detectron2: DeepLab Inference seems to not be working / Unable to display predictions
Hi, thank you Yuxin and team for making this amazing resource and for all of your support answering questions!!!
I’m running into an issue where I think I am either not running inference properly or I’m just having difficulty displaying my predictions because I keep getting an error when trying to run visualize_data.py.
Instructions To Reproduce the 🐛 Bug:
- Full runnable code or full changes you made:
This is my file
train_net_xbd.py(removing imports)
def build_sem_seg_train_aug(cfg):
augs = [
T.ResizeShortestEdge(
cfg.INPUT.MIN_SIZE_TRAIN, cfg.INPUT.MAX_SIZE_TRAIN, cfg.INPUT.MIN_SIZE_TRAIN_SAMPLING
)
]
if cfg.INPUT.CROP.ENABLED:
augs.append(
T.RandomCrop_CategoryAreaConstraint(
cfg.INPUT.CROP.TYPE,
cfg.INPUT.CROP.SIZE,
cfg.INPUT.CROP.SINGLE_CATEGORY_MAX_AREA,
cfg.MODEL.SEM_SEG_HEAD.IGNORE_VALUE,
)
)
augs.append(T.RandomFlip())
return augs
class Trainer(DefaultTrainer):
"""
We use the "DefaultTrainer" which contains a number pre-defined logic for
standard training workflow. They may not work for you, especially if you
are working on a new research project. In that case you can use the cleaner
"SimpleTrainer", or write your own training loop.
"""
@classmethod
def build_evaluator(cls, cfg, dataset_name, output_folder=None):
"""
Create evaluator(s) for a given dataset.
This uses the special metadata "evaluator_type" associated with each builtin dataset.
For your own dataset, you can simply create an evaluator manually in your
script and do not have to worry about the hacky if-else logic here.
"""
if output_folder is None:
output_folder = os.path.join(cfg.OUTPUT_DIR, "inference")
evaluator_list = []
evaluator_type = MetadataCatalog.get(dataset_name).evaluator_type
if evaluator_type == "sem_seg":
print("datasetname", dataset_name)
return SemSegEvaluator(
dataset_name,
distributed=True,
num_classes=cfg.MODEL.SEM_SEG_HEAD.NUM_CLASSES,
ignore_label=cfg.MODEL.SEM_SEG_HEAD.IGNORE_VALUE,
output_dir=output_folder,
)
return DatasetEvaluators(evaluator_list)
@classmethod
def build_train_loader(cls, cfg):
if "SemanticSegmentor" in cfg.MODEL.META_ARCHITECTURE:
mapper = DatasetMapper(cfg, is_train=True, augmentations=build_sem_seg_train_aug(cfg))
else:
mapper = None
return build_detection_train_loader(cfg, mapper=mapper)
@classmethod
def build_lr_scheduler(cls, cfg, optimizer):
"""
It now calls :func:`detectron2.solver.build_lr_scheduler`.
Overwrite it if you'd like a different scheduler.
"""
return build_lr_scheduler(cfg, optimizer)
def setup(args):
"""
Create configs and perform basic setups.
"""
cfg = get_cfg()
add_deeplab_config(cfg)
cfg.merge_from_file(args.config_file)
cfg.merge_from_list(args.opts)
cfg.freeze()
default_setup(cfg, args)
return cfg
def get_building_dicts(img_dir):
"""This function loads the JSON file created with the annotator and converts it to
the detectron2 metadata specifications.
"""
img_links = glob.glob(img_dir+"labels/*.json")
# only keep the images that include post
img_anns = list(filter(lambda x: "post" in x, img_links))
dataset_dicts = []
# loop through the entries in the JSON file
for idx, single in enumerate(img_anns):
v = json.load(open(single))
record = {}
# add file_name, image_id, height and width information to the records
filename = os.path.join(img_dir, "images/", v["metadata"]["img_name"])
height, width = (v["metadata"]["height"], v["metadata"]["width"])
record["file_name"] = filename
record["image_id"] = idx
record["height"] = height
record["width"] = width
record["sem_seg_file_name"] = img_dir+"bin_masks/" + v["metadata"]["img_name"]
dataset_dicts.append(record)
return dataset_dicts
def main(args):
for d in ["train", "test"]:
DatasetCatalog.register(
"xbddata_" + d, lambda d=d: get_building_dicts("/n/tambe_lab/Users/michelewang/" + d+"/"),
)
MetadataCatalog.get("xbddata_"+d).stuff_classes = ["0","1","2"]
MetadataCatalog.get("xbddata_"+d).evaluator_type = "sem_seg"
print("Dataset Catalog", DatasetCatalog.list())
print("XBDDATA_TRAIN", DatasetCatalog.get("xbddata_train"))
xbdtrain_metadata = MetadataCatalog.get("xbddata_train")
xbdtest_metadata = MetadataCatalog.get("xbddata_test")
cfg = setup(args)
if args.eval_only:
print("hi, we're in eval only")
model = Trainer.build_model(cfg)
print("cfg.MODEL.WEIGHTS", cfg.MODEL.WEIGHTS)
print("cfg.OUTPUT_DIR", cfg.OUTPUT_DIR)
DetectionCheckpointer(model, save_dir=cfg.OUTPUT_DIR).resume_or_load(
cfg.MODEL.WEIGHTS, resume=args.resume
)
res = Trainer.test(cfg, model)
return res
trainer = Trainer(cfg)
trainer.resume_or_load(resume=args.resume)
return trainer.train()
if __name__ == "__main__":
args = default_argument_parser().parse_args()
print("Command Line Args:", args)
launch(
main,
args.num_gpus,
num_machines=args.num_machines,
machine_rank=args.machine_rank,
dist_url=args.dist_url,
args=(args,),
)
This is my file visualize_data.py:
