tesseract: Can't encode transcription
Environment
- Tesseract Version: tesseract alpha - 4.0.0
- Platform: Linux Ubuntu 16.04 LTS
Tesseract lstmtraining is used to train Korean language. The following error has occurred.
lstmtraining \
--model_config $HOME/work/kor/tuned/kortuned \
--continue_from $HOME/work/kor/tuned/kor.lstm \
--train_listfile $HOME/work/kor/config/kor.training_files.txt \
--target_error_rate 0.01 \
--max_iterations 1200
It seems that a compression error occurs in the following complex characters.
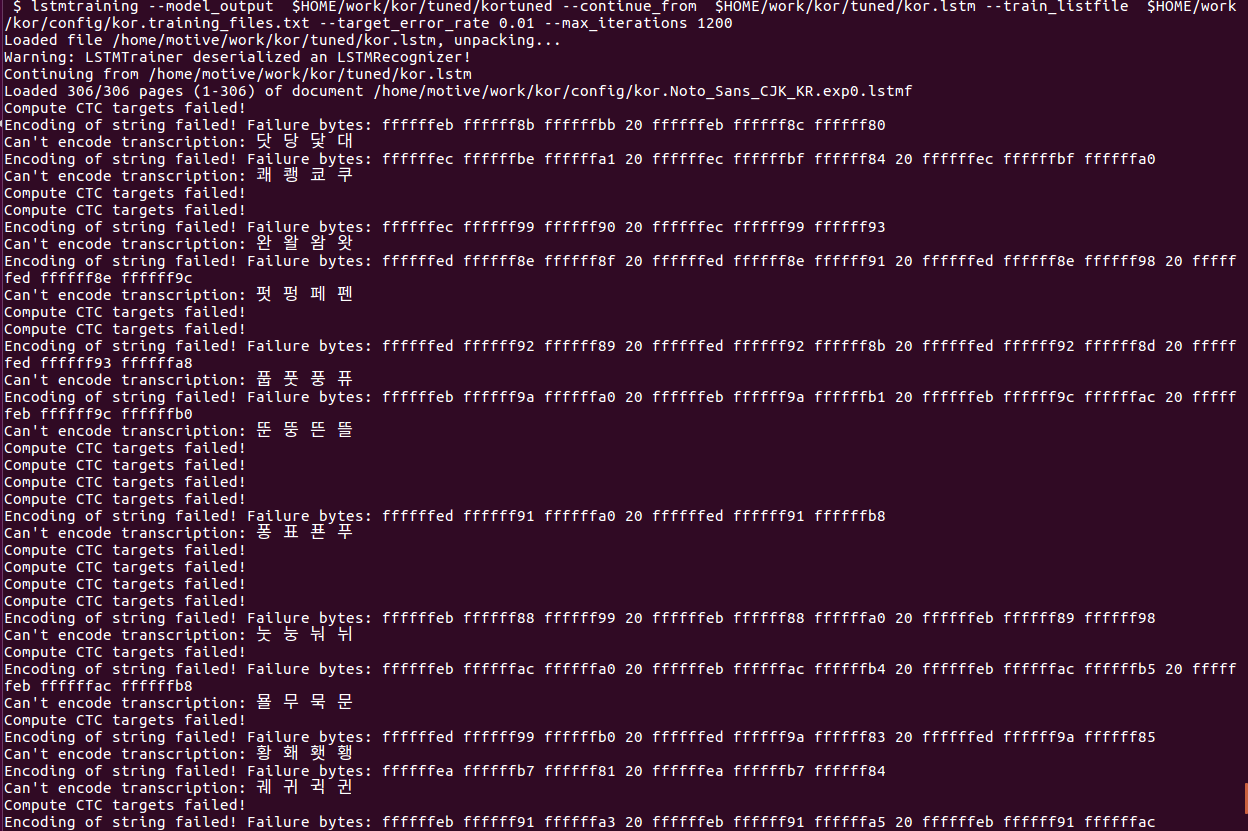
How do I resolve this issue?
Do I need to register for Korean unicharset?
About this issue
- Original URL
- State: closed
- Created 7 years ago
- Comments: 25 (4 by maintainers)
This error happens with combining acute accent (
U+0301).Well-prepared texts (Slavic, specifically) contain them to disambiguate the meaning.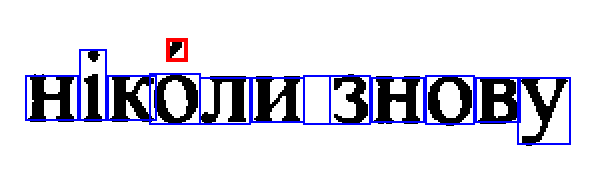
text2imagedoes the job correctly:But during training, you get Can’t encode transcription followed by Encoding of string failed! As the result, Tesseract is unable to recognize words containing accent.
Does anyone know a solution to make Tesseract work with accents? at least to recognize a “clean” letter underneath and ignore the mark itself.
(Built from github revision 72d8df581b315168c8f73a42ae74f733f9d018b9, Dec 16)
I am not able to reproduce the problem for Korean using the training_text in langdata. Since the original issue does not provide the error text (only an image) I cannot test with it.
However, error exists for Sinhala.