VictoriaMetrics: There is a write performance bottleneck on my vm cluster, but the CPU and memory usage of the node is not high. Is there a way to optimize the write performance?
Is your question request related to a specific component?
vmagent,vminsert,vmstorage
Describe the question in detail
I have a vm cluster with 8 nodes. The configuration of each node is 48c192g.
This vm cluster ingests 135k objects. At present, there is a data writing delay, but each node has a lot of cpu and memory left. Is there any way to further use these remaining large cpu and memory to improve performance and solve the data writing delay?
My cluster architecture deploys a vmagent, vminsert, and vmstorage for each node. vmagent uses cluster mode to collect targets, and then sends them to vminsert on this node, and vminsert is sent to vmstorage on 8 nodes.
The startup parameters are as follows:
vmagent-1-8:
ExecStart=/usr/local/bin/vmagent-prod -promscrape.config=/data/vmagent/scrap.yml -remoteWrite.url=http://xxxx:8480/insert/0/prometheus/ -promscrape.cluster.membersCount=8 -promscrape.cluster.memberNum=[0-7] -promscrape.cluster.replicationFactor=2 -promscrape.maxScrapeSize=1GB -maxConcurrentInserts=100000
three vminsert use the same startup command:
ExecStart=/usr/local/bin/vminsert-prod -httpListenAddr 0.0.0.0:8480 -storageNode=node-1:8400,node-2:8400,10.node-3:8400,node-4:8400,node-5:8400,node-6:8400,node-7:8400 -replicationFactor=3 -maxConcurrentInserts 500000
three vmstorage use the same startup command:
ExecStart=/usr/local/bin/vmstorage-prod -loggerTimezone Asia/Shanghai -storageDataPath /data/vmstorage -httpListenAddr 0.0.0.0:8482 -vminsertAddr 0.0.0.0:8400 -vmselectAddr 0.0.0.0:8401 -dedup.minScrapeInterval 5s -maxConcurrentInserts 1000000
