VictoriaMetrics: vminsert: issues of reroute mechanism when storage node is temporarily unavailable
Describe the bug Once one(some) of the storage node(s) get killed, our vm cluster will lose the ability to ingest data into storage, and it is hard to recover if we don’t get involved. The behaviour is:
-
high rerouted_from rate, not only from the down nodes, but also some other healthy nodes(basically all the nodes)
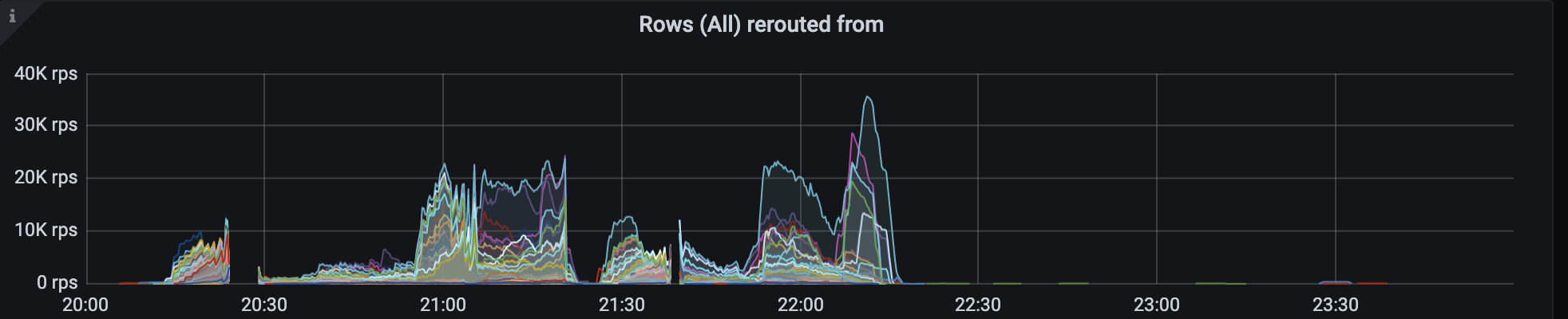
-