#!/usr/bin/env python
# Copyright (c) Facebook, Inc. and its affiliates.
import argparse
import os
from itertools import chain
import cv2
import tqdm
from detectron2.config import get_cfg
from detectron2.data import DatasetCatalog, MetadataCatalog, build_detection_train_loader
from detectron2.data import detection_utils as utils
from detectron2.data.build import filter_images_with_few_keypoints
from detectron2.utils.logger import setup_logger
from detectron2.utils.visualizer import Visualizer
def setup(args):
cfg = get_cfg()
if args.config_file:
cfg.merge_from_file(args.config_file)
cfg.merge_from_list(args.opts)
cfg.DATALOADER.NUM_WORKERS = 0
cfg.freeze()
return cfg
def parse_args(in_args=None):
parser = argparse.ArgumentParser(description="Visualize ground-truth data")
parser.add_argument(
"--source",
choices=["annotation", "dataloader"],
required=True,
help="visualize the annotations or the data loader (with pre-processing)",
)
parser.add_argument("--config-file", metavar="FILE", help="path to config file")
parser.add_argument("--output-dir", default="./", help="path to output directory")
parser.add_argument("--show", action="store_true", help="show output in a window")
parser.add_argument(
"opts",
help="Modify config options using the command-line",
default=None,
nargs=argparse.REMAINDER,
)
return parser.parse_args(in_args)
if __name__ == "__main__":
args = parse_args()
logger = setup_logger()
logger.info("Arguments: " + str(args))
cfg = setup(args)
dirname = args.output_dir
os.makedirs(dirname, exist_ok=True)
metadata = MetadataCatalog.get(cfg.DATASETS.TRAIN[0])
def output(vis, fname):
if args.show:
print(fname)
cv2.imshow("window", vis.get_image()[:, :, ::-1])
cv2.waitKey()
else:
filepath = os.path.join(dirname, fname)
print("Saving to {} ...".format(filepath))
vis.save(filepath)
scale = 1.0
if args.source == "dataloader":
train_data_loader = build_detection_train_loader(cfg)
for batch in train_data_loader:
for per_image in batch:
# Pytorch tensor is in (C, H, W) format
img = per_image["image"].permute(1, 2, 0).cpu().detach().numpy()
img = utils.convert_image_to_rgb(img, cfg.INPUT.FORMAT)
visualizer = Visualizer(img, metadata=metadata, scale=scale)
target_fields = per_image["instances"].get_fields()
labels = [metadata.thing_classes[i] for i in target_fields["gt_classes"]]
vis = visualizer.overlay_instances(
labels=labels,
boxes=target_fields.get("gt_boxes", None),
masks=target_fields.get("gt_masks", None),
keypoints=target_fields.get("gt_keypoints", None),
)
output(vis, str(per_image["image_id"]) + ".jpg")
else:
dicts = list(chain.from_iterable([DatasetCatalog.get(k) for k in cfg.DATASETS.TRAIN]))
if cfg.MODEL.KEYPOINT_ON:
dicts = filter_images_with_few_keypoints(dicts, 1)
for dic in tqdm.tqdm(dicts):
img = utils.read_image(dic["file_name"], "RGB")
visualizer = Visualizer(img, metadata=metadata, scale=scale)
vis = visualizer.draw_dataset_dict(dic)
output(vis, os.path.basename(dic["file_name"]))
- What exact command you run: This was the script I ran for inference (It finished in <1 min so I think something is wrong here):
cd /n/home07/michelewang/thesis/detectron2/projects/DeepLab
python train_net_xbd.py --config-file configs/xBD-configs/base-deeplabv3.yaml --eval-only MODEL.WEIGHTS ./output/model_0024999.pth
This was the script I ran to try to view my predictions:
cd /n/home07/michelewang/thesis/detectron2/tools
python visualize_data.py --source annotation --config-file ../projects/DeepLab/configs/xBD-configs/base-deeplabv3.yaml --output-dir ../projects/DeepLab/output/inference --show
- Full logs or other relevant observations: Logs from Inference:
[5m[31mWARNING[0m [32m[03/07 21:38:53 d2.evaluation.sem_seg_evaluation]: [0mSemSegEvaluator(num_classes) is deprecated! It should be obtained from metadata.
[5m[31mWARNING[0m [32m[03/07 21:38:53 d2.evaluation.sem_seg_evaluation]: [0mSemSegEvaluator(ignore_label) is deprecated! It should be obtained from metadata.
