tensorflow: Tensorflow eager version fails, while Tensorflow static graph works
System information
- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): no
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Archlinux
- TensorFlow installed from (source or binary): repository
- TensorFlow version (use command below): 1.11
- Python version: 3.7
- CUDA/cuDNN version: cuda 10, cudnn 7
- GPU model and memory: nvidia 1080ti
Describe the current behavior
I’m porting a ML model ( https://github.com/samet-akcay/ganomaly ) implemented in pytorch to tensorflow (using the keras layers, knowing that tf 2.0 will come soon).
The first implementation was using the eager version to do the train, but the model collapses, nothing works.
The same model definition has been reused but it has been used to first define a static graph and then train the model: it works perfectly.
Describe the expected behavior
The static graph version and the eager version should have the same behavior.
Code to reproduce the issue
Model description (same for both eager and static)
from typing import Dict
import tensorflow as tf
import tensorflow.keras as k
import numpy as np
conv_initializer = k.initializers.random_normal(0.0, 0.02)
batchnorm_inizializer = k.initializers.random_normal(1.0, 0.02)
eps = 1e-5
momentum = 0.99
class Decoder(k.models.Model):
"""
Decoder (Generator) Network
"""
def __init__(self, output_depth: int = 1):
super(Decoder, self).__init__()
self.conv1 = k.layers.Conv2DTranspose(
filters=256,
kernel_size=(4, 4),
strides=(1, 1),
kernel_initializer=conv_initializer,
input_shape=(-1, 1, 1, 100),
use_bias=False,
)
self.batchnorm1 = k.layers.BatchNormalization(
epsilon=eps,
momentum=momentum,
beta_initializer=batchnorm_inizializer,
gamma_initializer=batchnorm_inizializer,
)
self.conv2 = k.layers.Conv2DTranspose(
filters=128,
kernel_size=(4, 4),
strides=(2, 2),
padding="same",
kernel_initializer=conv_initializer,
use_bias=False,
)
self.batchnorm2 = k.layers.BatchNormalization(
epsilon=eps,
momentum=momentum,
beta_initializer=batchnorm_inizializer,
gamma_initializer=batchnorm_inizializer,
)
self.conv3 = k.layers.Conv2DTranspose(
filters=64,
kernel_size=(4, 4),
strides=(2, 2),
padding="same",
kernel_initializer=conv_initializer,
use_bias=False,
)
self.batchnorm3 = k.layers.BatchNormalization(
epsilon=eps,
momentum=momentum,
beta_initializer=batchnorm_inizializer,
gamma_initializer=batchnorm_inizializer,
)
self.conv4 = k.layers.Conv2DTranspose(
filters=output_depth,
kernel_size=(4, 4),
strides=(2, 2),
padding="same",
kernel_initializer=conv_initializer,
use_bias=False,
)
def call(self, x, training=True):
# print("X.SHAPE: ", x.shape)
x = self.conv1(x)
x = self.batchnorm1(x, training=training)
x = tf.nn.relu(x)
x = self.conv2(x)
x = self.batchnorm2(x, training=training)
x = tf.nn.relu(x)
x = self.conv3(x)
x = self.batchnorm3(x, training=training)
x = tf.nn.relu(x)
x = self.conv4(x)
x = tf.nn.tanh(x) # image
# print("Decoder call output size: ", x.shape)
return x
class Encoder(k.models.Model):
def __init__(self, latent_dimensions: int = 100):
super(Encoder, self).__init__()
self.conv0 = k.layers.Conv2D(
filters=64,
kernel_size=(4, 4),
strides=(2, 2),
padding="same",
kernel_initializer=conv_initializer,
input_shape=(-1, 32, 32, 1),
use_bias=False,
)
self.conv1 = k.layers.Conv2D(
filters=128,
kernel_size=(4, 4),
strides=(2, 2),
padding="same",
kernel_initializer=conv_initializer,
use_bias=False,
)
self.batchnorm1 = k.layers.BatchNormalization(
epsilon=eps,
momentum=momentum,
beta_initializer=batchnorm_inizializer,
gamma_initializer=batchnorm_inizializer,
)
self.conv2 = k.layers.Conv2D(
filters=256,
kernel_size=(4, 4),
strides=(2, 2),
padding="same",
kernel_initializer=conv_initializer,
use_bias=False,
)
self.batchnorm2 = k.layers.BatchNormalization(
epsilon=eps,
momentum=momentum,
beta_initializer=batchnorm_inizializer,
gamma_initializer=batchnorm_inizializer,
)
self.conv3 = k.layers.Conv2D(
filters=latent_dimensions,
kernel_size=(4, 4),
strides=(1, 1),
padding="valid",
kernel_initializer=conv_initializer,
use_bias=False,
)
def call(self, x, training=True):
# x = self.conv0(x, input_shape=x.shape[1:])
x = self.conv0(x)
x = tf.nn.leaky_relu(x)
x = self.conv1(x)
x = self.batchnorm1(x, training=training)
x = tf.nn.leaky_relu(x)
x = self.conv2(x)
x = self.batchnorm2(x, training=training)
x = tf.nn.leaky_relu(x)
x = self.conv3(x)