slow data ingestion rate. The normal rate is about 25k per node but the minimum rate is actually under 1k per node. This is the graph of one node, others are all the same.
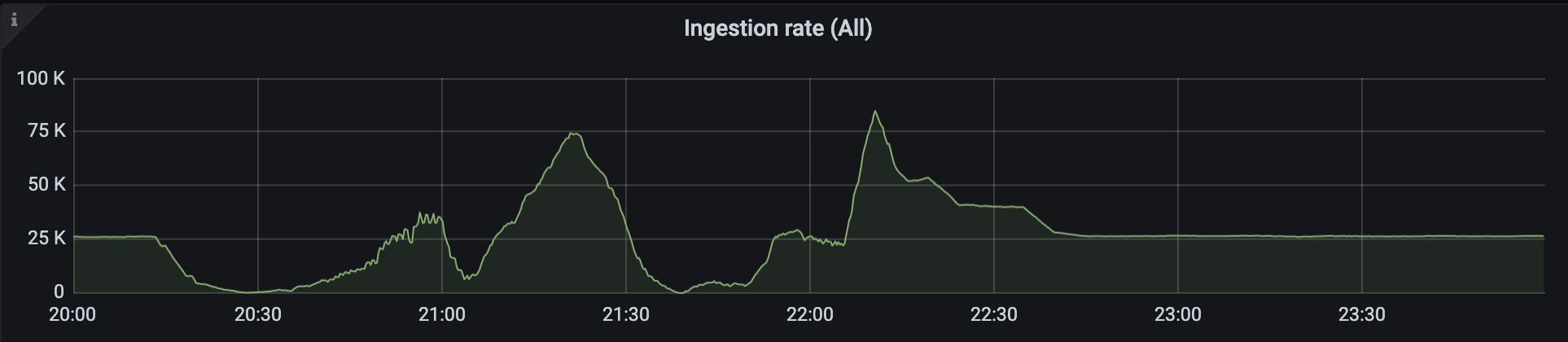
-
high index_write rate, more than 50X normal
It’s not a official panel from the grafana vm-cluster dasboard, the MetricQL is:
sum(rate(vm_rows{type="indexdb"}[10m]))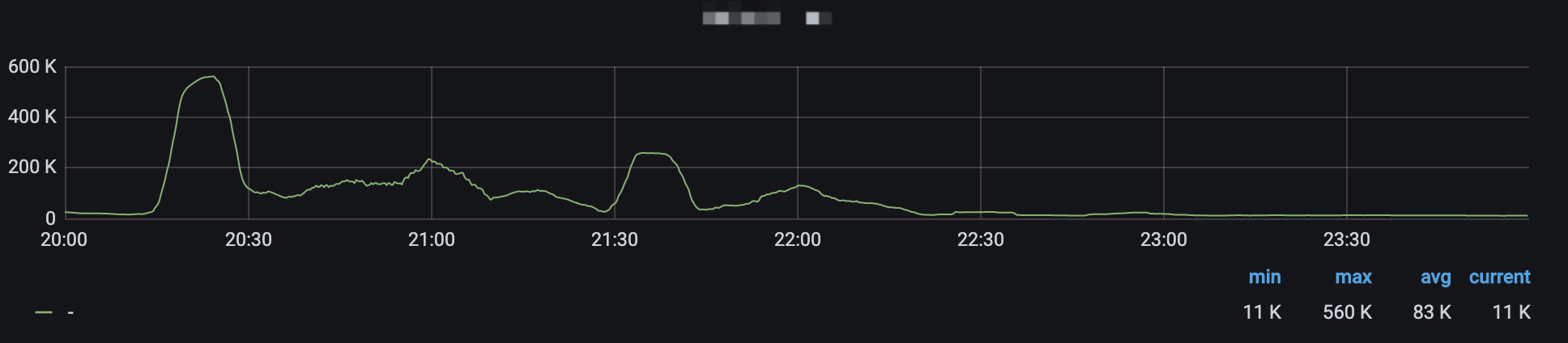
-
High IO usage and CPU usage:
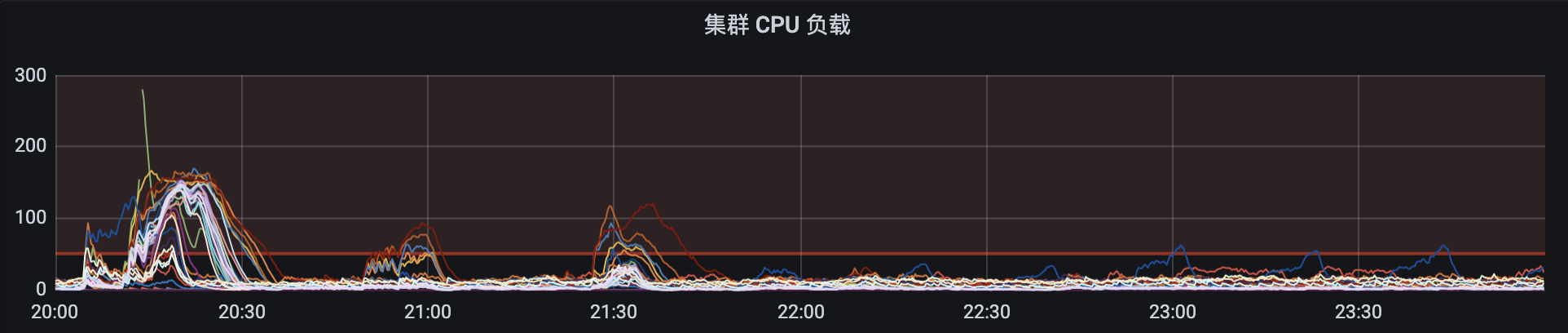
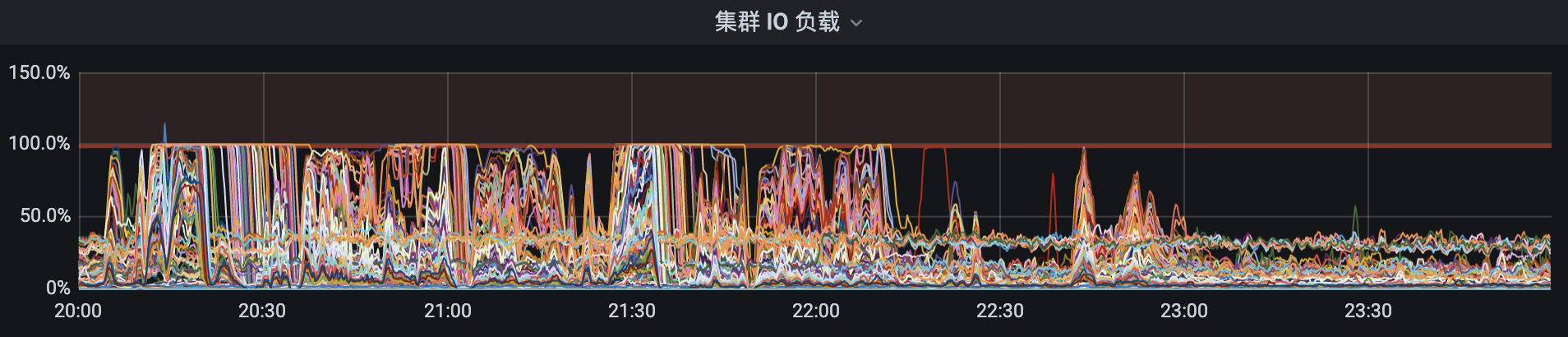 Not sure if it is the cause or a phenomenon.