[32m[03/07 21:38:54 d2.evaluation.evaluator]: [0mStart inference on 933 images
[32m[03/07 21:38:56 d2.evaluation.evaluator]: [0mInference done 11/933. 0.0817 s / img. ETA=0:01:55
[32m[03/07 21:39:01 d2.evaluation.evaluator]: [0mInference done 51/933. 0.0817 s / img. ETA=0:01:50
[32m[03/07 21:39:06 d2.evaluation.evaluator]: [0mInference done 70/933. 0.0817 s / img. ETA=0:02:26
[32m[03/07 21:39:11 d2.evaluation.evaluator]: [0mInference done 110/933. 0.0818 s / img. ETA=0:02:06
[32m[03/07 21:39:17 d2.evaluation.evaluator]: [0mInference done 150/933. 0.0818 s / img. ETA=0:01:54
[32m[03/07 21:39:22 d2.evaluation.evaluator]: [0mInference done 190/933. 0.0819 s / img. ETA=0:01:45
[32m[03/07 21:39:27 d2.evaluation.evaluator]: [0mInference done 229/933. 0.0820 s / img. ETA=0:01:38
[32m[03/07 21:39:32 d2.evaluation.evaluator]: [0mInference done 270/933. 0.0820 s / img. ETA=0:01:30
[32m[03/07 21:39:37 d2.evaluation.evaluator]: [0mInference done 310/933. 0.0819 s / img. ETA=0:01:24
[32m[03/07 21:39:42 d2.evaluation.evaluator]: [0mInference done 351/933. 0.0819 s / img. ETA=0:01:18
[32m[03/07 21:39:47 d2.evaluation.evaluator]: [0mInference done 391/933. 0.0819 s / img. ETA=0:01:12
[32m[03/07 21:39:52 d2.evaluation.evaluator]: [0mInference done 432/933. 0.0819 s / img. ETA=0:01:06
[32m[03/07 21:39:57 d2.evaluation.evaluator]: [0mInference done 473/933. 0.0819 s / img. ETA=0:01:00
[32m[03/07 21:40:02 d2.evaluation.evaluator]: [0mInference done 514/933. 0.0819 s / img. ETA=0:00:54
[32m[03/07 21:40:07 d2.evaluation.evaluator]: [0mInference done 554/933. 0.0818 s / img. ETA=0:00:49
[32m[03/07 21:40:12 d2.evaluation.evaluator]: [0mInference done 595/933. 0.0818 s / img. ETA=0:00:44
[32m[03/07 21:40:17 d2.evaluation.evaluator]: [0mInference done 636/933. 0.0818 s / img. ETA=0:00:38
[32m[03/07 21:40:23 d2.evaluation.evaluator]: [0mInference done 677/933. 0.0818 s / img. ETA=0:00:33
[32m[03/07 21:40:28 d2.evaluation.evaluator]: [0mInference done 717/933. 0.0818 s / img. ETA=0:00:27
[32m[03/07 21:40:33 d2.evaluation.evaluator]: [0mInference done 758/933. 0.0818 s / img. ETA=0:00:22
[32m[03/07 21:40:38 d2.evaluation.evaluator]: [0mInference done 799/933. 0.0818 s / img. ETA=0:00:17
[32m[03/07 21:40:43 d2.evaluation.evaluator]: [0mInference done 840/933. 0.0818 s / img. ETA=0:00:11
[32m[03/07 21:40:48 d2.evaluation.evaluator]: [0mInference done 881/933. 0.0818 s / img. ETA=0:00:06
[32m[03/07 21:40:53 d2.evaluation.evaluator]: [0mInference done 922/933. 0.0818 s / img. ETA=0:00:01
[32m[03/07 21:40:54 d2.evaluation.evaluator]: [0mTotal inference time: 0:01:59.094921 (0.128335 s / img per device, on 1 devices)
[32m[03/07 21:40:54 d2.evaluation.evaluator]: [0mTotal inference pure compute time: 0:01:15 (0.081782 s / img per device, on 1 devices)
