tensorflow: TFLite Interpreter, allocate_tensors() failed to prepare, not kTFLiteInt8/Uint8
System information
- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): No
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 16.04
- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device:
- TensorFlow installed from (source or binary): binary
- TensorFlow version (use command below): v1.14.0-rc1-22-gaf24dc91b5 1.14.0
- Python version: 3.6.3
- Bazel version (if compiling from source):
- GCC/Compiler version (if compiling from source):
- CUDA/cuDNN version:
- GPU model and memory:
Describe the current behavior
The graph only consist of tf.split(), where I pin down to for this issue.
After quantization with representative_dataset(), the interpreter fail to allocate_tensor().
RuntimeError: tensorflow/lite/kernels/dequantize.cc:62 op_context.input->type == kTFLiteUInt8 || op_context.input->type == kTFLiteInt8 was not true.Node number 0 (DEQUANTIZE) failed to prepare.
I assume tf.split() cannot be quantize, and nothing to be quantize actually, since if I add tf.lite.OpsSet.TFLITE_BUILTINS_INT8 to fully quantize into INT8, it tell me SPLIT_V is not supported.
So this simple graph should not have any quantize/dequantize at tf.split ops?
Thus checking type if is Int8 and has dequantize layer here seems not to make sense?
Describe the expected behavior Interpreter sucessfully
Code to reproduce the issue
inputs_raw = tf.placeholder(tf.float32, shape=[1, 32, 32, 1], name='inputs_raw')
outputs = tf.split(value = inputs_raw, num_or_size_splits = 2, axis = 1)[0]
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
converter = lite.TFLiteConverter.from_session(sess, [inputs_raw], [outputs])
converter.optimizations = [lite.Optimize.DEFAULT]
def representative_data_gen():
for i in range(1):
yield [np.random.random_sample((1, 32, 32, 1)).astype(np.float32)]
#yield [sess.run(tf.random.normal(inputs_raw.get_shape(), dtype = tf.float32, seed = 1))] # both have issue
converter.representative_dataset = representative_data_gen
tflite_model = converter.convert()
open("converted_model_quant_test.tflite", "wb").write(tflite_model)
interpreter = lite.Interpreter(model_path = "converted_model_quant_test.tflite")
nterpreter.allocate_tensors()
Other info / logs Traceback (most recent call last): File “main.py”, line 532, in <module> interpreter.allocate_tensors() File “/proj/gpu_xxx/.local/lib/python3.6/site-packages/tensorflow/lite/python/interpreter.py”, line 95, in allocate_tensors return self._interpreter.AllocateTensors() File “/proj/gpu_xxx/.local/lib/python3.6/site-packages/tensorflow/lite/python/interpreter_wrapper/tensorflow_wrap_interpreter_wrapper.py”, line 106, in AllocateTensors return _tensorflow_wrap_interpreter_wrapper.InterpreterWrapper_AllocateTensors(self) RuntimeError: tensorflow/lite/kernels/dequantize.cc:62 op_context.input->type == kTfLiteUInt8 || op_context.input->type == kTfLiteInt8 was not true.Node number 0 (DEQUANTIZE) failed to prepare.
About this issue
- Original URL
- State: closed
- Created 5 years ago
- Reactions: 9
- Comments: 31 (2 by maintainers)
Same issue here with tensorflow-cpu==2.3.0rc0
@milinddeore Same for me! You might have to upgrade
pipif you can‘t findv1.15.0. I believe this issue can be closed @jianlijianliI got the same issue on
v1.14.0, upgraded tov1.15.0fixed it.Any update on this? It’s been a year.
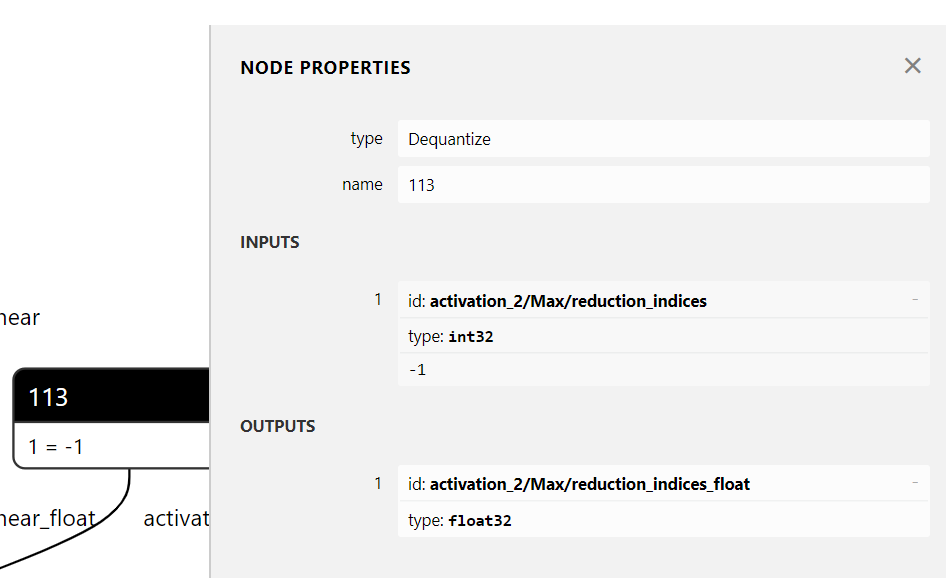
Same problem here. Using keras version of deeplabv3 with mobilenetv2 backbone, this error occurs on node 113, which is a dequantize node who is trying to convert the reduction index for a ReduceMax operation.
RuntimeError: tensorflow/lite/kernels/dequantize.cc:62 op_context.input->type == kTfLiteUInt8 || op_context.input->type == kTfLiteInt8 was not true.Node number 113 (DEQUANTIZE) failed to prepare.Here is the visualization of node 113 in Netron. It has int32 as input type, that must be the problem. Could I just modify the graph to hard code a float32 there?