tensorflow: Wrong Error Raised: "The graph couldn't be sorted in topological order"
Please make sure that this is a bug. As per our GitHub Policy, we only address code/doc bugs, performance issues, feature requests and build/installation issues on GitHub. tag:bug_template
System information
- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Yes
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Linux Ubuntu 16.04
- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device:
- TensorFlow installed from (source or binary): pip from anaconda
- TensorFlow version (use command below): 1.12.0
- Python version: 3.5.0
- Bazel version (if compiling from source):
- GCC/Compiler version (if compiling from source):
- CUDA/cuDNN version: CUDA 9.0
- GPU model and memory: GeForce GTX 1080Ti / Tesla K80
You can collect some of this information using our environment capture script You can also obtain the TensorFlow version with python -c “import tensorflow as tf; print(tf.GIT_VERSION, tf.VERSION)”
Describe the current behavior
The tensorflow will raise The graph couldn't be sorted in topological order Error when executing the optimizer. While The error doesn’t occur on tensorflow 1.10.0. This error is also posed here by another user.
Describe the expected behavior
The error should not be raised because there is no loop in the computation graph.
Code to reproduce the issue Provide a reproducible test case that is the bare minimum necessary to generate the problem.
import tensorflow as tf
print(tf.__version__)
activation = tf.nn.relu
img_plh = tf.placeholder(tf.float32, [None, 3, 3, 3])
label_plh = tf.placeholder(tf.float32, [None])
layer = img_plh
buffer = []
ks_list = list(range(1, 10, 1)) + list(range(9, 0, -1))
for ks in ks_list:
buffer.append(tf.layers.conv2d(layer, 9, ks, 1, "same", activation=activation))
layer = tf.concat(buffer, 3)
layer = tf.layers.conv2d(layer, 1, 3, 1, "valid", activation=activation)
layer = tf.squeeze(layer, [1, 2, 3])
loss_op = tf.reduce_mean(tf.abs(label_plh - layer))
optimizer = tf.train.AdamOptimizer()
train_op = optimizer.minimize(loss_op)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
result = sess.run(train_op, {img_plh: np.zeros([2, 3, 3, 3], np.float32), label_plh: np.zeros([2], np.float32)})
Other info / logs Include any logs or source code that would be helpful to diagnose the problem. If including tracebacks, please include the full traceback. Large logs and files should be attached.
About this issue
- Original URL
- State: closed
- Created 5 years ago
- Comments: 32 (1 by maintainers)
I want to build a SSD netWork by myself ,and I meet the same problem .
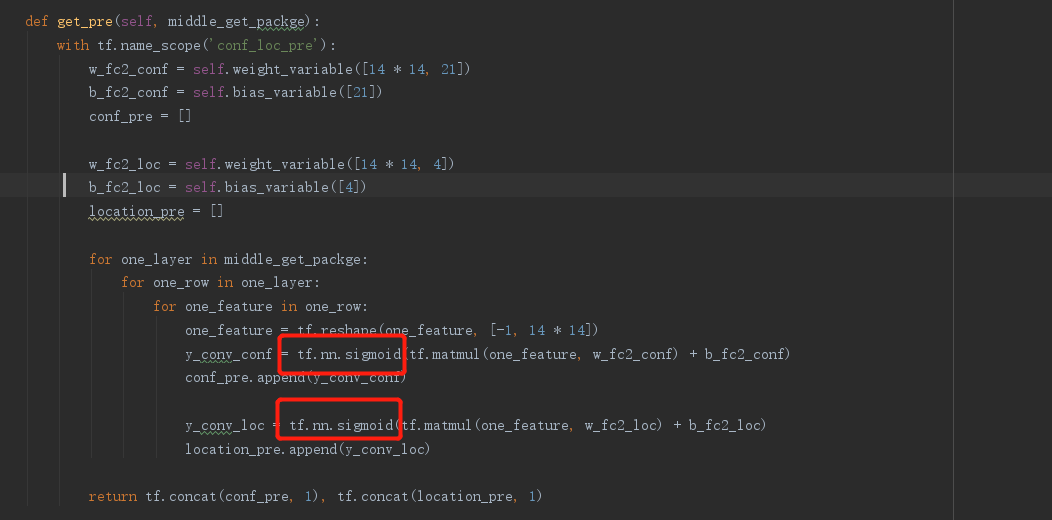
i have seen this method,it can run ok.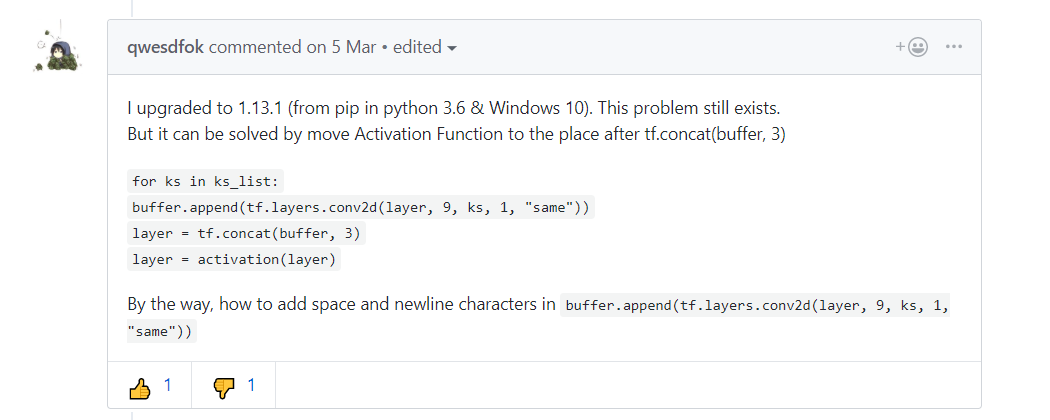 then i try to solve my problem like this method!
