testcontainers-go: Context deadline exceeded, host port waiting failed: failed to start container
Describe the bug
Apologies if it is not a bug but kind of a blocker for me. I’m trying to start a Postgres container for my service isolation tests (or integration tests) in a GoLang service but I am getting the below error at line testcontainers.GenericContainer()
Get "http://%2Fvar%2Frun%2Fdocker.sock/v1.41/exec/113ba64db53a26f6c8092979bee43dbe07d4e1d71f9783e70243d83182cc83e1/json": context deadline exceeded, host port waiting failed: failed to start container
To Reproduce I am sharing the code snippet that I am using to start my Postgres test container
ctx, cancel := context.WithTimeout(context.Background(), time.Minute)
defer cancel()
req := testcontainers.ContainerRequest{
Image: "postgres:12",
AutoRemove: true,
Env: map[string]string{
"POSTGRES_DB": "test",
"POSTGRES_USER": "postgres",
"POSTGRES_PASSWORD": "test",
},
ExposedPorts: []string{"5433/tcp"},
WaitingFor: wait.ForListeningPort("5433/tcp"),
}
postgres, err := testcontainers.GenericContainer(ctx, testcontainers.GenericContainerRequest{
ContainerRequest: req,
Started: true,
})
if err != nil {
return nil
}
return &TestDatabase{
instance: postgres,
}
Expected behavior Ideally, the error shouldn’t come
** docker info **
Client:
Context: default
Debug Mode: false
Plugins:
buildx: Docker Buildx (Docker Inc., v0.8.2)
compose: Docker Compose (Docker Inc., v2.6.1)
extension: Manages Docker extensions (Docker Inc., v0.2.7)
sbom: View the packaged-based Software Bill Of Materials (SBOM) for an image (Anchore Inc., 0.6.0)
scan: Docker Scan (Docker Inc., v0.17.0)
Server:
Containers: 2
Running: 2
Paused: 0
Stopped: 0
Images: 2
Server Version: 20.10.17
Storage Driver: overlay2
Backing Filesystem: extfs
Supports d_type: true
Native Overlay Diff: true
userxattr: false
Logging Driver: json-file
Cgroup Driver: cgroupfs
Cgroup Version: 2
Plugins:
Volume: local
Network: bridge host ipvlan macvlan null overlay
Log: awslogs fluentd gcplogs gelf journald json-file local logentries splunk syslog
Swarm: inactive
Runtimes: io.containerd.runc.v2 io.containerd.runtime.v1.linux runc
Default Runtime: runc
Init Binary: docker-init
containerd version: 10c12954828e7c7c9b6e0ea9b0c02b01407d3ae1
runc version: v1.1.2-0-ga916309
init version: de40ad0
Security Options:
seccomp
Profile: default
cgroupns
Kernel Version: 5.10.104-linuxkit
Operating System: Docker Desktop
OSType: linux
Architecture: x86_64
CPUs: 6
Total Memory: 7.773GiB
Name: docker-desktop
ID: MJX5:RF4C:UDYA:LKWZ:LLDE:6JCA:R2WZ:A676:7E4X:HMKY:K7QB:PRF6
Docker Root Dir: /var/lib/docker
Debug Mode: false
HTTP Proxy: http.docker.internal:3128
HTTPS Proxy: http.docker.internal:3128
No Proxy: hubproxy.docker.internal
Registry: https://index.docker.io/v1/
Labels:
Experimental: false
Insecure Registries:
hubproxy.docker.internal:5000
127.0.0.0/8
Live Restore Enabled: false
Additional context
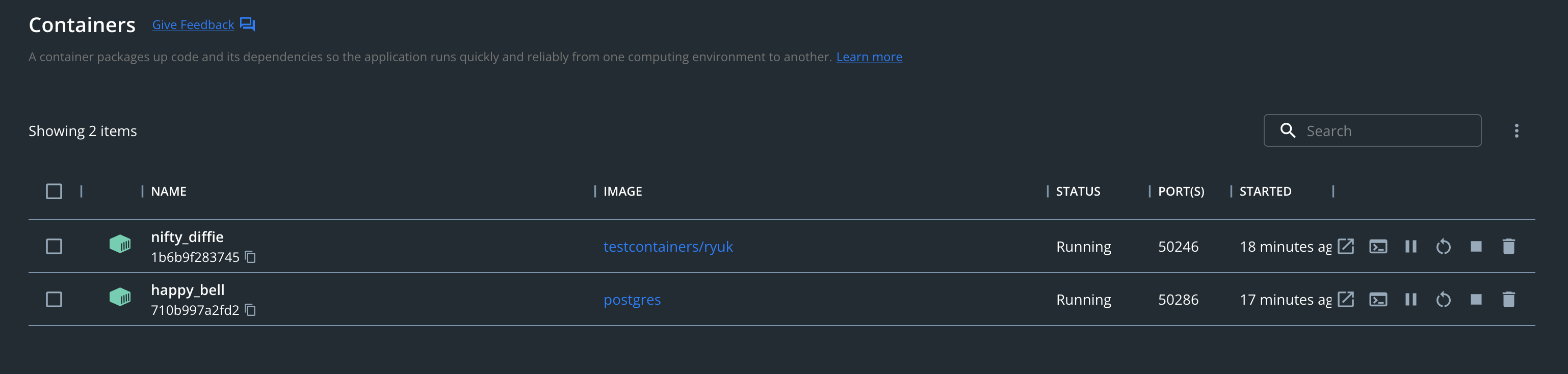
The little weird thing I can see is when I check the status of both the containers (testcontainers/ryuk & postgres) in Docker Desktop. It shows running

About this issue
- Original URL
- State: closed
- Created 2 years ago
- Comments: 15 (2 by maintainers)
I forgot to mention that using the forSql can find a successful connection in the first startup but then the postgres service is shutdown. So, the client could fail. Having the forLog should be the most reliable for this scenario.
When running Postgres, the container will start, setup, shutdown and then start again and ready to receive connections. That’s why the log strategy should be expected twice.
Just as another datapoint, I’m getting this error too. It doesn’t happen when I run our test suite locally, but it does in github for random tests/containers, which leads me to assume it’s an instance size issue. All containers are
GenericContainers withStarted trueset