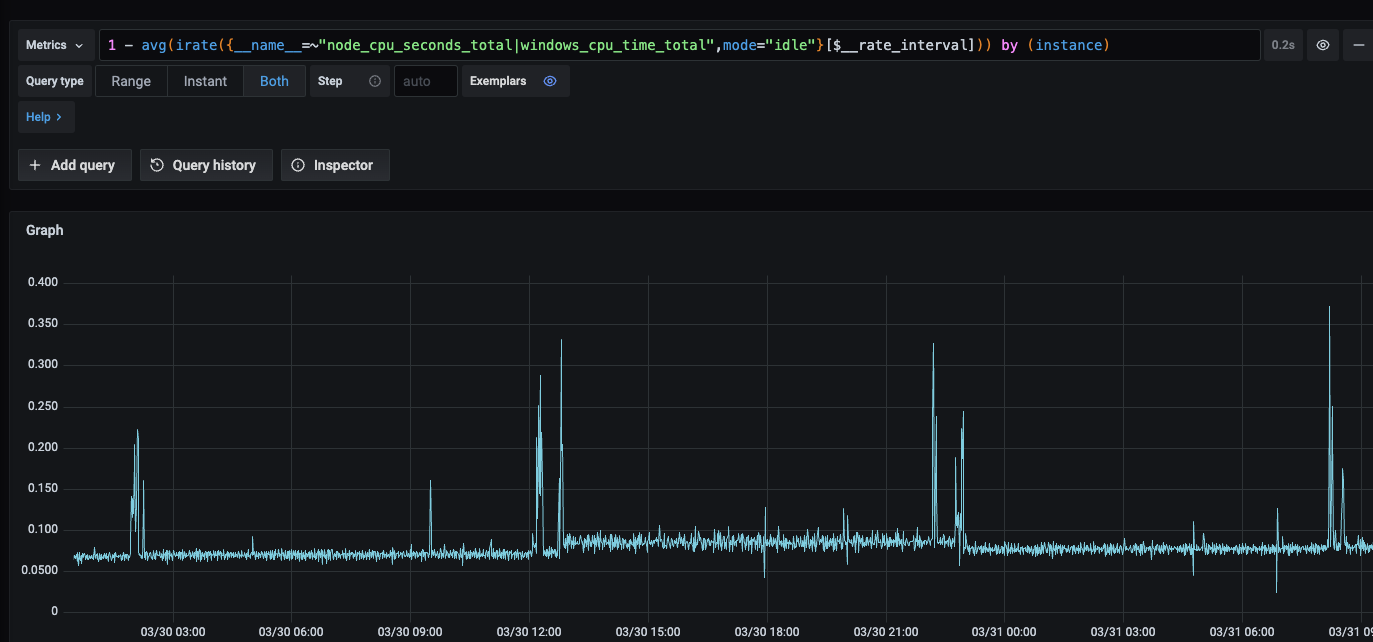
We attempted to change from 802.3ad to balance-alb this morning as a suggestion for a more easily verifiable bonding mode as per @abonilla at https://rancher-users.slack.com/archives/C01GKHKAG0K/p1680091948550239?thread_ts=1677066561.067599&cid=C01GKHKAG0K - this had no effect, and we received the vm-bo flap on the 10th hour as expected afterwards (in real time half an hour after making the change to balance-alb)
To Reproduce
- Install Harvester 1.1.1 on three nodes
- Once installed, configure a cluster network called
vmusing web UI with bonding using 802.3ad and two 10Gbe interfaces - Create VM networks on top of cluster network, attach VMs to said VM networks
- Configure storage network on top of
vmcluster network, separate VLAN id - Observe dmesg on nodes, where
device vm-bo left promiscuous modewill start showing up after a while, then every ten hours
Expected behavior Bond should stay up unless physically disconnected. VM Workloads should survive short outages.
Support bundle Support bundle provided here in comment below.
