tensorflow: Prefetch to GPU: prefetch_to_device does not do anything (from_generator), tf.data.Dataset API unclear
System information
- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Yes
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 20.04
- TensorFlow installed from (source or binary): Official 2.4-nightly docker (version 2.4.0-dev20201005)
- TensorFlow version (use command below): Official 2.4-nightly docker (version 2.4.0-dev20201005)
- Python version: 3.6.9
- CUDA/cuDNN version: CUDA: 11.1, cuDNN: 8.0.2
- GPU model and memory: Nvidia GTX 1080 Ti, 11170MiB
The API concerning moving CPU to GPU with prefetching extremely unclear using tf.data.Dataset. The function ‘prefetch_to_device’ simply does not work, even though it was stated that it should be fixed by TF 2.3 or TF 2.4 in the following issue: issue 35563
In order to show the behavior, I have written a standalone test that goes over four options:
- 0: only use ‘prefetch_to_device’
- 1: Use ‘copy_to_device’
- 2: Use ‘copy_to_device’ and prefetch
- 3: Use ‘copy_to_device’ and ‘prefetch_to_device’
I would expect options 0, 2, and 3 to be almost identical. However, only option 2 does actually the indented behavior. (Option 1 does not do prefetching, so in that sense it also does what it is intended for).
I am also not even 100% sure if option 2 is optimal. It does seem that the other GPU ops are blocked during the MemCpy. It could be that it only looks as if it is covered. But I do not have the expertise to judge this case. In terms of timings I did notice that option 2 was the fastest:
Option prefetch_gpu
data/logs/pa_20201009-082628_prefetch_gpu
Time lapsed= 0:00:01.177912
Option copy
data/logs/pa_20201009-082628_copy
Time lapsed= 0:00:00.916617
Option copy_prefetch
data/logs/pa_20201009-082628_copy_prefetch
Time lapsed= 0:00:00.831833
Option copy_prefetch_gpu
data/logs/pa_20201009-082628_copy_prefetch_gpu
Time lapsed= 0:00:00.926764
Standalone code to reproduce the issue
import os
import datetime
from tqdm import tqdm
import numpy as np
import tensorflow as tf
print('TF version', tf.__version__)
@tf.function
def do_stuff(wmat, tf_var):
A = tf.matmul(wmat + 1, tf.transpose(wmat))
error = tf.reduce_mean(tf_var)
return error, A
exp_uuid = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
n_batches = 20
weights = [None] * n_batches
for i in range(n_batches):
weights[i] = tf.constant(np.random.rand(2000,10000), dtype=tf.float32)
def gen():
for i in weights:
yield i
option_names = ['prefetch_gpu', 'copy', 'copy_prefetch', 'copy_prefetch_gpu']
for option in range(4):
dataset = tf.data.Dataset.from_generator(gen, output_types=(tf.float32))
if option == 0:
## Option 1: prefetch_gpu
#
## output:
## weights device /job:localhost/replica:0/task:0/device:CPU:0
## weights device after identity /job:localhost/replica:0/task:0/device:GPU:0
gpu_transform = tf.data.experimental.prefetch_to_device('/gpu:0')
dataset.apply(gpu_transform)
elif option == 1:
