tensorflow: Training with GPU on TF 2.0 is much slower than on TF 1.14 if set a large number to `input_dim` of `tf.keras.layers.Embedding`
System information
- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Yes
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04):
Linux-3.10.0-957.21.3.el7.x86_64CentOS-7.3.1611-Core - Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device: None
- TensorFlow installed from (source or binary): binary, pip install tensorflow-gpu
- TensorFlow version (use command below):
2.0.0-rc0(v2.0.0-beta1-5101-gc75bb66),1.14.0(v1.14.0-rc1-22-gaf24dc91b5) - Python version: 3.6.8
- Bazel version (if compiling from source): None
- GCC/Compiler version (if compiling from source): None
- CUDA/cuDNN version: CUDA 10.0.130, cuDNN 7.6.3.30
- GPU model and memory: RTX 2070 Super, 8GB
Describe the current behavior
I converted the Keras implementation of Neural Matrix Factorization (NeuMF) to tf.keras and it works well on TF 1.14.
But when I run it on TF 2.0.0-rc0, the training is much slower than on TF 1.14.
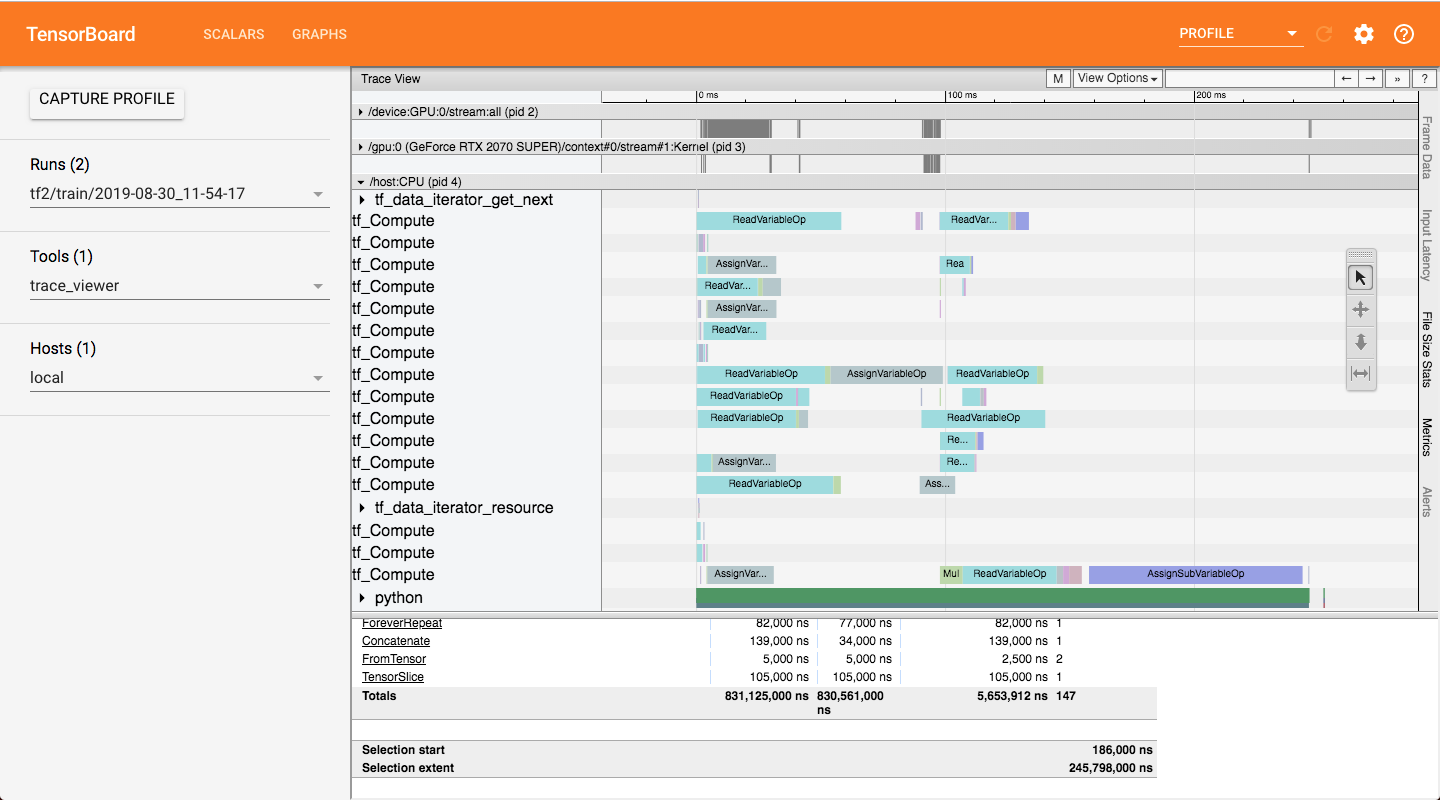
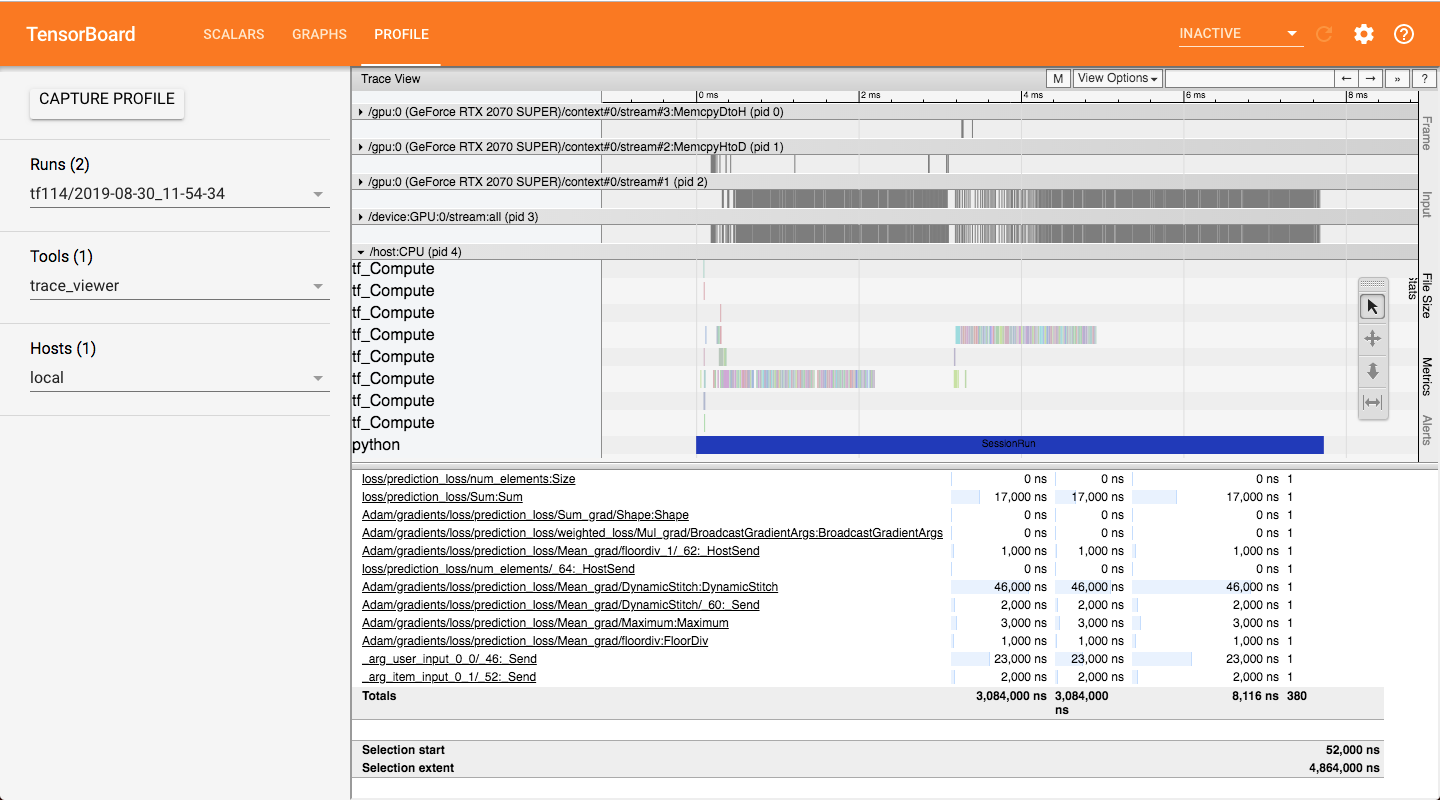
I use the profiling tools to check the time, and I found ReadVariableOp takes too much time if I set a large number to the input_dim of tf.keras.layers.Embedding.