[32m[03/07 21:40:56 d2.evaluation.sem_seg_evaluation]: [0mOrderedDict([('sem_seg', {'mIoU': 14.286231780375028, 'fwIoU': 30.412502468859948, 'IoU-0': 31.958253593820217, 'IoU-1': 5.555678249276511, 'IoU-2': 5.344763498028353, 'mACC': 53.518182755044954, 'pACC': 34.17634953767668, 'ACC-0': 32.13264257356594, 'ACC-1': 69.63928432518483, 'ACC-2': 58.78262136638409})])
[32m[03/07 21:40:56 d2.engine.defaults]: [0mEvaluation results for xbddata_test in csv format:
[32m[03/07 21:40:56 d2.evaluation.testing]: [0mcopypaste: Task: sem_seg
[32m[03/07 21:40:56 d2.evaluation.testing]: [0mcopypaste: mIoU,fwIoU,mACC,pACC
[32m[03/07 21:40:56 d2.evaluation.testing]: [0mcopypaste: 14.2862,30.4125,53.5182,34.1763
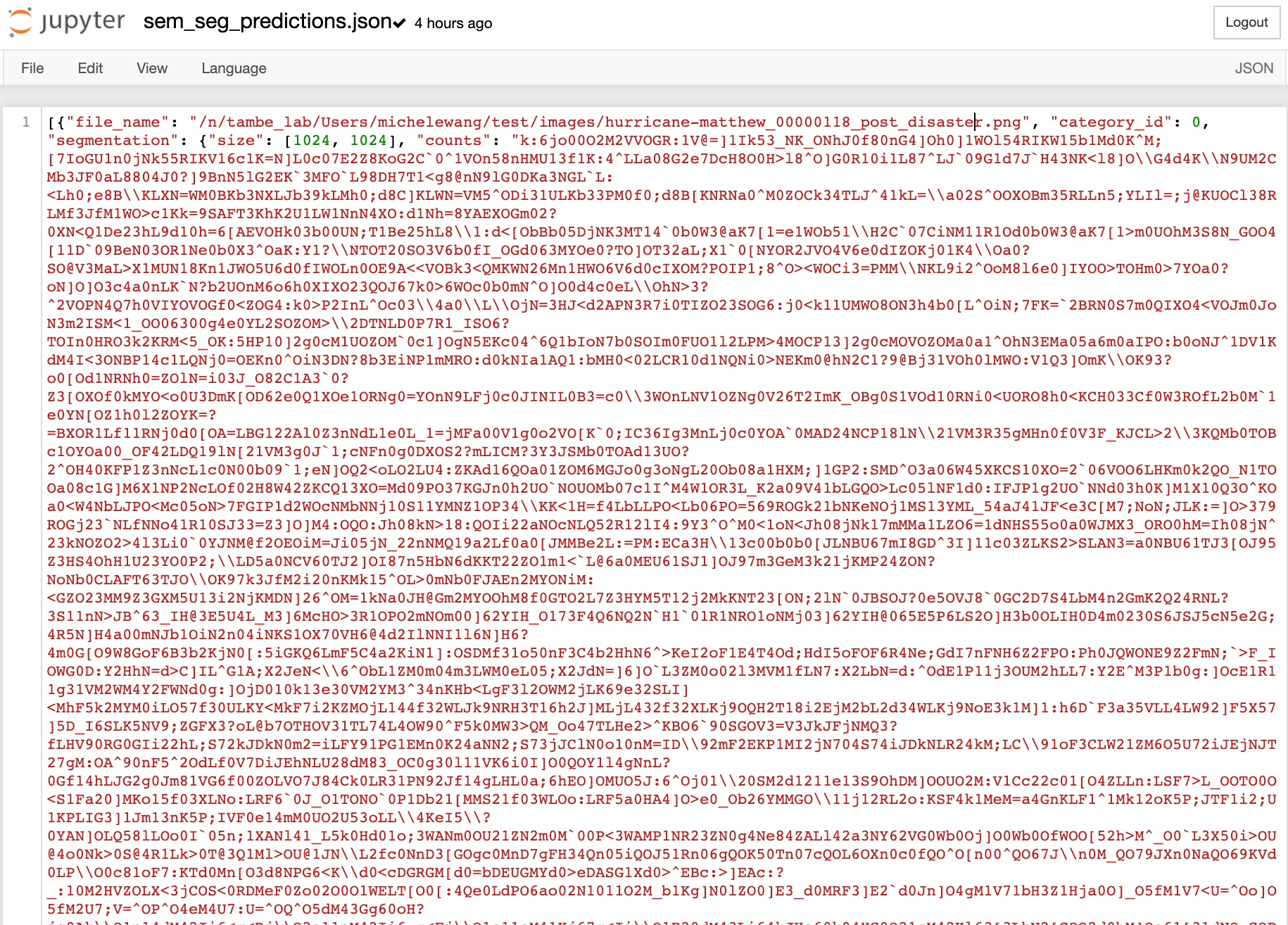
The Semantic Segmentation JSON created in my Outputs folder, sem_seg_predictions.json – is this normal??
The Error I got from my second script to visualize_data.py:
Traceback (most recent call last):
Traceback (most recent call last):
File "visualize_data.py", line 51, in <module>
cfg = setup(args)
File "visualize_data.py", line 20, in setup
cfg.merge_from_file(args.config_file)
File "/n/home07/michelewang/.conda/envs/active/lib/python3.8/site-packages/detectron2/config/config.py", line 54, in merge_from_file
self.merge_from_other_cfg(loaded_cfg)
File "/n/home07/michelewang/.conda/envs/active/lib/python3.8/site-packages/fvcore/common/config.py", line 123, in merge_from_other_cfg
return super().merge_from_other_cfg(cfg_other)
File "/n/home07/michelewang/.conda/envs/active/lib/python3.8/site-packages/yacs/config.py", line 217, in merge_from_other_cfg
_merge_a_into_b(cfg_other, self, self, [])
File "/n/home07/michelewang/.conda/envs/active/lib/python3.8/site-packages/yacs/config.py", line 478, in _merge_a_into_b
_merge_a_into_b(v, b[k], root, key_list + [k])
File "/n/home07/michelewang/.conda/envs/active/lib/python3.8/site-packages/yacs/config.py", line 478, in _merge_a_into_b
_merge_a_into_b(v, b[k], root, key_list + [k])
File "/n/home07/michelewang/.conda/envs/active/lib/python3.8/site-packages/yacs/config.py", line 491, in _merge_a_into_b
raise KeyError("Non-existent config key: {}".format(full_key))
KeyError: 'Non-existent config key: MODEL.RESNETS.RES5_MULTI_GRID'
- please simplify the steps as much as possible so they do not require additional resources to run, such as a private dataset.
Expected behavior:
I first ran the inference script. It ran really fast, taking less than a minute. Then I ran the script to visualize my predictions, because I wanted to see how accurate Deeplab’s semantic segmentation predictions for my model were. However, I was blocked by syntax errors for the model and I don’t think I did inference correctly given that it ran so fast, and the Json file of predictions, is gibberish, but I’m not sure how to do it correctly.