the old code as show belown
then i try to solve my problem like this method!
the old code as show belown
 i removed the Activation function,like this:
i removed the Activation function,like this:
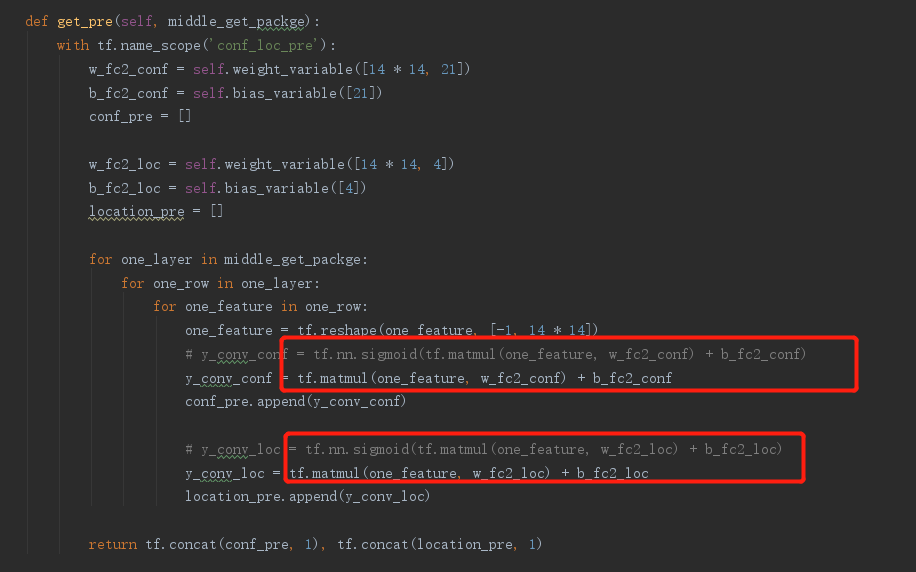 the proplem disappeared
conclusion:
the proplem disappeared
conclusion:
whten many tensors which are actived by Activation function are concated as a list ,this problem will appear! i think this is a problem of tensorflow.
Faced it when use
concatasrepeat_elementsAny news&process here? I also face the same problem. Here is my code:
weight_atom = tf.get_variable(name, [2, 2])#do repetitionweight_row = tf.concat([weight_atom] * 2, axis=1)weight = tf.concat([weight_row] * 2, axis=0)out = tf.matmul(input, weights)The code create a (2,2) matrix then does repetition and multiply the result with the input which shape is (4,4)
Could you try to decrease batch size? This seems to be memory related.
I upgraded to 1.13.1 (from pip in python 3.6 & Windows 10). This problem still exists. But it can be solved by move Activation Function to the place after tf.concat(buffer, 3)
for ks in ks_list:buffer.append(tf.layers.conv2d(layer, 9, ks, 1, "same"))layer = tf.concat(buffer, 3)layer = activation(layer)By the way, how to add space and newline characters in
buffer.append(tf.layers.conv2d(layer, 9, ks, 1, "same"))I got this error as I was using tf.keras.backend.repeat_elements (TF=1.13.1). If the tensor is of type int32/int64, it is possible to use tf.tile instead.
In my case, I wanted to repeat and concat a binary 1-dim tensor, A, to be used for filtering another tensor. I managed to get the same result as with repeat_elements without the error with:
A = tf.expand_dims(A, axis=1)A = tf.tile(A, [1, num_repeats])It should also be possible to run tf.tile and then tf.reshape, but at least in my simple case what I wrote above was sufficient. tf.tile also supports higher dims: https://www.tensorflow.org/api_docs/python/tf/tile
I got the same issue, then I tried to replace the
tf.concatwithtf.stackfunction and the issue disappeared. I am doing so because I am concatenating into a new dimension. Hope this can help.Better not. Instead, you could try to do multiple concat instead of a huge concat. (yes, that’s ugly)
I think your guess is right.