kiam: Kiam Causing Latency Issues on Microservices
Issue Description
We ran into some issues with Kiam Server (or Agent it is unknown which currently) after a significant uptime that led to issue with response times across the board. The Kiam Server needed a configuration change to set session-duration from 15m -> 60m and as a result the Kiam Server needed a restart. After the restart, we saw a significant drop in response time (80 - 99% across the board). I believe this is due to a memory leak that I will demonstrate momentarily.
Version
v2.7
Background
We run a number of unique microservices each with their own IAM roles, we do a handful of deploys every day for each of these services as well.
We started seeing significant increases in latency as throughput increased. Initially these were attributed to network latency, then CPU latency and kubelet scheduling for the shared pool. We were able to eliminate 60 - 70% of the response time on one service by increasing cpu.requests and scaling the pods horizontally. However, we still didn’t understand the last 100 ms of latency on several services, and at times 2s of latency on other services.
While preparing to run some tests to further characterization this problem. The Kiam server went through the changes described above. Resulting in the solution of the problems we were experiencing.
I will begin by showcasing the latency we were seeing, then the data that supports the memory issue.
Services Latency
This is one example of the change we saw in the latency after restarting the Kiam Servers and applying the configuration change.

As you can see, there is an approximately 99.9% decrease in response time. In addition to an increase of 300 - 400% in the throughput of the service. Which is awesome!
Data
So, I started diving into some of the metrics that the kiam servers, agents and clients report.
The first shows two particular metrics getpodrole on the Server and isallowedassumerole on the Client. You can see a significant drop at the upgrade time. Similar to the latency cliff we see.

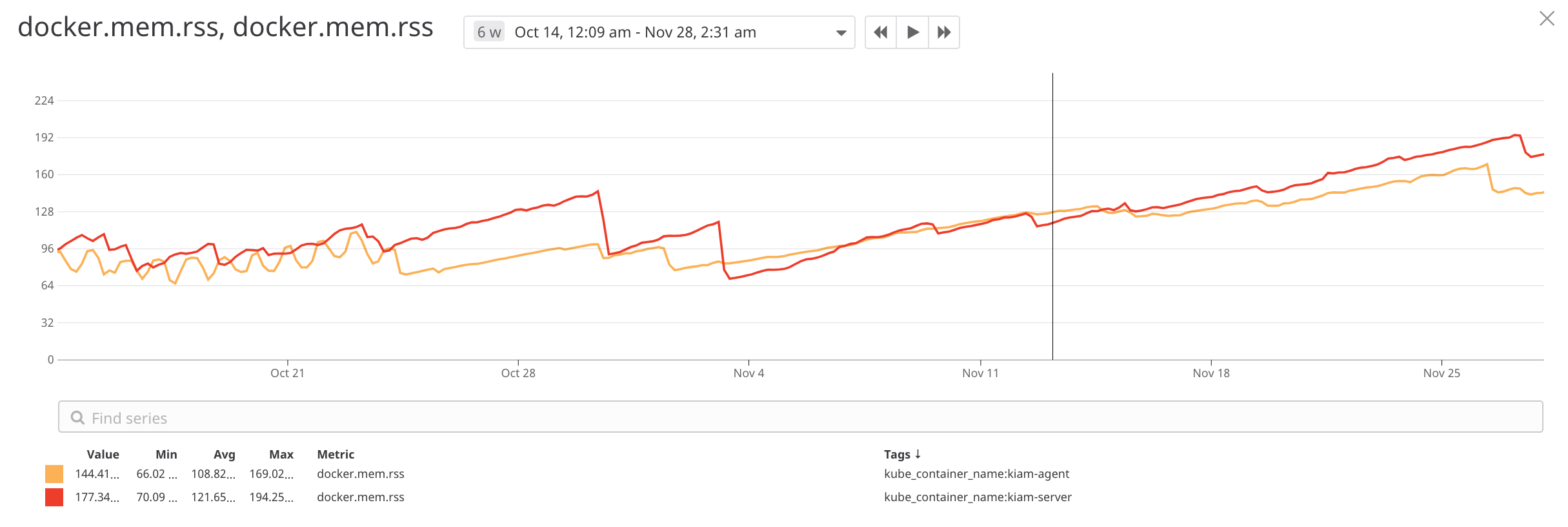
The next shows the reported RSS (physical memory allocated) of the containers for Kiam Server and Kiam Agent over the course of the last 6 weeks. It is averaged across all instances of the different instances in the Kubernetes cluster.
In case it is relevant, here is the number of instances running of each across the cluster over the last 3 months.

We saw a similar drop in both CPU utilization and Network Utilization on the EC2 Nodes hosting the Kiam Server Containers. I can pull those metrics if need be.
If you need me to run any tests or anything let me know and I can coordinate the those. It appears to be related to uptime, so there may needs to be a simulation of load that we can run very quickly to help incite the problem.
Summary
Based on the metrics I was seeing, and my brief look at the code. I think that there may be channels that are not being closed and those channels are making more and more requests to the system.
Or the server eventually disregards the refresh interval and attempts far more often than it needs.
About this issue
- Original URL
- State: closed
- Created 6 years ago
- Reactions: 1
- Comments: 19 (8 by maintainers)
We recently discovered this issue on our own, and after tracing some code in the AWS Java SDK, we found that the SDK refreshes instance profile tokens once they are within 15 minutes of expiration. KIAM creates tokens with 15 minutes of expiration. Therefore, every request triggers a token refresh.
Here are the relevant constants in the SDK: https://github.com/aws/aws-sdk-java/blob/master/aws-java-sdk-core/src/main/java/com/amazonaws/auth/EC2CredentialsFetcher.java#L43-L53
In order to get around this issue, we’ve added these arguments to KIAM. This seems to be fixing the issue.
I’ve filed an issue with the AWS Java SDK, which can be found here: https://github.com/aws/aws-sdk-java/issues/1893