## Option 1: only copy
#
## output:
## weights device /job:localhost/replica:0/task:0/device:GPU:0
dataset = dataset.apply(tf.data.experimental.copy_to_device("/gpu:0"))
elif option == 2:
## Option 2: copy + prefetch
## as suggested in https://github.com/tensorflow/tensorflow/issues/35563#issuecomment-602160568
#
## output:
## weights device /job:localhost/replica:0/task:0/device:GPU:0
dataset = dataset.apply(tf.data.experimental.copy_to_device("/gpu:0"))
with tf.device("/gpu:0"):
dataset = dataset.prefetch(1)
elif option == 3:
## Option 3: copy + prefetch_gpu
#
## output:
## weights device /job:localhost/replica:0/task:0/device:GPU:0
dataset = dataset.apply(tf.data.experimental.copy_to_device("/gpu:0"))
gpu_transform = tf.data.experimental.prefetch_to_device('/gpu:0')
dataset.apply(gpu_transform)
tf_var = tf.Variable(np.zeros(3))
adam = tf.keras.optimizers.Adam(1e-4)
logpath = os.path.join('data', 'logs', 'pa_' + exp_uuid + '_' + option_names[option])
tf.profiler.experimental.start(logpath)
start = datetime.datetime.now()
for b, wmat in tqdm(enumerate(dataset)):
with tf.GradientTape() as tape:
if b == 0:
print('\n weights device', wmat.device)
print('')
if option == 0:
wmat = tf.identity(wmat, 'move_to_gpu')
if b == 0:
print('weights device after identity', wmat.device)
print('')
# Do some calculations
result = do_stuff(wmat, tf_var)
grads = tape.gradient(result[0], [tf_var])
adam.apply_gradients(zip(grads, [tf_var]))
stop = datetime.datetime.now()
tf.profiler.experimental.stop()
print(f'\nOption {option_names[option]}')
print(logpath)
print('Time lapsed=', stop - start)
Option 0: prefetch_to_device
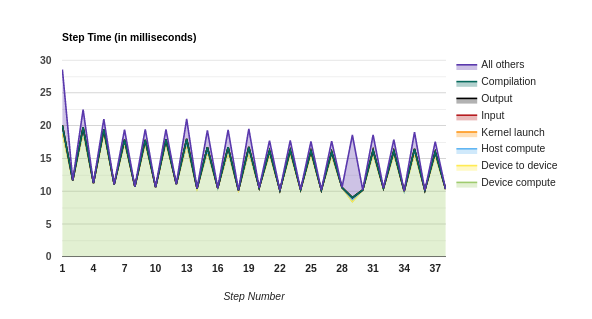

Option 1: copy_to_device
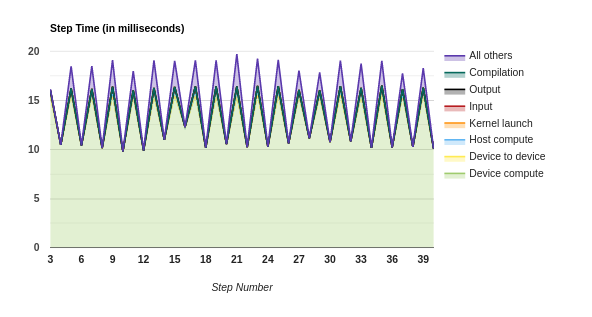

Option 2: copy_to_device + prefetch
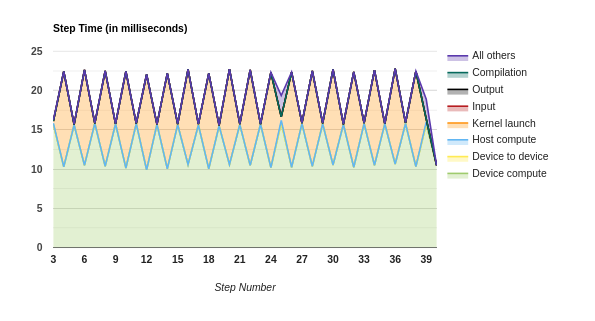

Option 3: copy_to_device + prefetch_to_device
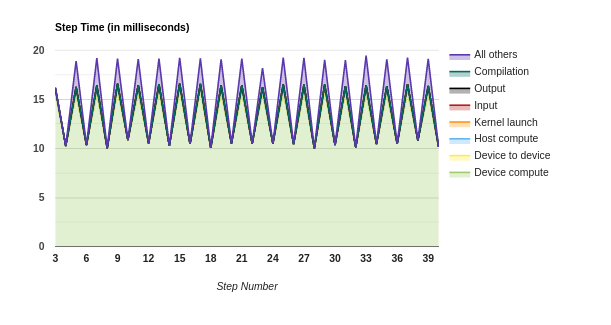

Files: pa_20201009-082628_prefetch_gpu.zip pa_20201009-082628_copy.zip pa_20201009-082628_copy_prefetch.zip pa_20201009-082628_copy_prefetch_gpu.zip
About this issue
- Original URL
- State: open
- Created 4 years ago
- Reactions: 6
- Comments: 19 (5 by maintainers)
prefetch_to_deviceworks when the data produced by the input pipeline is allocated in pinned host memory.map().batch()is currently the option to achieve this through tf.data. This is not documented anywhere and is a subtle implementation detail: https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/kernels/data/experimental/map_and_batch_dataset_op.cc#L517I plan to investigate whether there is any downside to making all tf.data allocations use pinned host memory and if not, make this available more broadly. Note that this might not address the issue for input pipelines that do not allocate memory through tf.data. For instance, the example in the original description of this issue performs the memory allocation outside of tf.data.
TLDR:
prefetch_to_deviceworks as expected, when the data produced by the input pipeline is allocated in pinned host memory.I have recently investigated this issue.