Environment:
Provide your environment information using the following command:
wget -nc -q https://github.com/facebookresearch/detectron2/raw/master/detectron2/utils/collect_env.py && python collect_env.py
If your issue looks like an installation issue / environment issue, please first try to solve it yourself with the instructions in https://detectron2.readthedocs.io/tutorials/install.html#common-installation-issues
Full Error Logs for Inference the stuff at the top is just the model reprinting all the data in my original train dataset)
{'file_name': '/n/tambe_lab/Users/michelewang/train/images/midwest-flooding_00000173_post_disaster.png', 'image_id': 2715, 'height': 1024, 'width': 1024, 'sem_seg_file_name': '/n/tambe_lab/Users/michelewang/train/bin_masks/midwest-flooding_00000173_post_disaster.png'}, {'file_name': '/n/tambe_lab/Users/michelewang/train/images/midwest-flooding_00000293_post_disaster.png', 'image_id': 2716, 'height': 1024, 'width': 1024, 'sem_seg_file_n
[32m[03/07 21:38:45 detectron2]: [0mRank of current process: 0. World size: 1
[32m[03/07 21:38:48 detectron2]: [0mEnvironment info:
---------------------- -----------------------------------------------------------------------------------------------------------------
sys.platform linux
Python 3.8.5 (default, Sep 4 2020, 07:30:14) [GCC 7.3.0]
numpy 1.19.2
detectron2 0.3 @/n/home07/michelewang/.conda/envs/active/lib/python3.8/site-packages/detectron2
Compiler GCC 9.2
CUDA compiler not available
detectron2 arch flags /n/home07/michelewang/.conda/envs/active/lib/python3.8/site-packages/detectron2/_C.cpython-38-x86_64-linux-gnu.so
DETECTRON2_ENV_MODULE <not set>
PyTorch 1.7.1 @/n/home07/michelewang/.conda/envs/active/lib/python3.8/site-packages/torch
PyTorch debug build False
GPU available True
GPU 0,1,2,3,4,5,6,7 Tesla V100-PCIE-32GB (arch=7.0)
CUDA_HOME /n/helmod/apps/centos7/Core/cuda/10.2.89-fasrc01/cuda
Pillow 8.1.0
torchvision 0.8.2 @/n/home07/michelewang/.conda/envs/active/lib/python3.8/site-packages/torchvision
torchvision arch flags 3.5, 5.0, 6.0, 7.0, 7.5
fvcore 0.1.3.post20210220
cv2 4.4.0
---------------------- -----------------------------------------------------------------------------------------------------------------
PyTorch built with:
- GCC 7.3
- C++ Version: 201402
- Intel(R) Math Kernel Library Version 2020.0.2 Product Build 20200624 for Intel(R) 64 architecture applications
- Intel(R) MKL-DNN v1.6.0 (Git Hash 5ef631a030a6f73131c77892041042805a06064f)
- OpenMP 201511 (a.k.a. OpenMP 4.5)
- NNPACK is enabled
- CPU capability usage: AVX2
- CUDA Runtime 10.1
- NVCC architecture flags: -gencode;arch=compute_37,code=sm_37;-gencode;arch=compute_50,code=sm_50;-gencode;arch=compute_60,code=sm_60;-gencode;arch=compute_61,code=sm_61;-gencode;arch=compute_70,code=sm_70;-gencode;arch=compute_75,code=sm_75;-gencode;arch=compute_37,code=compute_37
- CuDNN 7.6.3
- Magma 2.5.2
- Build settings: BLAS=MKL, BUILD_TYPE=Release, CXX_FLAGS= -Wno-deprecated -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -DUSE_VULKAN_WRAPPER -O2 -fPIC -Wno-narrowing -Wall -Wextra -Werror=return-type -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wno-sign-compare -Wno-unused-parameter -Wno-unused-variable -Wno-unused-function -Wno-unused-result -Wno-unused-local-typedefs -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Wno-stringop-overflow, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, USE_CUDA=ON, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_MKL=ON, USE_MKLDNN=ON, USE_MPI=OFF, USE_NCCL=ON, USE_NNPACK=ON, USE_OPENMP=ON,