# x = tf.nn.tanh(x) # latent space unitary sphere [-1,1] TODO: temporary?
# print("Encoder call output size: ", x.shape)
return x
class Discriminator(k.models.Model):
def __init__(self):
super(Discriminator, self).__init__()
self.conv0 = k.layers.Conv2D(
filters=64,
kernel_size=(4, 4),
strides=(2, 2),
padding="same",
kernel_initializer=conv_initializer,
use_bias=False,
)
self.conv1 = k.layers.Conv2D(
filters=128,
kernel_size=(4, 4),
strides=(2, 2),
padding="same",
kernel_initializer=conv_initializer,
use_bias=False,
)
self.batchnorm1 = k.layers.BatchNormalization(
epsilon=eps,
momentum=momentum,
beta_initializer=batchnorm_inizializer,
gamma_initializer=batchnorm_inizializer,
)
self.conv2 = k.layers.Conv2D(
filters=256,
kernel_size=(4, 4),
strides=(2, 2),
padding="same",
kernel_initializer=conv_initializer,
use_bias=False,
)
self.batchnorm2 = k.layers.BatchNormalization(
epsilon=eps,
momentum=momentum,
beta_initializer=batchnorm_inizializer,
gamma_initializer=batchnorm_inizializer,
)
self.conv3 = k.layers.Conv2D(
filters=1,
kernel_size=(4, 4),
strides=(1, 1),
padding="valid",
kernel_initializer=conv_initializer,
use_bias=False,
)
def call(self, x, training=True):
x = self.conv0(x)
x = tf.nn.leaky_relu(x)
x = self.conv1(x)
x = self.batchnorm1(x, training=training)
x = tf.nn.leaky_relu(x)
x = self.conv2(x)
x = self.batchnorm2(x, training=training)
x = tf.nn.leaky_relu(x)
x = self.conv3(x)
return x
Also, the following variable definitions are shared in both the eager and static implementations
global_step = tf.train.get_or_create_global_step()
generator_optimizer = tf.train.AdamOptimizer(2e-4, 0.5)
discriminator_optimizer = tf.train.AdamOptimizer(2e-4, 0.5)
discirminator = Discriminator()
g_encoder = Encoder()
g_decoder = Decoder()
encoder = Encoder()
Eager training
I show just a single training update, that’s run in a training loop
# Discriminator training
with tf.GradientTape() as tape:
discriminator.trainable = True
disc_x = tf.squeeze(discriminator(x, training=False), axis=[1, 2])
disc_real_loss = tf.losses.sigmoid_cross_entropy( # discriminator loss on result disc_x
multi_class_labels=tf.ones_like(disc_x), logits=disc_x
)
g_encoder.trainable = False
g_decoder.trainable = False
# recreate the data (=> x_hat), starting from real data x
z = g_encoder(x, training=True) # Not training
x_hat = g_decoder(z, training=True) # Not training
disc_x_hat = tf.squeeze(discriminator(x_hat, training=False), axis=[1, 2])
disc_gen_loss = tf.losses.sigmoid_cross_entropy( # discriminator loss on result disc_x_hat
multi_class_labels=tf.zeros_like(disc_x_hat), logits=disc_x_hat
)
disc_loss = disc_real_loss + disc_gen_loss
discriminator_gradients = tape.gradient(
disc_loss, discriminator.trainable_variables
)
discriminator_optimizer.apply_gradients(
zip(discriminator_gradients, discriminator.trainable_variables)
)
# Generator Training
with tf.GradientTape() as tape:
# err_g_bce
g_encoder.trainable = True
g_decoder.trainable = True
encoder.trainable = True
z = g_encoder(x, training=True)
