tensorflow: `tf.keras.model_to_estimator` doesn't work well in evaluating
System information
-
Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Yes
-
OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Linux Ubuntu 16.04
-
TensorFlow installed from (source or binary): I use docker tensorflow/tensorflow:1.7.0-rc1-devel-gpu-py3
-
TensorFlow version (use command below): 1.7.0-rc1
-
Python version: 3.5
-
Bazel version (if compiling from source):
-
GCC/Compiler version (if compiling from source):
-
CUDA/cuDNN version: CUDA9.0
-
GPU model and memory: 1080Ti(12GB)
-
Exact command to reproduce: see my gist below
Describe the problem
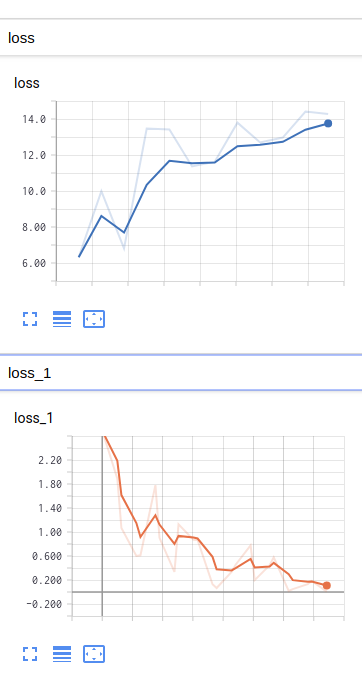
I used networks in tf.keras.applications and tf.keras.model_to_estimator. I noticed that training loss gets low but validation loss doesn’t when I don’t use pretrained model and train from scratch. I doubted overfitting so I tried evalutating on training dataset. And get large validation loss althogh traing loss gets low inspite of same dataset. I think parameters of BatchNormalization are not updated when use model_to_estimator. Isn’t it a bug?
Source code / logs
https://gist.github.com/dhgrs/781eb8bec824c63cc4b626bf04cd4446
About this issue
- Original URL
- State: closed
- Created 6 years ago
- Reactions: 3
- Comments: 68 (63 by maintainers)
@martinwicke I understand the we have many bugs here. But sometimes a quick workaround instead of waiting 3 months could be useful and it probably not require too much time as fixing it expecially if it has a low internal priority in the stack (that it is not visibile by us with specific labels).
@ewilderj Generally I really hope that we could improve this process with a fast triage pass and then a bugfix cause we are always in the middle of switching api going from high to low and back also if not required just waiting for a fix (i.e. see also the warm_start issues at https://github.com/tensorflow/tensorflow/issues/20057). This really happen with API that are not used daily in Brain or other Google TF teams (I’am not internal it is just a github behaviour reverse engineering).
@tanzhenyu Thanks, ping us when you will have an update so that we will switch back from the workaround.
This is probably a bug introduced when we made it possible to use tensor inputs directly instead of feeding. Instead of looking through all _feed_inputs to find relevant updates, we have to look through all inputs, whether is_placeholder is true or not.
Medium term, we have to refactor this to not rely on this brittle double-accounting – using functions to encode updates should help (cc @alextp)
Can someone just explain what is the perimeter of this ticket? Is it a recognized bug?