Tensorflow version: 2.0.0-rc0
Epoch 1/3
10000/10000 [==============================] - 5s 532us/sample - loss: 0.6935
Epoch 2/3
10000/10000 [==============================] - 4s 436us/sample - loss: 0.6903
Epoch 3/3
10000/10000 [==============================] - 4s 431us/sample - loss: 0.6851
Tensorflow version: 1.14.0
Epoch 1/3
10000/10000 [==============================] - 2s 212us/sample - loss: 0.7035
Epoch 2/3
10000/10000 [==============================] - 0s 28us/sample - loss: 0.6981
Epoch 3/3
10000/10000 [==============================] - 0s 29us/sample - loss: 0.6909
Describe the expected behavior
The speed of training on TF 2.0 with large input_dim of Embedding should be the same as TF 1.14 or faster.
Code to reproduce the issue
I have shared the codes on Colab
or check the codes below.
# -*- coding:utf-8 -*-
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.regularizers import l1, l2
from tensorflow.keras.layers import Embedding, Input, Dense, Lambda, Flatten
def get_model(num_users, num_items, mf_dim=10, layers=[10], reg_layers=[0], reg_mf=0, alpha=0.5):
assert len(layers) == len(reg_layers)
num_layer = len(layers) #Number of layers in the MLP
# Input variables
user_input = Input(shape=(1,), dtype='int32', name = 'user_input')
item_input = Input(shape=(1,), dtype='int32', name = 'item_input')
# Embedding layer
MF_Embedding_User = Embedding(input_dim = num_users, output_dim = mf_dim, name = 'mf_embedding_user',
embeddings_initializer = keras.initializers.RandomNormal(mean=0.0, stddev=0.01, seed=None), embeddings_regularizer = l2(reg_mf),
input_length=1)
MF_Embedding_Item = Embedding(input_dim = num_items, output_dim = mf_dim, name = 'mf_embedding_item',
embeddings_initializer = keras.initializers.RandomNormal(mean=0.0, stddev=0.01, seed=None), embeddings_regularizer = l2(reg_mf),
input_length=1)
MLP_Embedding_User = Embedding(input_dim = num_users, output_dim = int(layers[0]/2), name = "mlp_embedding_user",
embeddings_initializer = keras.initializers.RandomNormal(mean=0.0, stddev=0.01, seed=None), embeddings_regularizer = l2(reg_layers[0]),
input_length=1)
MLP_Embedding_Item = Embedding(input_dim = num_items, output_dim = int(layers[0]/2), name = 'mlp_embedding_item',
embeddings_initializer = keras.initializers.RandomNormal(mean=0.0, stddev=0.01, seed=None), embeddings_regularizer = l2(reg_layers[0]),
input_length=1)
# MF part
mf_user_latent = Flatten()(MF_Embedding_User(user_input))
mf_item_latent = Flatten()(MF_Embedding_Item(item_input))
mf_vector = keras.layers.Multiply()([mf_user_latent, mf_item_latent])
# MLP part
mlp_user_latent = Flatten()(MLP_Embedding_User(user_input))
mlp_item_latent = Flatten()(MLP_Embedding_Item(item_input))
mlp_vector = keras.layers.Concatenate(axis=-1)([mlp_user_latent, mlp_item_latent])
for idx in range(1, num_layer):
mlp_vector = Dense(layers[idx],
activation='relu',
kernel_regularizer = l2(reg_layers[idx]),
bias_regularizer = l2(reg_layers[idx]),
name="layer%d" %idx)(mlp_vector)
# Concatenate MF and MLP parts
mf_vector = Lambda(lambda x: x * alpha)(mf_vector)
mlp_vector = Lambda(lambda x : x * (1 - alpha))(mlp_vector)
predict_vector = keras.layers.Concatenate(axis=-1)([mf_vector, mlp_vector])
# Final prediction layer
prediction = Dense(1,
activation='sigmoid',
kernel_initializer='lecun_uniform',
bias_initializer ='lecun_uniform',
name = "prediction")(predict_vector)
model = keras.Model(inputs=[user_input, item_input], outputs=[prediction])
return model
def generate_data(num_user, num_item, count=100):
user_input = []
item_input = []
labels = []
for _ in range(count):
user = np.random.randint(0,num_user)
item = np.random.randint(0,num_item)
label = np.random.randint(0,2)
user_input.append(user)
item_input.append(item)
labels.append(label)
return np.asarray(user_input), np.asarray(item_input), np.asarray(labels)
def test_model():
num_user = 1000000
num_item = 100000
count = 10000
user_input, item_input, labels = generate_data(num_user, num_item, count)
model = get_model(num_user, num_item)
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.BinaryCrossentropy()
)
# Callbacks
callbacks = [ tf.keras.callbacks.TensorBoard(log_dir='tb-logs') ]
model.fit([user_input, item_input], labels, batch_size=256, epochs=3, callbacks=callbacks)
if __name__ == "__main__":
print("Tensorflow version: ", tf.__version__)
test_model()
Other info / logs
The attachment ‘tb-logs.zip’ is the tensorboard logs.
