thanos: sidecar+query: Slower than prometheus on specific query
Thanos, Prometheus and Golang version used:
# thanos --version
thanos, version 0.10.1 (branch: HEAD, revision: bdcc35842f30ada375f65aaf748a104b43d56672)
build user: circleci@4e51e880cd24
build date: 20200124-07:36:32
go version: go1.13.1
Prometheus 2.16.0
What happened:
We currently manage two Kubernetes clusters (GKE), each running their own prometheus-operator and Prometheus with three replicas, with the Thanos Sidecar. We deploy Thanos Query in one of the clusters, setup to point to all Prometheus in both clusters. The Sidecar isn’t uploading metrics to object storage yet, and prometheus has a few months worth of metrics.
There are some queries that are much more slower in Thanos Query than in Prometheus.
For examply:
sum(open_connections{job="harvestapp-websocket", namespace="default"}) by(pod)
In Prometheus, 7 days of data, ~1.5s:
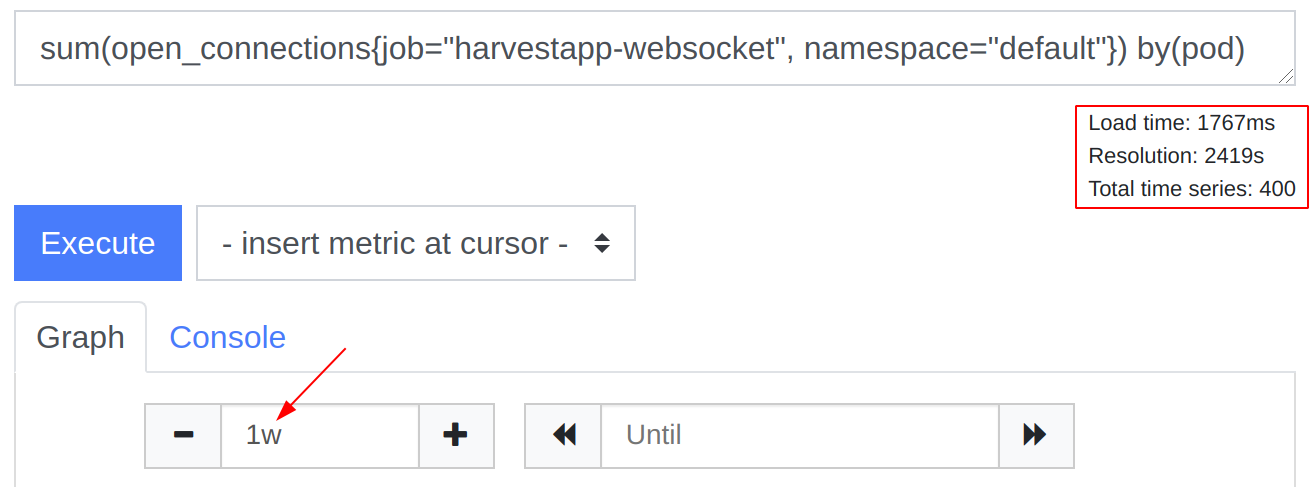
In Thanos Query, without deduplication, ~11s:
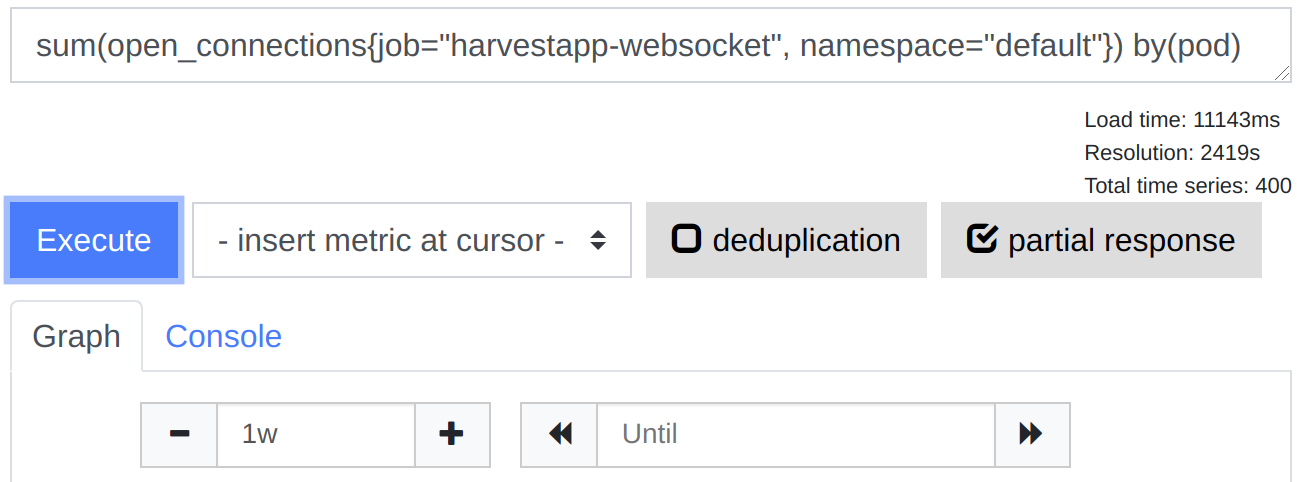
In Thanos Query, with deduplication, ~17s:
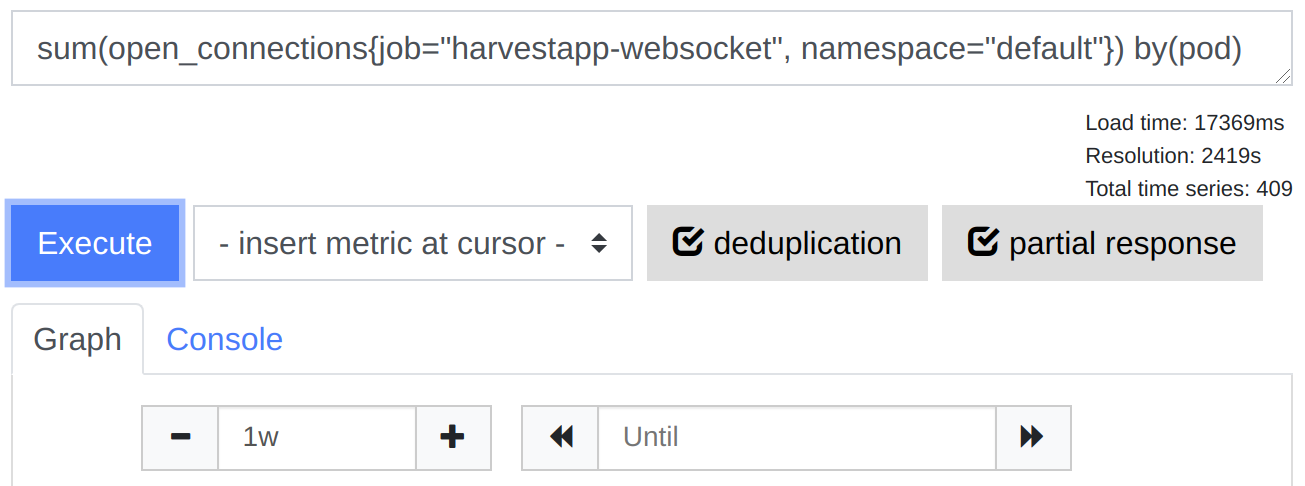
We recently tried promxy to see if it had the same problem, and it seems to perform only marginally slower than Prometheus:
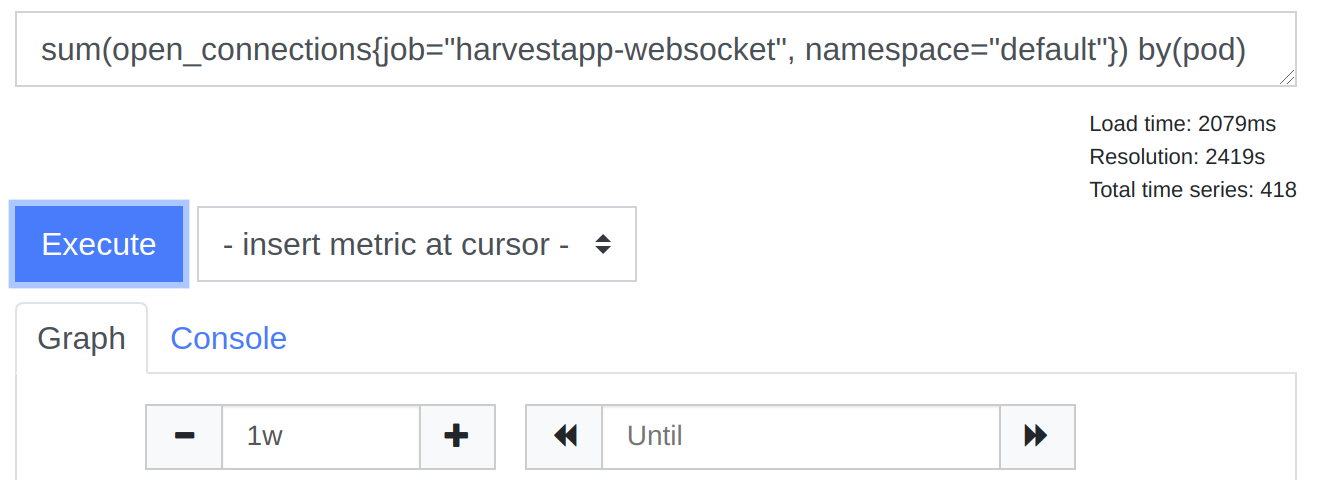
This is a metric we track per pod, and in this case, it’s an autoscaled deployment (we autoscale on this specific metric in fact), hence the different numbers of Time series from the screenshots, it kept growing as I was writing this due to time of day. We don’t necessarily