x_hat = g_decoder(z, training=True)
disc_x_hat = tf.squeeze(
discriminator(x_hat, training=False), axis=[1, 2]
)
bce_loss = tf.losses.sigmoid_cross_entropy(
multi_class_labels=tf.ones_like(disc_x_hat),
logits=disc_x_hat, # G wants to generate reals so ones_like
)
l1_loss = tf.losses.absolute_difference(x, x_hat)
# err_g_enc
z_hat = encoder(x_hat, training=True)
l2_loss = tf.losses.mean_squared_error(z, z_hat)
gen_loss = 1* bce_loss + 50 * l1_loss + 1 * l2_loss
trainable_variable_list = (
g_encoder.trainable_variables
+ g_decoder.trainable_variables
+ encoder.trainable_variables
)
generator_gradients = tape.gradient(gen_loss, trainable_variable_list)
generator_optimizer.apply_gradients(
zip(generator_gradients, trainable_variable_list),
global_step=global_step,
)
Static graph training
First I show the graph definition,then how is used in the training loop
Graph def
# Discriminator on real
D_x = discriminator(x)
D_x = tf.squeeze(D_x, axis=[1, 2])
# Generate fake
z = g_encoder(x)
x_hat = g_decoder(z)
D_x_hat = discriminator(x_hat)
D_x_hat = tf.squeeze(D_x_hat, axis=[1, 2])
## Discriminator
d_loss = tf.losses.sigmoid_cross_entropy(
multi_class_labels=tf.ones_like(D_x), logits=D_x) + tf.losses.sigmoid_cross_entropy(
multi_class_labels=tf.zeros_like(D_x_hat), logits=D_x_hat)
# encode x_hat to z_hat
z_hat = encoder(x_hat)
## Generator
bce_loss = tf.losses.sigmoid_cross_entropy(tf.ones_like(D_x_hat), D_x_hat)
l1_loss = tf.losses.absolute_difference(x, x_hat)
l2_loss = tf.losses.mean_squared_error(z, z_hat)
g_loss = 1 * bce_loss + 1 * l1_loss + 1 * l2_loss
global_step = tf.train.get_or_create_global_step()
# Define the D train op
train_d = tf.train.AdamOptimizer(
lr, beta1=0.5).minimize(
d_loss, var_list=D.trainable_variables)
# train G_e G_d E
train_g = tf.train.AdamOptimizer(
lr, beta1=0.5).minimize(
g_loss,
global_step=global_step,
var_list=g_encoder.trainable_variables + g_decoder.trainable_variables +
encoder.trainable_variables)
And this is what’s inside the training loop (executed in a MonitoredSession):
# extract from tf.data.Dataset, x is a placeholder and x_ is the iterator.get_next
real = sess.run(x_)
feed_dict = {x: real}
# train D
_, d_loss_value = sess.run([train_d, d_loss], feed_dict)
# train G+E
_, g_loss_value, step = sess.run([train_g, g_loss, global_step],
feed_dict)
The model definition is the same, the loss definition is the same, the training steps and the same, the only difference is the eager mode enabled or disabled. The results with eager on are:
D loss: collapses to zero, that’s wrong since its aim is to stay around 0.5

Generated images: wrong, bad reconstructions since D collapsed

While when eager is off, the discriminator loss looks correct and the generated output are the one expected:
D loss:
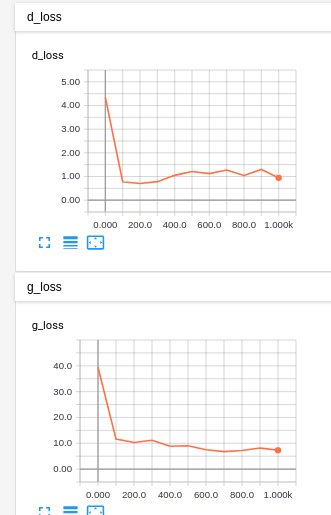
Generated output:

About this issue
- Original URL
- State: closed
- Created 6 years ago
- Comments: 25 (13 by maintainers)
FYI, we are addressing this problem by a comprehensive revamp in RFC tensorflow/community#38. Please comment on that.