Vitis-AI: DPUCADF8H fails for U200 compilation (U280 DPUCAHX8H works fine)
I am trying to compile a model for my U200 card. The model compiles fine for U280 cards using the following command. However, once I compile for U200 with ``DPUCADF8H``` I get a compilation error. I am not entirely sure how to debug this since the error message is quite obscure.
U280 command:
vai_c_tensorflow --frozen_pb="./quantize/quantize_eval_model.pb" --arch /opt/vitis_ai/compiler/arch/DPUCAHX8H/U280/arch.json --output_dir="compile" --options="{'mode':'normal'}" --net_name "point_pillars"
Output for the U280 compilation:
[INFO] parse raw model : 0%| | 0/50 [00:00<?, ?it/s]
[INFO] parse raw model :100%|██████████| 50/50 [00:00<00:00, 30122.84it/s]
[INFO] infer shape (NHWC) : 0%| | 0/50 [00:00<?, ?it/s]
[INFO] infer shape (NHWC) :100%|██████████| 50/50 [00:00<00:00, 77557.40it/s]
[INFO] infer shape (NHWC) : 0%| | 0/50 [00:00<?, ?it/s]
[INFO] infer shape (NHWC) :100%|██████████| 50/50 [00:00<00:00, 19647.29it/s]
[INFO] generate xmodel : 0%| | 0/50 [00:00<?, ?it/s]
[INFO] generate xmodel :100%|██████████| 50/50 [00:00<00:00, 5912.80it/s]
[INFO] Namespace(inputs_shape=None, layout='NHWC', model_files=['./quantize/quantize_eval_model.pb'], model_type='tensorflow', out_filename='compile/point_pillars_org.xmodel', proto=None)
[INFO] tensorflow model: quantize/quantize_eval_model.pb
[INFO] generate xmodel: /workspace/pointpillars/PointPillars/compile/point_pillars_org.xmodel
[UNILOG][INFO] The compiler log will be dumped at "/tmp/vitis-ai-user/log/xcompiler-20210804-204732-1522"
[UNILOG][INFO] Target architecture: DPUCAHX8H_ISA2
[UNILOG][INFO] Compile mode: dpu
[UNILOG][INFO] Debug mode: function
[UNILOG][INFO] Target architecture: DPUCAHX8H_ISA2
[UNILOG][INFO] Graph name: quantize_eval_model, with op num: 112
[UNILOG][INFO] Begin to compile...
[UNILOG][INFO] Total device subgraph number 3, DPU subgraph number 1
[UNILOG][INFO] Compile done.
[UNILOG][INFO] The meta json is saved to "/workspace/pointpillars/PointPillars/compile/meta.json"
[UNILOG][INFO] The compiled xmodel is saved to "/workspace/pointpillars/PointPillars/compile/point_pillars.xmodel"
[UNILOG][INFO] The compiled xmodel's md5sum is 14b5bfcf55373890fd88a573f8183b83, and been saved to "/workspace/pointpillars/PointPillars/compile/md5sum.txt"
**************************************************
* VITIS_AI Compilation - Xilinx Inc.
**************************************************
U200 command:
vai_c_tensorflow --frozen_pb="./quantize/quantize_eval_model.pb" --arch /opt/vitis_ai/compiler/arch/DPUCADF8H/U200/arch.json --output_dir="compile" --options="{'mode':'normal'}" --net_name "point_pillars"
Output for U200 compilation:
[INFO] parse raw model : 0%| | 0/50 [00:00<?, ?it/s]
[INFO] parse raw model :100%|██████████| 50/50 [00:00<00:00, 30305.66it/s]
[INFO] infer shape (NHWC) : 0%| | 0/50 [00:00<?, ?it/s]
[INFO] infer shape (NHWC) :100%|██████████| 50/50 [00:00<00:00, 76260.07it/s]
[INFO] infer shape (NHWC) : 0%| | 0/50 [00:00<?, ?it/s]
[INFO] infer shape (NHWC) :100%|██████████| 50/50 [00:00<00:00, 19734.19it/s]
[INFO] generate xmodel : 0%| | 0/50 [00:00<?, ?it/s]
[INFO] generate xmodel :100%|██████████| 50/50 [00:00<00:00, 5916.64it/s]
[INFO] Namespace(inputs_shape=None, layout='NHWC', model_files=['./quantize/quantize_eval_model.pb'], model_type='tensorflow', out_filename='compile/point_pillars_org.xmodel', proto=None)
[INFO] tensorflow model: quantize/quantize_eval_model.pb