Not sure if it is the cause or a phenomenon.
PS: We have over 100 vmstorage nodes, and have a life-keeper process to re-launch the storage node immediately after it gets killed(within 1m).
Since the high rate of rerouted_from and index_write, we assume that maybe it is caused by reroute in vminsert, This is the hypothesis based on our cases: We have two main reasons which get vmstoage killed:
- manually kill vmstorage or other processes’s high memory usage gets vmstorage OOM
- some slow queries increase vmstorages’ memory usage, and it gets OOM
After the storage node is down, vminsert reroutes data to other healthy nodes, and the new data increase the resource usage including IO, CPU, and the data ingestion of the healthy nodes get slow, so the reroute mechanism reroute data to any other healthy node, and boom, it causes avalanche!!!
To re-produce the situation, we build a cluster and use some other methods to keep the high IO and CPU usage, in the meanwhile, we scrape parts of our prod data into the cluster by vmagent, every is fine until we shut down one of our nodes, and the situation described above shown up.
In order to prove our hypothesis, we update the code to let vminsert stop rerouting the data from storage-x but still rerouting data from other nodes(we simply drop the data instead of rerouting).
We’ve done two operations here, 18:00 at storage-6 and 18:07 at storage-5. As you can see, after I shut down and restart storage-6 at 18:00, every thing seems fine because I stop the reroute from storage-6. But the same situation comes up when I shut down and restart vm-5 at 18:07.
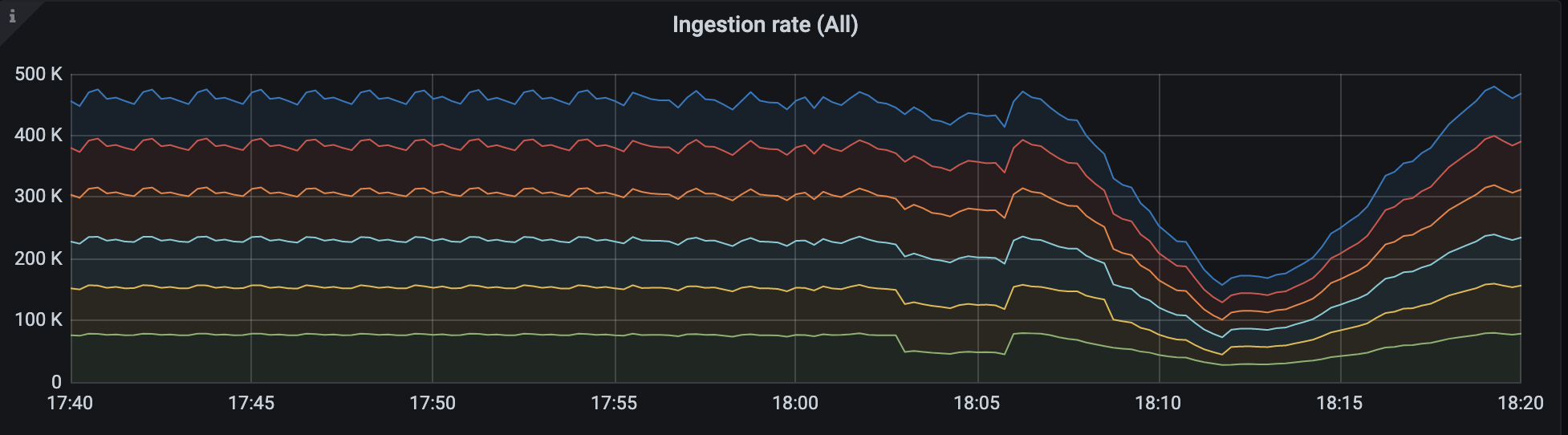
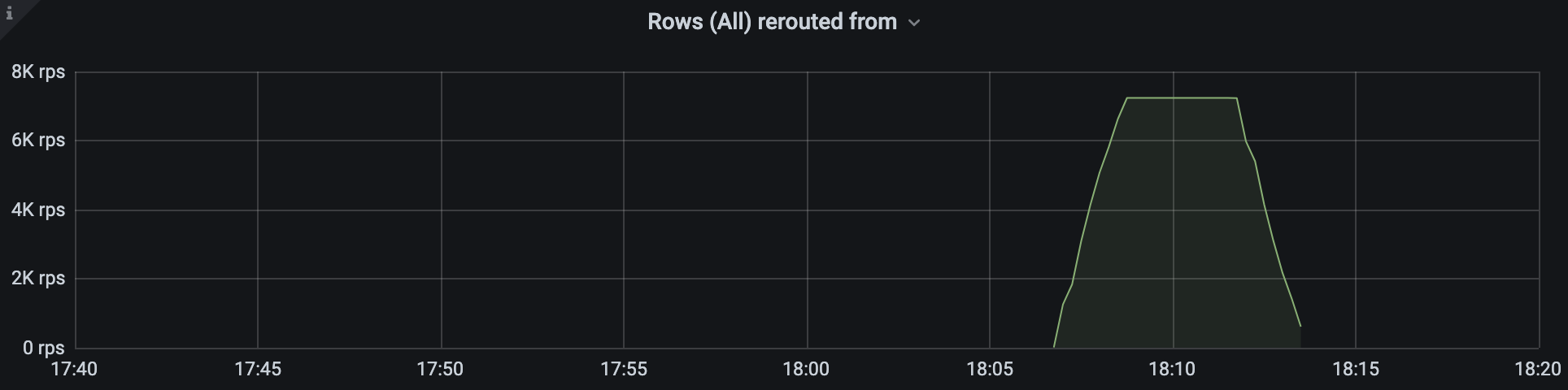
Version v1.39.4-cluster
About this issue
- Original URL
- State: open
- Created 4 years ago
- Comments: 15 (6 by maintainers)
Commits related to this issue
- app/vminsert: remove useless delays when sending data to vmstorage This improves the maximum data ingestion performance for cluster VictoriaMetrics Updates https://github.com/VictoriaMetrics/Victori... — committed to VictoriaMetrics/VictoriaMetrics by valyala 4 years ago