need to use Thanos Query in this specific case, but we’re pointing Grafana’s default data source to it to simplify things. This was one very specific example query, but our Grafana panel loads a few more things, which, with Thanos Query, times out if we load anything more than a few hours worth of metrics.
I understand it might not be the ideal situation with prometheus, having a label that keeps growing in cardinality with time. I would expect Thanos Query to be a bit slower (a small % than the slowest prometheus, not 10x). Could this be considered a bug? To be expected? Will we see the same problem if we deploy the Store component?
I thought it might be related to https://github.com/thanos-io/thanos/issues/2222, but that one only seems to mention deduplication (in our case deduplication is indeed slower than without), and in our case things are slower regardless.
Thanks a lot for your time! We’d really like to use Thanos, it’s been a pleasure to setup everything and it’d be the ideal solution for us.
About this issue
- Original URL
- State: closed
- Created 4 years ago
- Reactions: 5
- Comments: 26 (7 by maintainers)
ChuncIter is in progress. Actually looking to finish that this week!
Thanks for this. This is because
promxyuses Query API which is quite scary (data goes through PromQL, so it’s not really raw). This might cause some correctness issues. They allow choosing usingremote_readwhich then uses a similar path as sidecar but in the old version, so it will suffer from major memory consumption on both Prometheus and promxy. I am also not familiar with how they do deduplication but probably similar approaches to our penalty-based algorithm.Thanos does it on the mentioned
remote readPrometheus API so pure raw data level. Since this API was old and had lots of limitations we are keeping eyes on it and actually maintain remote read on Prometheus side. For example we added very needed streaming which causes sidecar to use ~const amount of memory per request. (details).Anyway I think its not deduplication latency reason in your case. The problem is the missing ChunkIterator on TSDB, which I am currently adding to Prometheus. 🤗 (https://github.com/prometheus/prometheus/pull/7069 & https://github.com/prometheus/prometheus/pull/7059) Will notify here once ready for some testing,
Hm… it’s so old issue that first let’s figure if this is still happening (latency is visible and it has to do particularly Chunk Iterator part).
I know @spaparaju is on https://github.com/thanos-io/thanos/issues/4304 which is similar. Let’s investigate (:
Ups, was closed, but I don’t think this is resolved.
It’s been a while, but I think we were still seeing this issue post update. Happy to provide more data if it will help us get to the bottom of this! Improving the query latency here would be huge for us!
Hey, yes it was merged, and nothing to be changed on our side. We are waiting for Prometheus release AND some tests that would confirm that this actually helped. With chunk iterator indeed there is no theoretical reason why it could be slower, but let’s confirm before closing this 🤗
Still in progress 😢