[INFO] generate xmodel: /workspace/pointpillars/PointPillars/compile/point_pillars_org.xmodel
[UNILOG][INFO] The compiler log will be dumped at "/tmp/vitis-ai-user/log/xcompiler-20210804-204254-1470"
[UNILOG][INFO] [32mCompiling subgraph : subgraph_cnn/block1/conv2d0/Conv2D[0m
#############################################
###### Hyper Graph Construction
#############################################
#############################################
###### Hyper Graph Construction
#############################################
Floyd & Warshall
BFS
#############################################
###### Parameters Assimilation: # 47
#############################################
#############################################
###### Assimilating Fix Neurons: # 16
#############################################
#############################################
###### Assimilating Relu: # 16
#############################################
#############################################
###### Assimilating LeakyRelu: # 0
#############################################
#############################################
###### I like VALID more than SAME
#############################################
cnn/block1/conv2d0/Conv2D SAME [0, 0, 0, 0]
cnn/block1/conv2d1/Conv2D SAME [0, 0, 0, 0]
cnn/block1/conv2d2/Conv2D SAME [0, 0, 0, 0]
cnn/block1/conv2d3/Conv2D SAME [0, 0, 0, 0]
cnn/block2/conv2d0/Conv2D SAME [0, 0, 0, 0]
cnn/block2/conv2d1/Conv2D SAME [0, 0, 0, 0]
cnn/block2/conv2d2/Conv2D SAME [0, 0, 0, 0]
cnn/block2/conv2d3/Conv2D SAME [0, 0, 0, 0]
cnn/block2/conv2d4/Conv2D SAME [0, 0, 0, 0]
cnn/block2/conv2d5/Conv2D SAME [0, 0, 0, 0]
cnn/block3/conv2d0/Conv2D SAME [0, 0, 0, 0]
cnn/block3/conv2d1/Conv2D SAME [0, 0, 0, 0]
cnn/block3/conv2d2/Conv2D SAME [0, 0, 0, 0]
cnn/block3/conv2d3/Conv2D SAME [0, 0, 0, 0]
cnn/block3/conv2d4/Conv2D SAME [0, 0, 0, 0]
cnn/block3/conv2d5/Conv2D SAME [0, 0, 0, 0]
#############################################
###### I like VALID more than SAME: # 16
#############################################
#############################################
###### Assimilating Padding:# 0
#############################################
#############################################
###### CPU nodes Must Go
#############################################
Inputs ['input_1/aquant']
Outputs ['cnn/block3/conv2d5/Conv2D']
FPGA True: data input_1/aquant
FPGA True: conv2d cnn/block1/conv2d0/Conv2D
FPGA True: conv2d cnn/block1/conv2d1/Conv2D
FPGA True: conv2d cnn/block1/conv2d2/Conv2D
FPGA True: conv2d cnn/block1/conv2d3/Conv2D
FPGA True: conv2d cnn/block2/conv2d0/Conv2D
FPGA True: conv2d cnn/block2/conv2d1/Conv2D
FPGA True: conv2d cnn/block2/conv2d2/Conv2D
FPGA True: conv2d cnn/block2/conv2d3/Conv2D
FPGA True: conv2d cnn/block2/conv2d4/Conv2D
FPGA True: conv2d cnn/block2/conv2d5/Conv2D
FPGA True: conv2d cnn/block3/conv2d0/Conv2D
FPGA True: conv2d cnn/block3/conv2d1/Conv2D
FPGA True: conv2d cnn/block3/conv2d2/Conv2D
FPGA True: conv2d cnn/block3/conv2d3/Conv2D
FPGA True: conv2d cnn/block3/conv2d4/Conv2D
FPGA True: conv2d cnn/block3/conv2d5/Conv2D
delete these dict_keys(['input_1/aquant'])
{'cnn/block3/conv2d5/Conv2D': Name cnn/block3/conv2d5/Conv2D Type conv2d Composed [] Inputs ['cnn/block3/conv2d4/Conv2D']
}
Schedule boost
0 data input_1/aquant False 1
1 conv2d cnn/block1/conv2d0/Conv2D True 1
2 conv2d cnn/block1/conv2d1/Conv2D True 1
3 conv2d cnn/block1/conv2d2/Conv2D True 1
4 conv2d cnn/block1/conv2d3/Conv2D True 1