The profiling screenshot of the training on TF 2.0.0-rc0.
The profiling screenshot of the training on TF 1.14.
About this issue
- Original URL
- State: closed
- Created 5 years ago
- Reactions: 1
- Comments: 27 (7 by maintainers)
There seems to be a significant slowdown generally when using TF2 fit_generator. It seems to be around a 3x slowdown in my own code between TF1 and TF2. It is easy to reproduce using the “Transfer Learning with TFHub” example from the TF2 official tutorials on Collab: https://www.tensorflow.org/beta/tutorials/images/hub_with_keras
To reproduce it, all I did was change model.fit to model.fit_generator. I ran these cases for both TF2 and TF1. TF1 is via this change to the first code cell:
%tensorflow_version 1.xHere’s the training runs for the four cases:
With TF1, there is no difference between fit and fit_geneator as you might hope. TF2 seems slower in general and fit_generator in particular is 3x slower than TF1–at least for this tutorial and my own code.
BTW, Collab is using TF2 RC1 at the moment:
Thanks to all.
I’ve tried
tf.compat.v1.disable_eager_execution()andmodel.fit(x=generator, ...)with and without tf.distribute.MirroredStrategy but no help.I think the key problem is the large
input_dimoftf.keras.layers.Embeddingand training with the generator.The following cases are all tested with GPU on TF 2.0.0rc2 compared with TF 1.14.
input_dim,model.fitwithout generator, without tf.distribute.MirroredStrategy. [Fast]input_dim,model.fitwithout generator, without tf.distribute.MirroredStrategy. [Slow]input_dim,model.fitwithout generator, with tf.distribute.MirroredStrategy. [Fast]input_dim,model.fitwith generator, without tf.distribute.MirroredStrategy. [Slow]input_dim,model.fitwith generator, with tf.distribute.MirroredStrategy. [Slow]Here the pseudo code I have tried.
@tabacof Hi, I created the other issue linked.
There are two current resolutions to the issues people were having there; Adding the line
tf.compat.v1.disable_eager_execution()right afterimport tfor switching tomodel.fit(when using TF 2.0You say that you don’t believe the issue is because of eager execution, the easiest way to prove that is to add the first fix
tf.compat.v1.disable_eager_execution()right after importing TF. If this does not improved performance, then that should put to rest the eager execution argument.The issue I encountered is that
fit_generatoris kicking it into eager execution no matter what as robeita says. And in my experience, eager execution is much slower in every case.I hope that this can help you isolate the issue so that the cause can be identified.
I have the same problem,Tensorflow version is 2.5.0.
ReadVariableOptook a long time,and unstable memory usage.Just upgraded to TF 2.2 . Having huge performance issues with keras models.
Update : Disabled eager execution and changed all my inputs to the
model.predict()function from tensors to numpy arrays. Looks like its much faster now.Update 2 : Nevermind. Im switching back to 1.14. My summary writer dosent work if i use
tf.compat.v1.disable_eager_execution(). Have no time to deal with all these bugs.Can confirm with @cupdike . I had a similar issue with my own project when switching to TF2 (stable. I waited for the official release a couple days ago), with a 2x to 3x decrease in training time for the same data and code, as compared to TF1. After some Google searching and reading, I then proceeded to implement the code using tf.data.Dataset.from_generator(), instead, which allows me to use model.fit().
Unfortunately there was 0 performance benefit either way.
As for some pseudocode (posting here just in case someone can point out something fundamentally wrong with my setup), my fit_generator version of my code went something like this below. All my code uses the internal tf.keras instead of the external one:
For the pseudocode using tf.data.Dataset.from_generator():