Environment
- Harvester ISO version: 1.1.1
- Baremetal Lenovo SR530+ (10c AMD, Synology NIC, Juniper EX4300) (+ other servers types, switches and nics we use in other clusters)
About this issue
- Original URL
- State: closed
- Created a year ago
- Reactions: 1
- Comments: 23 (10 by maintainers)
Hi @oivindoh
I think I faced the same issue. and dig into the network controller code. maybe this unverified patch will solve this problem. But we still need to wait for Harvester team to confirm the root cause.
The root cause I thought (not confirmed):
kernel log also showed
vm-bowas removed and recreated.this msg will only be shown while
vm-bois deleted.Unverified Patch: https://github.com/tjjh89017/network-controller-harvester/commit/5f119a4eeee8c26fa91985423e885aaf125797e0
I think no one changed them. But when controller constructs the bond struct from VlanConfig, it will copy the optional fields into it or leave it as default value. When leaving it as default, it will be zero or empty string for those fields. And controller loads current linux bond state to bond struct, it will load all current state (e.g. MTU) MTU in linux will always be non-zero value. So comparing MTU with both struct will always be different. (VlanConfig default 0 vs Linux network stack 1500)
but I think my patch is just a workaround. We should remove the condition from compare function and only leave “Name” & “Mode” there. Move MTU, HWaddr, TxQlen to upper function, if they are not zero, controller should always override them to linux network via netlink