5 conv2d cnn/block2/conv2d0/Conv2D True 1
6 conv2d cnn/block2/conv2d1/Conv2D True 1
7 conv2d cnn/block2/conv2d2/Conv2D True 1
8 conv2d cnn/block2/conv2d3/Conv2D True 1
9 conv2d cnn/block2/conv2d4/Conv2D True 1
10 conv2d cnn/block2/conv2d5/Conv2D True 1
11 conv2d cnn/block3/conv2d0/Conv2D True 1
12 conv2d cnn/block3/conv2d1/Conv2D True 1
13 conv2d cnn/block3/conv2d2/Conv2D True 1
14 conv2d cnn/block3/conv2d3/Conv2D True 1
15 conv2d cnn/block3/conv2d4/Conv2D True 1
16 conv2d cnn/block3/conv2d5/Conv2D True 1
Outputs ['cnn/block3/conv2d5/Conv2D']
Inputs ['input_1/aquant']
Floyd & Warshall
BFS
#############################################
###### Avg Pool -> Conv
#############################################
#############################################
###### Inner Products -> Conv
#############################################
#############################################
###### Scale -> Conv
#############################################
#############################################
###### Concat of concat
#############################################
Floyd & Warshall
BFS
#############################################
###### topological schedule BFS
#############################################
#############################################
###### WEIGHT & BIAS into Tensors
#############################################
#############################################
###### DRU
#############################################
#############################################
###### Conv + Pool -> single
#############################################
#############################################
###### Conv + Elt -> Elt
#############################################
#############################################
###### topological DFS
#############################################
DFS_t input_1/aquant
#############################################
###### TFS
#############################################
#############################################
###### INC
#############################################
INC
#############################################
###### Singleton
#############################################
0 data input_1/aquant Ops 0 Shape [1, 504, 504, 64] IN [] OUT ['cnn/block1/conv2d0/Conv2D']
1 conv2d cnn/block1/conv2d0/Conv2D Ops 2341011456 Shape [1, 252, 252, 64] IN ['input_1/aquant'] OUT ['cnn/block1/conv2d1/Conv2D']
2 conv2d cnn/block1/conv2d1/Conv2D Ops 2341011456 Shape [1, 252, 252, 64] IN ['cnn/block1/conv2d0/Conv2D'] OUT ['cnn/block1/conv2d2/Conv2D']
3 conv2d cnn/block1/conv2d2/Conv2D Ops 2341011456 Shape [1, 252, 252, 64] IN ['cnn/block1/conv2d1/Conv2D'] OUT ['cnn/block1/conv2d3/Conv2D']
4 conv2d cnn/block1/conv2d3/Conv2D Ops 2341011456 Shape [1, 252, 252, 64] IN ['cnn/block1/conv2d2/Conv2D'] OUT ['cnn/block2/conv2d0/Conv2D']
5 conv2d cnn/block2/conv2d0/Conv2D Ops 1170505728 Shape [1, 126, 126, 128] IN ['cnn/block1/conv2d3/Conv2D'] OUT ['cnn/block2/conv2d1/Conv2D']
6 conv2d cnn/block2/conv2d1/Conv2D Ops 2341011456 Shape [1, 126, 126, 128] IN ['cnn/block2/conv2d0/Conv2D'] OUT ['cnn/block2/conv2d2/Conv2D']
7 conv2d cnn/block2/conv2d2/Conv2D Ops 2341011456 Shape [1, 126, 126, 128] IN ['cnn/block2/conv2d1/Conv2D'] OUT ['cnn/block2/conv2d3/Conv2D']
8 conv2d cnn/block2/conv2d3/Conv2D Ops 2341011456 Shape [1, 126, 126, 128] IN ['cnn/block2/conv2d2/Conv2D'] OUT ['cnn/block2/conv2d4/Conv2D']
9 conv2d cnn/block2/conv2d4/Conv2D Ops 2341011456 Shape [1, 126, 126, 128] IN ['cnn/block2/conv2d3/Conv2D'] OUT ['cnn/block2/conv2d5/Conv2D']