[32m[03/07 21:38:48 detectron2]: [0mCommand line arguments: Namespace(config_file='configs/xBD-configs/base-deeplabv3.yaml', dist_url='tcp://127.0.0.1:62862', eval_only=True, machine_rank=0, num_gpus=1, num_machines=1, opts=['MODEL.WEIGHTS', './output/model_0024999.pth'], resume=False)
[32m[03/07 21:38:48 detectron2]: [0mContents of args.config_file=configs/xBD-configs/base-deeplabv3.yaml:
_BASE_: base.yaml
MODEL:
WEIGHTS: "detectron2://DeepLab/R-103.pkl"
PIXEL_MEAN: [123.675, 116.280, 103.530]
PIXEL_STD: [58.395, 57.120, 57.375]
BACKBONE:
NAME: "build_resnet_deeplab_backbone"
RESNETS:
DEPTH: 101
NORM: "SyncBN"
OUT_FEATURES: ["res2", "res5"]
RES5_MULTI_GRID: [1, 2, 4]
STEM_TYPE: "deeplab"
STEM_OUT_CHANNELS: 128
STRIDE_IN_1X1: False
SEM_SEG_HEAD:
NAME: "DeepLabV3PlusHead"
IN_FEATURES: ["res2", "res5"]
PROJECT_FEATURES: ["res2"]
PROJECT_CHANNELS: [48]
NORM: "SyncBN"
COMMON_STRIDE: 4
INPUT:
FORMAT: "RGB"
[32m[03/07 21:38:48 detectron2]: [0mRunning with full config:
CUDNN_BENCHMARK: False
DATALOADER:
ASPECT_RATIO_GROUPING: True
FILTER_EMPTY_ANNOTATIONS: True
NUM_WORKERS: 10
REPEAT_THRESHOLD: 0.0
SAMPLER_TRAIN: TrainingSampler
DATASETS:
PRECOMPUTED_PROPOSAL_TOPK_TEST: 1000
PRECOMPUTED_PROPOSAL_TOPK_TRAIN: 2000
PROPOSAL_FILES_TEST: ()
PROPOSAL_FILES_TRAIN: ()
TEST: ('xbddata_test',)
TRAIN: ('xbddata_train',)
GLOBAL:
HACK: 1.0
INPUT:
CROP:
ENABLED: True
SINGLE_CATEGORY_MAX_AREA: 1.0
SIZE: [512, 1024]
TYPE: absolute
FORMAT: RGB
MASK_FORMAT: polygon
MAX_SIZE_TEST: 1024
MAX_SIZE_TRAIN: 1024
MIN_SIZE_TEST: 1024
MIN_SIZE_TRAIN: (1024,)
MIN_SIZE_TRAIN_SAMPLING: choice
RANDOM_FLIP: horizontal
MODEL:
ANCHOR_GENERATOR:
ANGLES: [[-90, 0, 90]]
ASPECT_RATIOS: [[0.5, 1.0, 2.0]]
NAME: DefaultAnchorGenerator
OFFSET: 0.0
SIZES: [[32, 64, 128, 256, 512]]
BACKBONE:
FREEZE_AT: 0
NAME: build_resnet_deeplab_backbone
DEVICE: cuda
FPN:
FUSE_TYPE: sum
IN_FEATURES: []
NORM:
OUT_CHANNELS: 256
KEYPOINT_ON: False
LOAD_PROPOSALS: False
MASK_ON: False
META_ARCHITECTURE: SemanticSegmentor
PANOPTIC_FPN:
COMBINE:
ENABLED: True
INSTANCES_CONFIDENCE_THRESH: 0.5
OVERLAP_THRESH: 0.5
STUFF_AREA_LIMIT: 4096
INSTANCE_LOSS_WEIGHT: 1.0
PIXEL_MEAN: [123.675, 116.28, 103.53]
PIXEL_STD: [58.395, 57.12, 57.375]
PROPOSAL_GENERATOR:
MIN_SIZE: 0
NAME: RPN
RESNETS:
DEFORM_MODULATED: False
DEFORM_NUM_GROUPS: 1
DEFORM_ON_PER_STAGE: [False, False, False, False]
DEPTH: 101
NORM: SyncBN
NUM_GROUPS: 1
OUT_FEATURES: ['res2', 'res5']
RES2_OUT_CHANNELS: 256
RES4_DILATION: 1
RES5_DILATION: 2
RES5_MULTI_GRID: [1, 2, 4]
STEM_OUT_CHANNELS: 128
STEM_TYPE: deeplab
STRIDE_IN_1X1: False
WIDTH_PER_GROUP: 64
RETINANET:
BBOX_REG_LOSS_TYPE: smooth_l1
BBOX_REG_WEIGHTS: (1.0, 1.0, 1.0, 1.0)
FOCAL_LOSS_ALPHA: 0.25
FOCAL_LOSS_GAMMA: 2.0
IN_FEATURES: ['p3', 'p4', 'p5', 'p6', 'p7']
IOU_LABELS: [0, -1, 1]
IOU_THRESHOLDS: [0.4, 0.5]
NMS_THRESH_TEST: 0.5
NORM:
NUM_CLASSES: 80
NUM_CONVS: 4
PRIOR_PROB: 0.01
SCORE_THRESH_TEST: 0.05
SMOOTH_L1_LOSS_BETA: 0.1
TOPK_CANDIDATES_TEST: 1000
ROI_BOX_CASCADE_HEAD:
BBOX_REG_WEIGHTS: ((10.0, 10.0, 5.0, 5.0), (20.0, 20.0, 10.0, 10.0), (30.0, 30.0, 15.0, 15.0))
IOUS: (0.5, 0.6, 0.7)
ROI_BOX_HEAD:
BBOX_REG_LOSS_TYPE: smooth_l1
BBOX_REG_LOSS_WEIGHT: 1.0
BBOX_REG_WEIGHTS: (10.0, 10.0, 5.0, 5.0)
CLS_AGNOSTIC_BBOX_REG: False
CONV_DIM: 256
FC_DIM: 1024
NAME: FastRCNNConvFCHead
NORM:
NUM_CONV: 0
NUM_FC: 2
POOLER_RESOLUTION: 7
POOLER_SAMPLING_RATIO: 0
POOLER_TYPE: ROIAlignV2
SMOOTH_L1_BETA: 0.0
TRAIN_ON_PRED_BOXES: False
ROI_HEADS:
BATCH_SIZE_PER_IMAGE: 512
IN_FEATURES: ['res5']
IOU_LABELS: [0, 1]
IOU_THRESHOLDS: [0.5]
NAME: StandardROIHeads
NMS_THRESH_TEST: 0.5
NUM_CLASSES: 80
POSITIVE_FRACTION: 0.25
PROPOSAL_APPEND_GT: True
SCORE_THRESH_TEST: 0.05
ROI_KEYPOINT_HEAD:
CONV_DIMS: (512, 512, 512, 512, 512, 512, 512, 512)
LOSS_WEIGHT: 1.0
MIN_KEYPOINTS_PER_IMAGE: 1