The current cluster bottleneck is as follows:
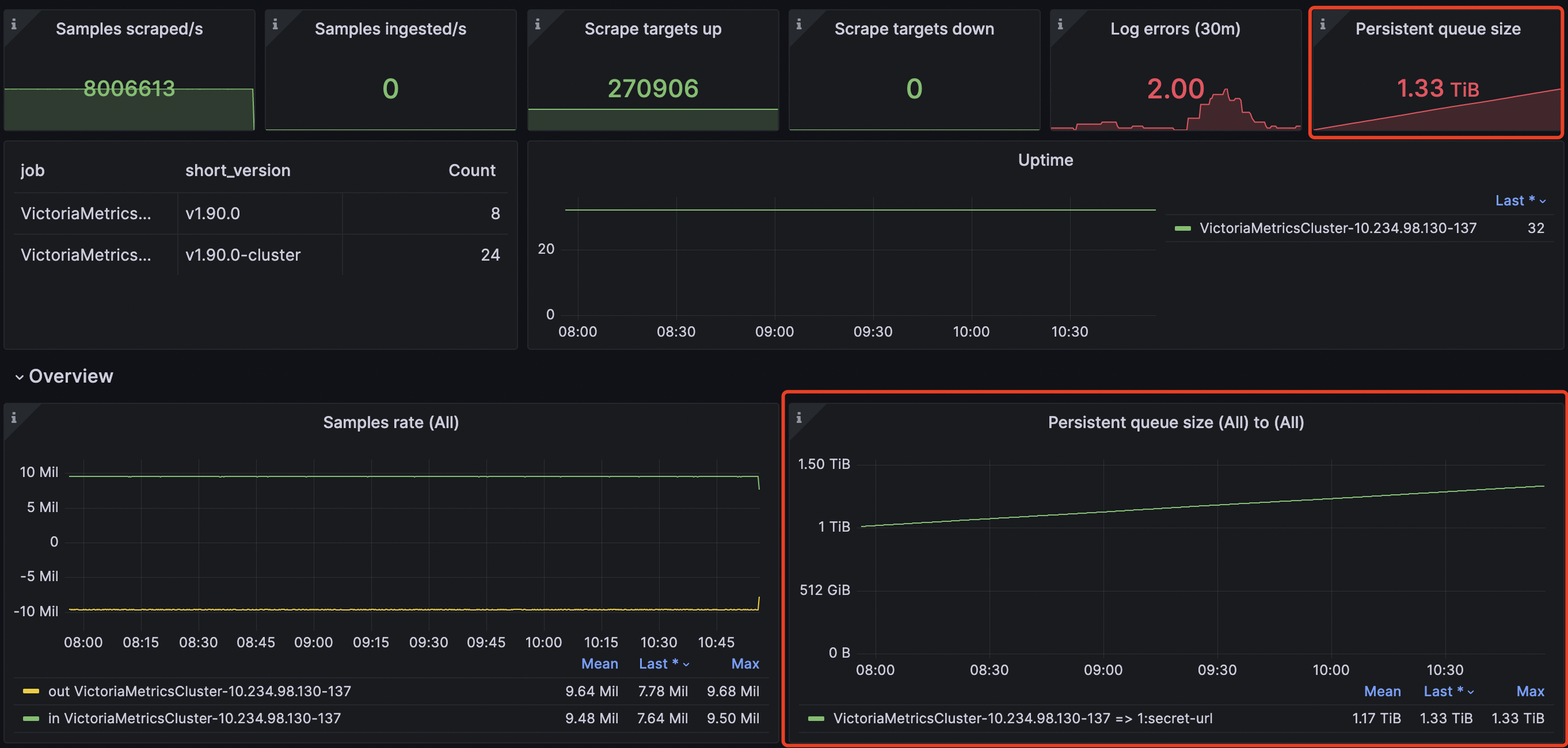
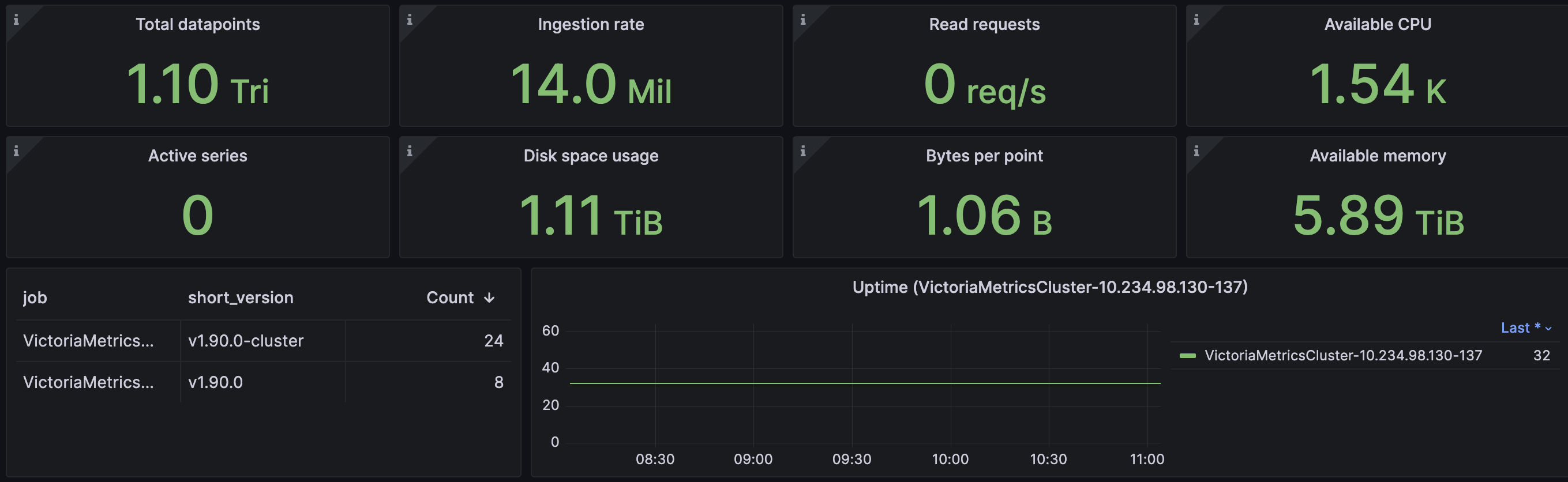
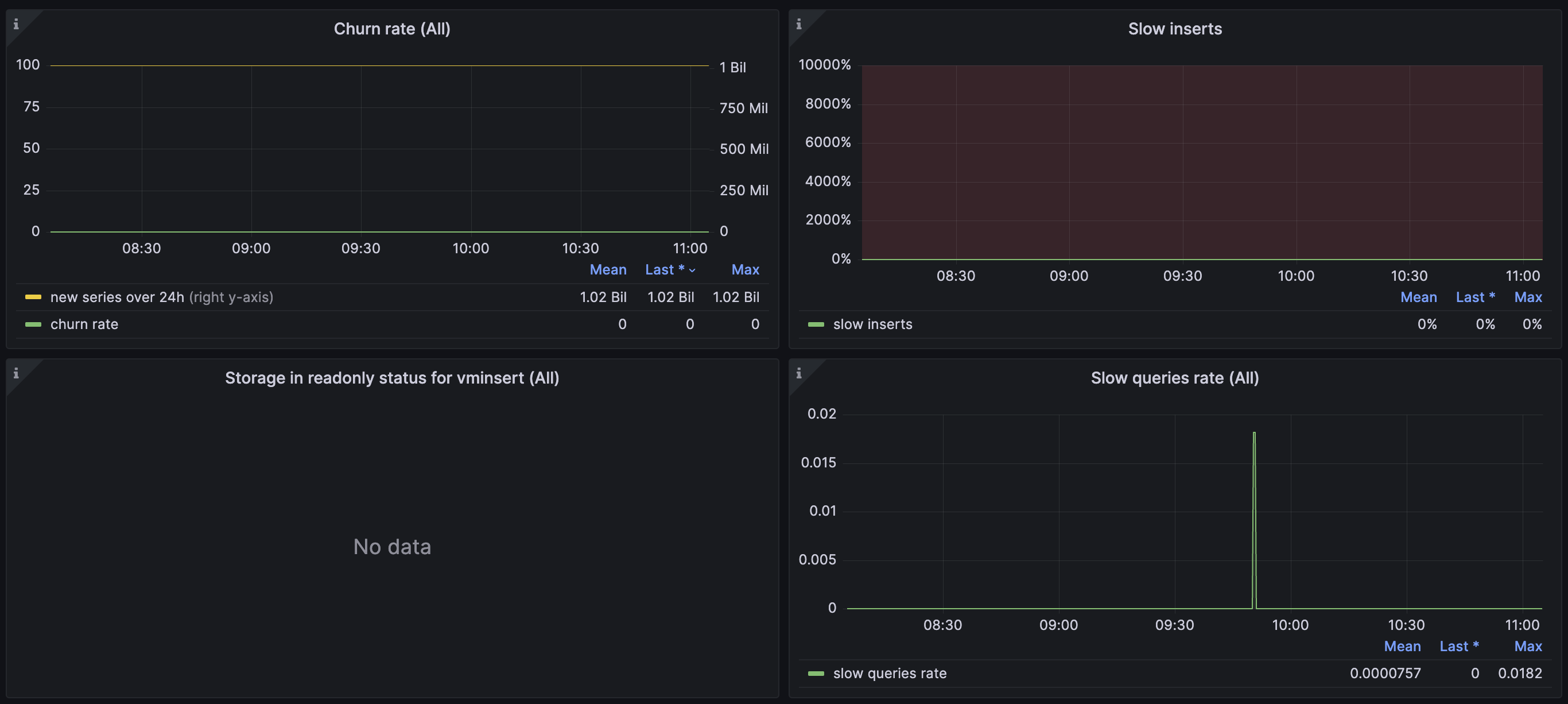
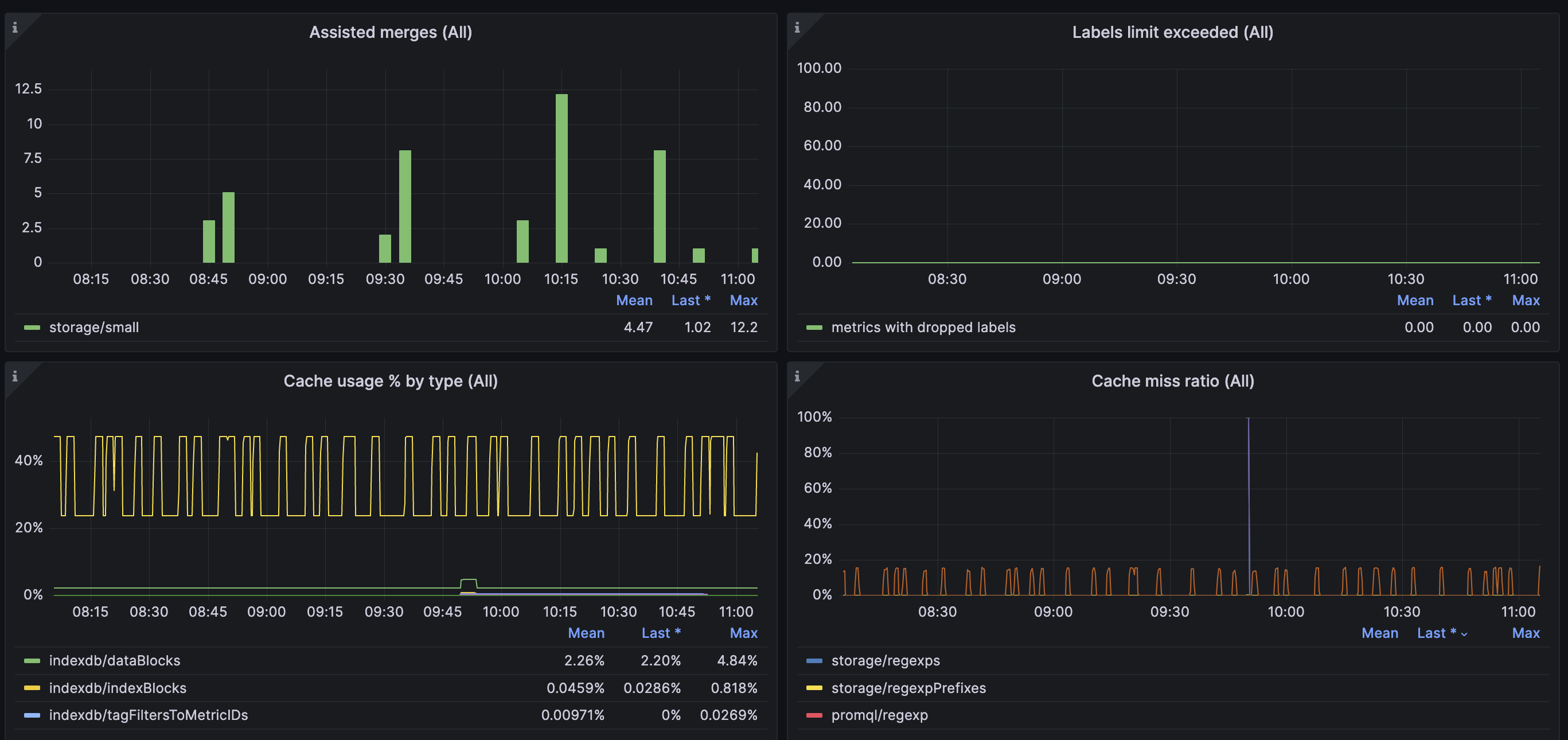
The resource utilization of the node is as follows:
cpu utilization rate is about 50%:
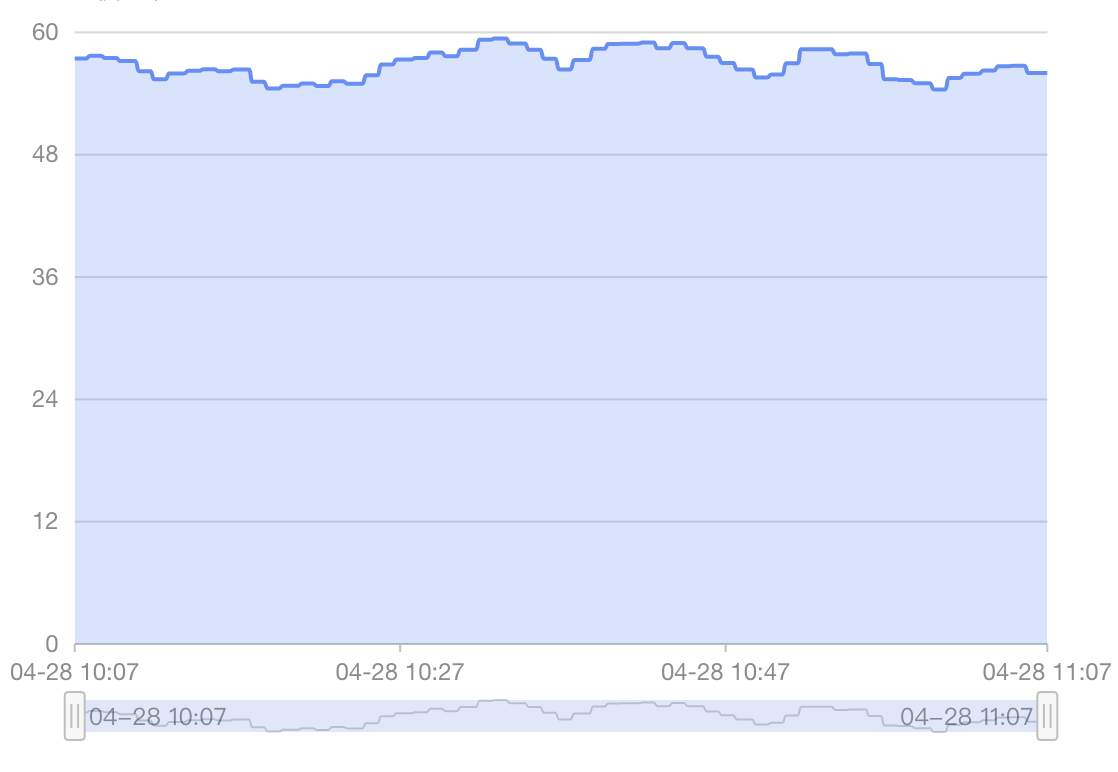
memory utilization rate is about 40%:
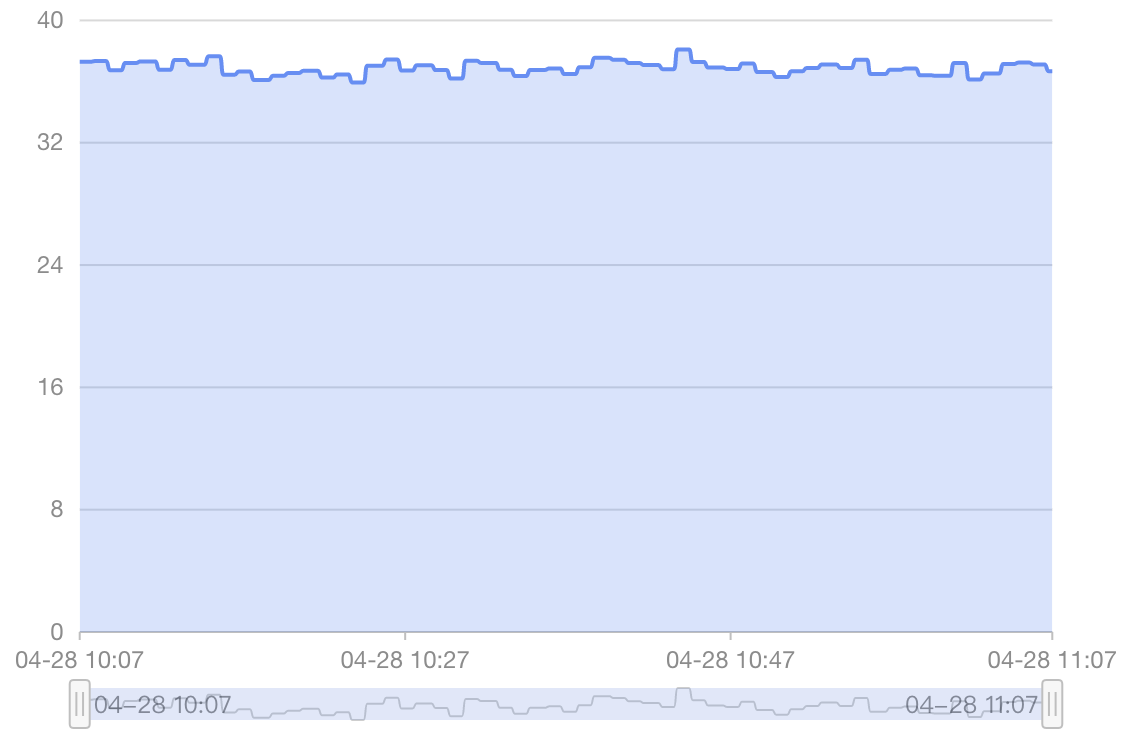
Are there any parameters that can further utilize the remaining cpu and memory to further improve the performance of the cluster to alleviate the delay in data writing?
Troubleshooting docs
About this issue
- Original URL
- State: closed
- Created a year ago
- Comments: 21
As I migrated all the virtual machines that may have bottlenecks in the cluster to exclusive physical machines, after running for three days, everything seems to be normal now. The reason should still be related to the cpu competition. Thank you very much for giving a lot of troubleshooting directions during the entire troubleshooting process. My vm cluster is currently running normally. I will close this issue, thanks again!