10 conv2d cnn/block2/conv2d5/Conv2D Ops 2341011456 Shape [1, 126, 126, 128] IN ['cnn/block2/conv2d4/Conv2D'] OUT ['cnn/block3/conv2d0/Conv2D']
11 conv2d cnn/block3/conv2d0/Conv2D Ops 585252864 Shape [1, 63, 63, 128] IN ['cnn/block2/conv2d5/Conv2D'] OUT ['cnn/block3/conv2d1/Conv2D']
12 conv2d cnn/block3/conv2d1/Conv2D Ops 585252864 Shape [1, 63, 63, 128] IN ['cnn/block3/conv2d0/Conv2D'] OUT ['cnn/block3/conv2d2/Conv2D']
13 conv2d cnn/block3/conv2d2/Conv2D Ops 585252864 Shape [1, 63, 63, 128] IN ['cnn/block3/conv2d1/Conv2D'] OUT ['cnn/block3/conv2d3/Conv2D']
14 conv2d cnn/block3/conv2d3/Conv2D Ops 585252864 Shape [1, 63, 63, 128] IN ['cnn/block3/conv2d2/Conv2D'] OUT ['cnn/block3/conv2d4/Conv2D']
15 conv2d cnn/block3/conv2d4/Conv2D Ops 585252864 Shape [1, 63, 63, 128] IN ['cnn/block3/conv2d3/Conv2D'] OUT ['cnn/block3/conv2d5/Conv2D']
16 conv2d cnn/block3/conv2d5/Conv2D Ops 585252864 Shape [1, 63, 63, 128] IN ['cnn/block3/conv2d4/Conv2D'] OUT []
#############################################
###### Pool + ConvPool -> single
#############################################
#############################################
###### Given a Graph and Schedule boost : We crete Live Tensor
#############################################
#############################################
###### Reset Live Structure
#############################################
#############################################
###### Attempting Code Generation boost
#############################################
#############################################
###### Element Wise: reuse one of the operands
#############################################
#############################################
###### Concatenation: I love concatenation memory reuse
#############################################
#############################################
###### Memory Management given a Schedule
#############################################
Step input_1/aquant
Step input_1/aquant is an input
WARNING input_1/aquant data WARNING
Step cnn/block1/conv2d0/Conv2D
Memory access IN ddr PAR pa TMP fm OUT ddr cnn/block1/conv2d0/Conv2D
Step cnn/block1/conv2d1/Conv2D
Memory access IN ddr PAR pa TMP fm OUT ddr cnn/block1/conv2d1/Conv2D
Step cnn/block1/conv2d2/Conv2D
Memory access IN ddr PAR pa TMP fm OUT ddr cnn/block1/conv2d2/Conv2D
Step cnn/block1/conv2d3/Conv2D
Memory access IN ddr PAR pa TMP fm OUT ddr cnn/block1/conv2d3/Conv2D
Step cnn/block2/conv2d0/Conv2D
Memory access IN ddr PAR pa TMP fm OUT ddr cnn/block2/conv2d0/Conv2D
Step cnn/block2/conv2d1/Conv2D
Memory access IN ddr PAR pa TMP fm OUT ddr cnn/block2/conv2d1/Conv2D
Step cnn/block2/conv2d2/Conv2D
Memory access IN ddr PAR pa TMP fm OUT ddr cnn/block2/conv2d2/Conv2D
Step cnn/block2/conv2d3/Conv2D
Memory access IN ddr PAR pa TMP fm OUT ddr cnn/block2/conv2d3/Conv2D
Step cnn/block2/conv2d4/Conv2D
Memory access IN ddr PAR pa TMP fm OUT ddr cnn/block2/conv2d4/Conv2D
Step cnn/block2/conv2d5/Conv2D
Memory access IN ddr PAR pa TMP fm OUT ddr cnn/block2/conv2d5/Conv2D
Step cnn/block3/conv2d0/Conv2D
Memory access IN ddr PAR pa TMP fm OUT fm cnn/block3/conv2d0/Conv2D
Step cnn/block3/conv2d1/Conv2D
Memory access IN fm PAR pa TMP fm OUT fm cnn/block3/conv2d1/Conv2D
Step cnn/block3/conv2d2/Conv2D
Memory access IN fm PAR pa TMP fm OUT fm cnn/block3/conv2d2/Conv2D
Step cnn/block3/conv2d3/Conv2D
Memory access IN fm PAR pa TMP fm OUT fm cnn/block3/conv2d3/Conv2D