NAME: KRCNNConvDeconvUpsampleHead
NORMALIZE_LOSS_BY_VISIBLE_KEYPOINTS: True
NUM_KEYPOINTS: 17
POOLER_RESOLUTION: 14
POOLER_SAMPLING_RATIO: 0
POOLER_TYPE: ROIAlignV2
ROI_MASK_HEAD:
CLS_AGNOSTIC_MASK: False
CONV_DIM: 256
NAME: MaskRCNNConvUpsampleHead
NORM:
NUM_CONV: 4
POOLER_RESOLUTION: 14
POOLER_SAMPLING_RATIO: 0
POOLER_TYPE: ROIAlignV2
RPN:
BATCH_SIZE_PER_IMAGE: 256
BBOX_REG_LOSS_TYPE: smooth_l1
BBOX_REG_LOSS_WEIGHT: 1.0
BBOX_REG_WEIGHTS: (1.0, 1.0, 1.0, 1.0)
BOUNDARY_THRESH: -1
HEAD_NAME: StandardRPNHead
IN_FEATURES: ['res5']
IOU_LABELS: [0, -1, 1]
IOU_THRESHOLDS: [0.3, 0.7]
LOSS_WEIGHT: 1.0
NMS_THRESH: 0.7
POSITIVE_FRACTION: 0.5
POST_NMS_TOPK_TEST: 1000
POST_NMS_TOPK_TRAIN: 2000
PRE_NMS_TOPK_TEST: 6000
PRE_NMS_TOPK_TRAIN: 12000
SMOOTH_L1_BETA: 0.0
SEM_SEG_HEAD:
ASPP_CHANNELS: 256
ASPP_DILATIONS: [6, 12, 18]
ASPP_DROPOUT: 0.1
COMMON_STRIDE: 4
CONVS_DIM: 256
IGNORE_VALUE: 255
IN_FEATURES: ['res2', 'res5']
LOSS_TYPE: hard_pixel_mining
LOSS_WEIGHT: 1.0
NAME: DeepLabV3PlusHead
NORM: SyncBN
NUM_CLASSES: 3
PROJECT_CHANNELS: [48]
PROJECT_FEATURES: ['res2']
USE_DEPTHWISE_SEPARABLE_CONV: False
WEIGHTS: ./output/model_0024999.pth
OUTPUT_DIR: ./output
SEED: -1
SOLVER:
AMP:
ENABLED: False
BASE_LR: 0.01
BIAS_LR_FACTOR: 1.0
CHECKPOINT_PERIOD: 5000
CLIP_GRADIENTS:
CLIP_TYPE: value
CLIP_VALUE: 1.0
ENABLED: False
NORM_TYPE: 2.0
GAMMA: 0.1
IMS_PER_BATCH: 16
LR_SCHEDULER_NAME: WarmupPolyLR
MAX_ITER: 90000
MOMENTUM: 0.9
NESTEROV: False
POLY_LR_CONSTANT_ENDING: 0.0
POLY_LR_POWER: 0.9
REFERENCE_WORLD_SIZE: 0
STEPS: (60000, 80000)
WARMUP_FACTOR: 0.001
WARMUP_ITERS: 1000
WARMUP_METHOD: linear
WEIGHT_DECAY: 0.0001
WEIGHT_DECAY_BIAS: 0.0001
WEIGHT_DECAY_NORM: 0.0
TEST:
AUG:
ENABLED: False
FLIP: True
MAX_SIZE: 4000
MIN_SIZES: (400, 500, 600, 700, 800, 900, 1000, 1100, 1200)
DETECTIONS_PER_IMAGE: 100
EVAL_PERIOD: 0
EXPECTED_RESULTS: []
KEYPOINT_OKS_SIGMAS: []
PRECISE_BN:
ENABLED: False
NUM_ITER: 200
VERSION: 2
VIS_PERIOD: 0
[32m[03/07 21:38:48 detectron2]: [0mFull config saved to ./output/config.yaml
[32m[03/07 21:38:48 d2.utils.env]: [0mUsing a generated random seed 48437111
cfg.MODEL.WEIGHTS ./output/model_0024999.pth
cfg.OUTPUT_DIR ./output
[32m[03/07 21:38:52 fvcore.common.checkpoint]: [0mLoading checkpoint from ./output/model_0024999.pth
[5m[31mWARNING[0m [32m[03/07 21:38:52 fvcore.common.checkpoint]: [0mSkip loading parameter 'sem_seg_head.predictor.weight' to the model due to incompatible shapes: (19, 256, 1, 1) in the checkpoint but (3, 256, 1, 1) in the model! You might want to double check if this is expected.
[5m[31mWARNING[0m [32m[03/07 21:38:52 fvcore.common.checkpoint]: [0mSkip loading parameter 'sem_seg_head.predictor.bias' to the model due to incompatible shapes: (19,) in the checkpoint but (3,) in the model! You might want to double check if this is expected.
[32m[03/07 21:38:52 fvcore.common.checkpoint]: [0mSome model parameters or buffers are not found in the checkpoint:
[34msem_seg_head.predictor.{bias, weight}[0m
[32m[03/07 21:38:53 d2.data.dataset_mapper]: [0m[DatasetMapper] Augmentations used in inference: [ResizeShortestEdge(short_edge_length=(1024, 1024), max_size=1024, sample_style='choice')]
[32m[03/07 21:38:53 d2.data.common]: [0mSerializing 933 elements to byte tensors and concatenating them all ...
[32m[03/07 21:38:53 d2.data.common]: [0mSerialized dataset takes 0.23 MiB
datasetname xbddata_test
[5m[31mWARNING[0m [32m[03/07 21:38:53 d2.evaluation.sem_seg_evaluation]: [0mSemSegEvaluator(num_classes) is deprecated! It should be obtained from metadata.
[5m[31mWARNING[0m [32m[03/07 21:38:53 d2.evaluation.sem_seg_evaluation]: [0mSemSegEvaluator(ignore_label) is deprecated! It should be obtained from metadata.