- app/vminsert: refresh the list of healthy storage nodes only if the the row cannot be sent to destination storage node Previously the list had been generated for each rerouted row. This could consume... — committed to VictoriaMetrics/VictoriaMetrics by valyala 4 years ago
- app/vminsert: add `-disableRerouting` command-line flag for disabling re-routing if some vmstorage nodes have lower performance than the others Refactor the rerouting mechanism and make it more resil... — committed to VictoriaMetrics/VictoriaMetrics by valyala 3 years ago
- app/vminsert/netstorage: tune re-routing algorithm Do not re-route data to unavailable storage node. Send it to the remaining storage nodes instead even if they cannot keep up with the load. This sho... — committed to VictoriaMetrics/VictoriaMetrics by valyala 3 years ago
- app/vminsert/netstorage: disable rerouting by default Production clusters work more stable with the disabled rerouting during rolling restarts and/or during spikes in time series churn rate. So it wo... — committed to VictoriaMetrics/VictoriaMetrics by valyala 3 years ago
- app/vminsert/netstorage: disable rerouting by default Production clusters work more stable with the disabled rerouting during rolling restarts and/or during spikes in time series churn rate. So it wo... — committed to VictoriaMetrics/VictoriaMetrics by valyala 3 years ago
Reasonable 😃 But still, the reroute algorithm kinda perform worse if we hit the worst case(everytime in our env). Anyway it’s a great solution in our case, we’ll keep searching for a more efficient solution though. Thanks for the reply.
This is how it works right now - if certain vmstorage node is temporarily unavailable, then all the incoming data for this node is spread across all the remaining vmstorage nodes. See https://github.com/VictoriaMetrics/VictoriaMetrics/blob/1ee5a234dcfb83f8457f1ede1cbe5197db4a7c42/app/vminsert/netstorage/netstorage.go#L607-L612 for details.
What I am trying to say in this issue is that the rerouting mechanism in vminsert maybe not perform well as expected in actual prod env with heavy pressure. And If this situation happens, It is hard to recover if we don’t get involved.
What we do to recover:
This surely makes vm service unavailable.
Any ideas about this issue? @valyala
If you need any details, I’m available on slack. I 'll also update the info to this issue.