Step cnn/block3/conv2d4/Conv2D
Memory access IN fm PAR pa TMP fm OUT fm cnn/block3/conv2d4/Conv2D
Step cnn/block3/conv2d5/Conv2D
Memory access IN fm PAR pa TMP fm OUT ddr cnn/block3/conv2d5/Conv2D
#############################################
###### Naive instruction dependency
#############################################
#############################################
###### Code Generation at Node Level and then Recursively
#############################################
Dependency ON 0 0 CUR 0 BY 0
1 19 <class 'SC.HwAbstraction.code_convreshape.ConvInPlaceChangeLayout'> False
1 19 input_1/aquant ON 0 CUR 0 BY 1
2 19 <class 'SC.HwAbstraction.code_convolution.Conv'> False
2 19 cnn/block1/conv2d0/Conv2D ON 0 CUR 4 BY 1
3 19 <class 'SC.HwAbstraction.code_convolution.Conv'> False
3 19 cnn/block1/conv2d1/Conv2D ON 2 CUR 4 BY 1
4 19 <class 'SC.HwAbstraction.code_convolution.Conv'> False
4 19 cnn/block1/conv2d2/Conv2D ON 2 CUR 4 BY 1
5 19 <class 'SC.HwAbstraction.code_convreshape.ConvInPlaceChangeLayout'> False
5 19 cnn/block1/conv2d3/Conv2D ON 2 CUR 4 BY 1
6 19 <class 'SC.HwAbstraction.code_convolution.Conv'> False
6 19 cnn/block2/conv2d0/Conv2D ON 2 CUR 4 BY 1
7 19 <class 'SC.HwAbstraction.code_convolution.Conv'> False
7 19 cnn/block2/conv2d1/Conv2D ON 2 CUR 4 BY 1
8 19 <class 'SC.HwAbstraction.code_convolution.Conv'> False
8 19 cnn/block2/conv2d2/Conv2D ON 2 CUR 4 BY 1
9 19 <class 'SC.HwAbstraction.code_convolution.Conv'> False
9 19 cnn/block2/conv2d3/Conv2D ON 2 CUR 4 BY 1
10 19 <class 'SC.HwAbstraction.code_convolution.Conv'> False
10 19 cnn/block2/conv2d4/Conv2D ON 2 CUR 4 BY 1
11 19 <class 'SC.HwAbstraction.code_convreshape.ConvInPlaceChangeLayout'> False
11 19 cnn/block2/conv2d5/Conv2D ON 2 CUR 4 BY 1
12 19 <class 'SC.HwAbstraction.code_convolution.Conv'> False
12 19 cnn/block3/conv2d0/Conv2D ON 2 CUR 4 BY 1
13 19 <class 'SC.HwAbstraction.code_convolution.Conv'> False
13 19 cnn/block3/conv2d1/Conv2D ON 4 CUR 4 BY 5
14 19 <class 'SC.HwAbstraction.code_convolution.Conv'> False
14 19 cnn/block3/conv2d2/Conv2D ON 4 CUR 4 BY 5
15 19 <class 'SC.HwAbstraction.code_convolution.Conv'> False
15 19 cnn/block3/conv2d3/Conv2D ON 4 CUR 4 BY 5
16 19 <class 'SC.HwAbstraction.code_convolution.Conv'> False
16 19 cnn/block3/conv2d4/Conv2D ON 4 CUR 4 BY 4
17 19 <class 'SC.HwAbstraction.code_end.Bracket_End'> False
17 19 cnn/block3/conv2d5/Conv2D ON 4 CUR 4 BY 2
18 19 bracket ON 2 CUR 2 BY 0
#############################################
###### Code Generation at Node Level and then Recursively
#############################################
CODE cnn/block1/conv2d0/Conv2D conv2d
BATCH IN Shape [1, 504, 504, 64] Heights [15, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 13]
BATCH OUT Shape [1, 252, 252, 64] Heights [7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7]
'NoneType' object has no attribute 'tensor'
> /opt/vitis_ai/conda/envs/vitis-ai-tensorflow/lib/python3.6/site-packages/SC/HwAbstraction/code_generation.py(458)my_simplified_code()
-> CCode.extend(c.code_generation(dbon,dbby) )
(Pdb)
About this issue
- Original URL
- State: closed
- Created 3 years ago
- Comments: 27 (1 by maintainers)
@BraunPhilipp The good news is that the future deployment the default batch does not matter (we should be able to manage batch =1). There should be documentation for the model zoo and batch= 4 but I am not sure (sorry). The compiler for 1.4 takes a hardline approach and refuses to compile for batch !=4.