Thanks for the fix @tjjh89017 - this looks good 👍 😄 ! I’m going to go ahead and close this out.
When checking with rc8 - this seems to be good I’m not noticing anything from dmesg & network-controller logs like before when the network-controller-pod would restart. Nor any spikes on CPU utilization. While a VM is running and writing/removing from disk continuously. I’m not seeing the network drop - when killing the pod several times. This sample was over the last 45~ min, killing the pod intermittently and letting it come back up.
dmesgdoesn’t indicate the interface being disabled/enabled since it’s been up and running.The 10-hour reconcile could be the default behavior from controller-runtime according to this:
https://github.com/kubernetes-sigs/controller-runtime/blob/fbd6b944a634b7ea577fe523a3a93cbf9695e88c/pkg/manager/manager.go#L142-L169
To verify the similar behavior, we can delete the network-controller Pod to make it restart again to see if reconciling Vlanconfig resource will introduce the issue or not.
network-controller restart: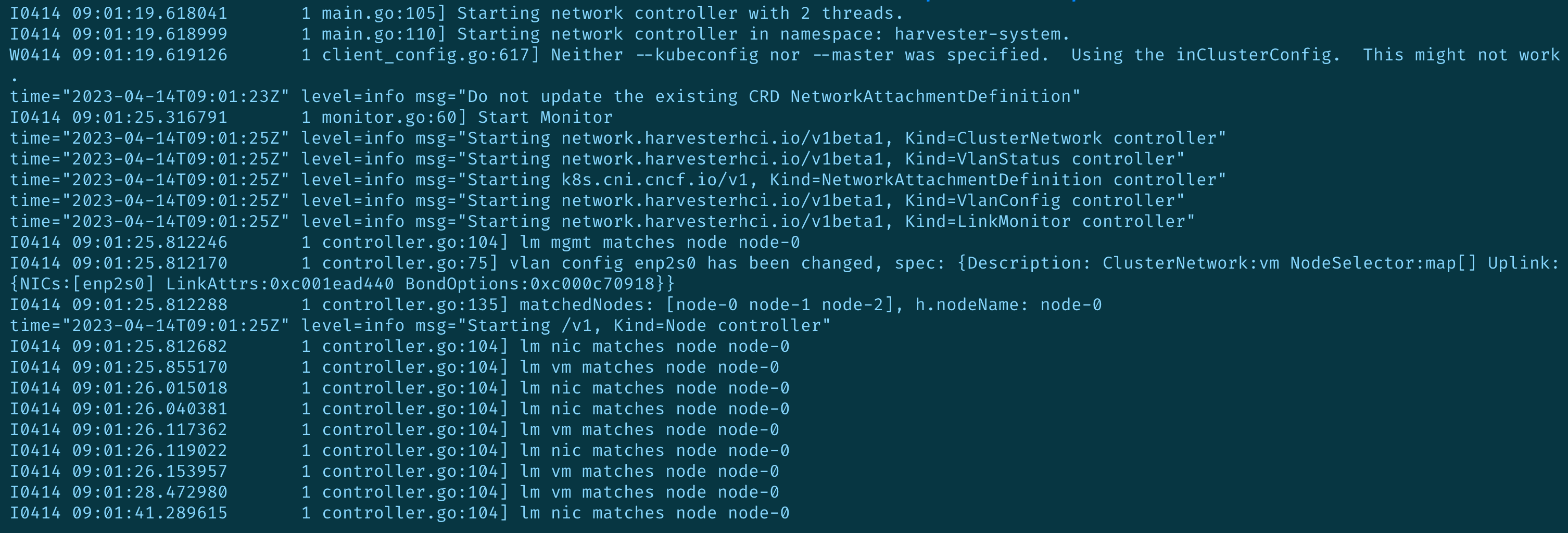
The bonding interface is removed and added again: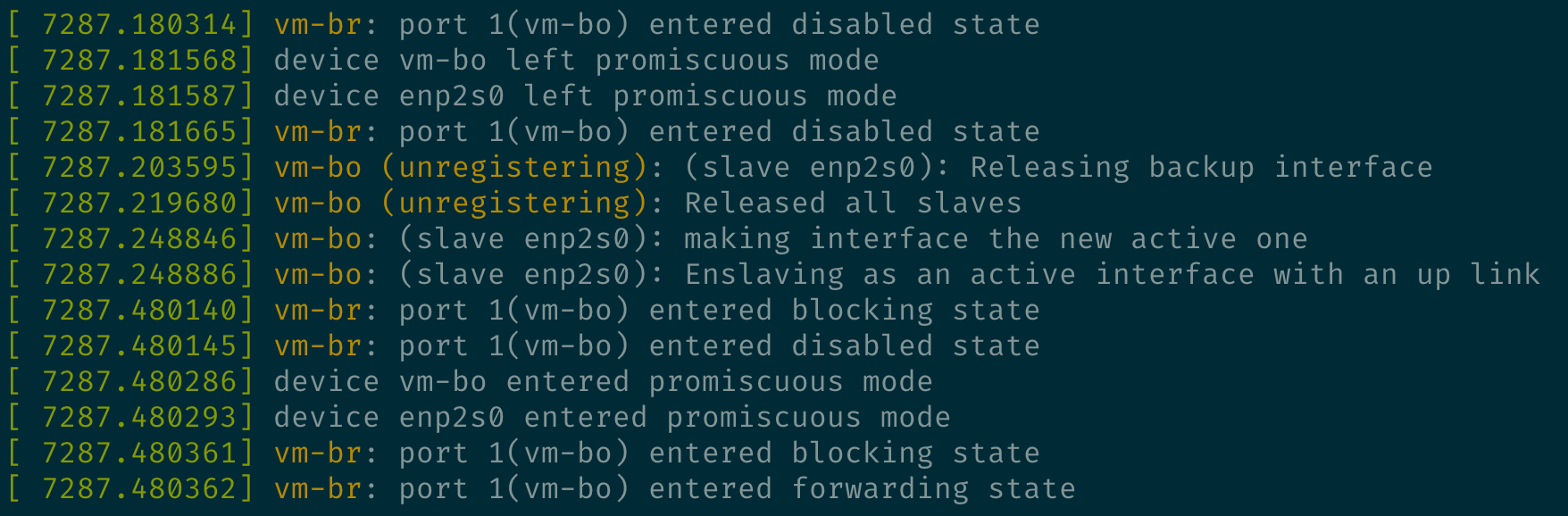
Verified the patch works, no link flapping happened during reconciliation introduced by network controller restart.
Thanks @tjjh89017!