[32m[03/07 21:38:54 d2.evaluation.evaluator]: [0mStart inference on 933 images
[32m[03/07 21:38:56 d2.evaluation.evaluator]: [0mInference done 11/933. 0.0817 s / img. ETA=0:01:55
[32m[03/07 21:39:01 d2.evaluation.evaluator]: [0mInference done 51/933. 0.0817 s / img. ETA=0:01:50
[32m[03/07 21:39:06 d2.evaluation.evaluator]: [0mInference done 70/933. 0.0817 s / img. ETA=0:02:26
[32m[03/07 21:39:11 d2.evaluation.evaluator]: [0mInference done 110/933. 0.0818 s / img. ETA=0:02:06
[32m[03/07 21:39:17 d2.evaluation.evaluator]: [0mInference done 150/933. 0.0818 s / img. ETA=0:01:54
[32m[03/07 21:39:22 d2.evaluation.evaluator]: [0mInference done 190/933. 0.0819 s / img. ETA=0:01:45
[32m[03/07 21:39:27 d2.evaluation.evaluator]: [0mInference done 229/933. 0.0820 s / img. ETA=0:01:38
[32m[03/07 21:39:32 d2.evaluation.evaluator]: [0mInference done 270/933. 0.0820 s / img. ETA=0:01:30
[32m[03/07 21:39:37 d2.evaluation.evaluator]: [0mInference done 310/933. 0.0819 s / img. ETA=0:01:24
[32m[03/07 21:39:42 d2.evaluation.evaluator]: [0mInference done 351/933. 0.0819 s / img. ETA=0:01:18
[32m[03/07 21:39:47 d2.evaluation.evaluator]: [0mInference done 391/933. 0.0819 s / img. ETA=0:01:12
[32m[03/07 21:39:52 d2.evaluation.evaluator]: [0mInference done 432/933. 0.0819 s / img. ETA=0:01:06
[32m[03/07 21:39:57 d2.evaluation.evaluator]: [0mInference done 473/933. 0.0819 s / img. ETA=0:01:00
[32m[03/07 21:40:02 d2.evaluation.evaluator]: [0mInference done 514/933. 0.0819 s / img. ETA=0:00:54
[32m[03/07 21:40:07 d2.evaluation.evaluator]: [0mInference done 554/933. 0.0818 s / img. ETA=0:00:49
[32m[03/07 21:40:12 d2.evaluation.evaluator]: [0mInference done 595/933. 0.0818 s / img. ETA=0:00:44
[32m[03/07 21:40:17 d2.evaluation.evaluator]: [0mInference done 636/933. 0.0818 s / img. ETA=0:00:38
[32m[03/07 21:40:23 d2.evaluation.evaluator]: [0mInference done 677/933. 0.0818 s / img. ETA=0:00:33
[32m[03/07 21:40:28 d2.evaluation.evaluator]: [0mInference done 717/933. 0.0818 s / img. ETA=0:00:27
[32m[03/07 21:40:33 d2.evaluation.evaluator]: [0mInference done 758/933. 0.0818 s / img. ETA=0:00:22
[32m[03/07 21:40:38 d2.evaluation.evaluator]: [0mInference done 799/933. 0.0818 s / img. ETA=0:00:17
[32m[03/07 21:40:43 d2.evaluation.evaluator]: [0mInference done 840/933. 0.0818 s / img. ETA=0:00:11
[32m[03/07 21:40:48 d2.evaluation.evaluator]: [0mInference done 881/933. 0.0818 s / img. ETA=0:00:06
[32m[03/07 21:40:53 d2.evaluation.evaluator]: [0mInference done 922/933. 0.0818 s / img. ETA=0:00:01
[32m[03/07 21:40:54 d2.evaluation.evaluator]: [0mTotal inference time: 0:01:59.094921 (0.128335 s / img per device, on 1 devices)
[32m[03/07 21:40:54 d2.evaluation.evaluator]: [0mTotal inference pure compute time: 0:01:15 (0.081782 s / img per device, on 1 devices)
[32m[03/07 21:40:56 d2.evaluation.sem_seg_evaluation]: [0mOrderedDict([('sem_seg', {'mIoU': 14.286231780375028, 'fwIoU': 30.412502468859948, 'IoU-0': 31.958253593820217, 'IoU-1': 5.555678249276511, 'IoU-2': 5.344763498028353, 'mACC': 53.518182755044954, 'pACC': 34.17634953767668, 'ACC-0': 32.13264257356594, 'ACC-1': 69.63928432518483, 'ACC-2': 58.78262136638409})])
[32m[03/07 21:40:56 d2.engine.defaults]: [0mEvaluation results for xbddata_test in csv format:
[32m[03/07 21:40:56 d2.evaluation.testing]: [0mcopypaste: Task: sem_seg
[32m[03/07 21:40:56 d2.evaluation.testing]: [0mcopypaste: mIoU,fwIoU,mACC,pACC
[32m[03/07 21:40:56 d2.evaluation.testing]: [0mcopypaste: 14.2862,30.4125,53.5182,34.1763
About this issue
- Original URL
- State: open
- Created 3 years ago
- Comments: 15 (4 by maintainers)
Hi everyone, this is the code that works for me (for DeepLab inference). This can be used for running deep lab on a webcam:
I had the following solution. It works for my custom dataset in which my background correspond with an output of ‘0’. For the cityscapes every class works, except for the background class. Of course it is also possible to write a custom drawing function since the output is already an integer.
values2, outputs2 = torch.max(F.softmax(outputs,dim=0),axis=0)out = v.draw_sem_seg(outputs2.to("cpu"))