Transpose convolution = deconvolution is supported. if you have any problem, please create an issue here and add in the comment me @paolodalberto so I get a notification and can follow up with you
Thank you @woinck
Could you share the code you used for compiling U200 models? To enable batchsize 4 compilation, please try adding a
input_shapeflag to the vai_c_tensorflow options like this:vai_c_tensorflow --frozen_pb="./quantize/quantize_eval_model.pb" --arch /opt/vitis_ai/compiler/arch/DPUCADF8H/U200/arch.json --output_dir="compile" --options="{'mode':'normal', 'input_shape': '4,224,224,3'}" --net_name "point_pillars"(replace the 224x224 input shape with your model’s input shape)the flow looks good: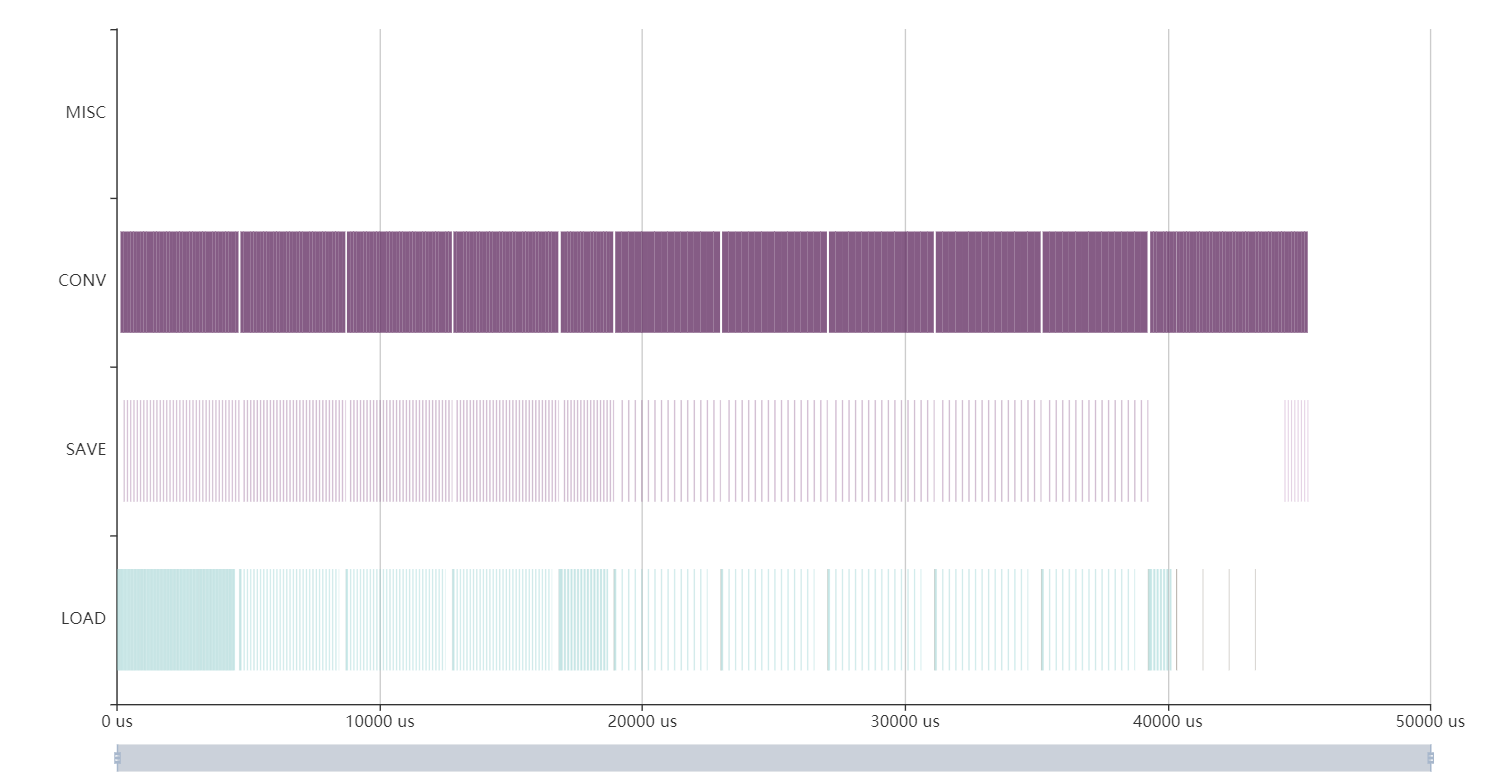
the good news is that 1.4 does better. let me see if I can retrieve and compile your model today