First, to compare
copy_to_deviceandprefetch_to_deviceperformance, I have modified the original repro as follows:Using this program I have collected the following traces:
copy_to_device
prefetch_to_device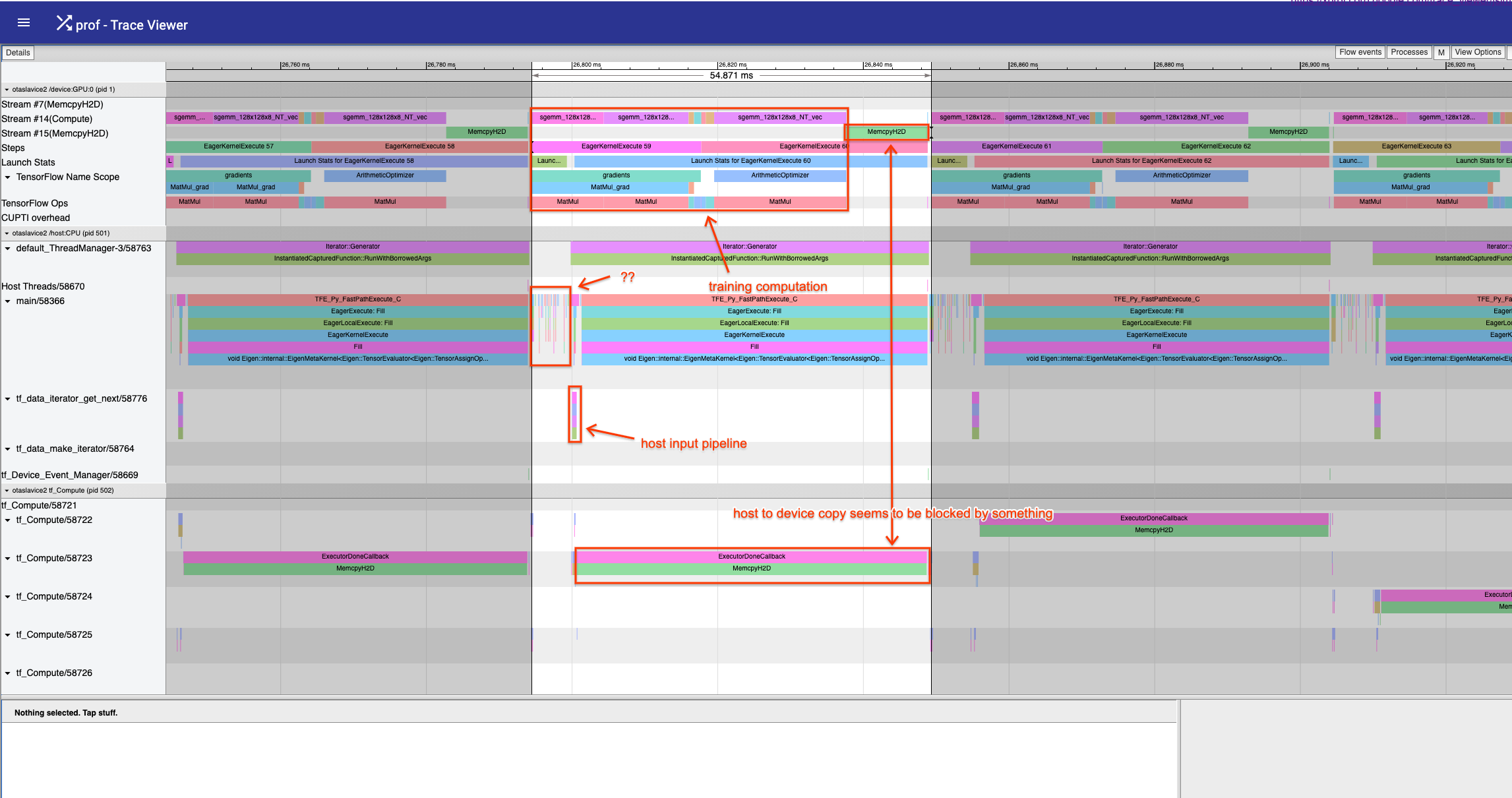
While a single step of the
prefetch_to_deviceversion of the program is slightly faster (based on the trace view measurement as opposed to TF profiler overview, which might not be correctly detecting “steps” for this program) – 54.9ms vs 62.6ms – the trace also shows that the data copy seems to be delayed by something.Next, I investigated whether making sure that the input pipeline produces data that is allocated in pinned host memory, resolves the issue.
Currently, tf.data only allocates pinned host memory for input pipelines that use the
map().batch()pattern. Therefore, I needed to modify the program as follows:These changes end up resolving the issue:
copy_to_device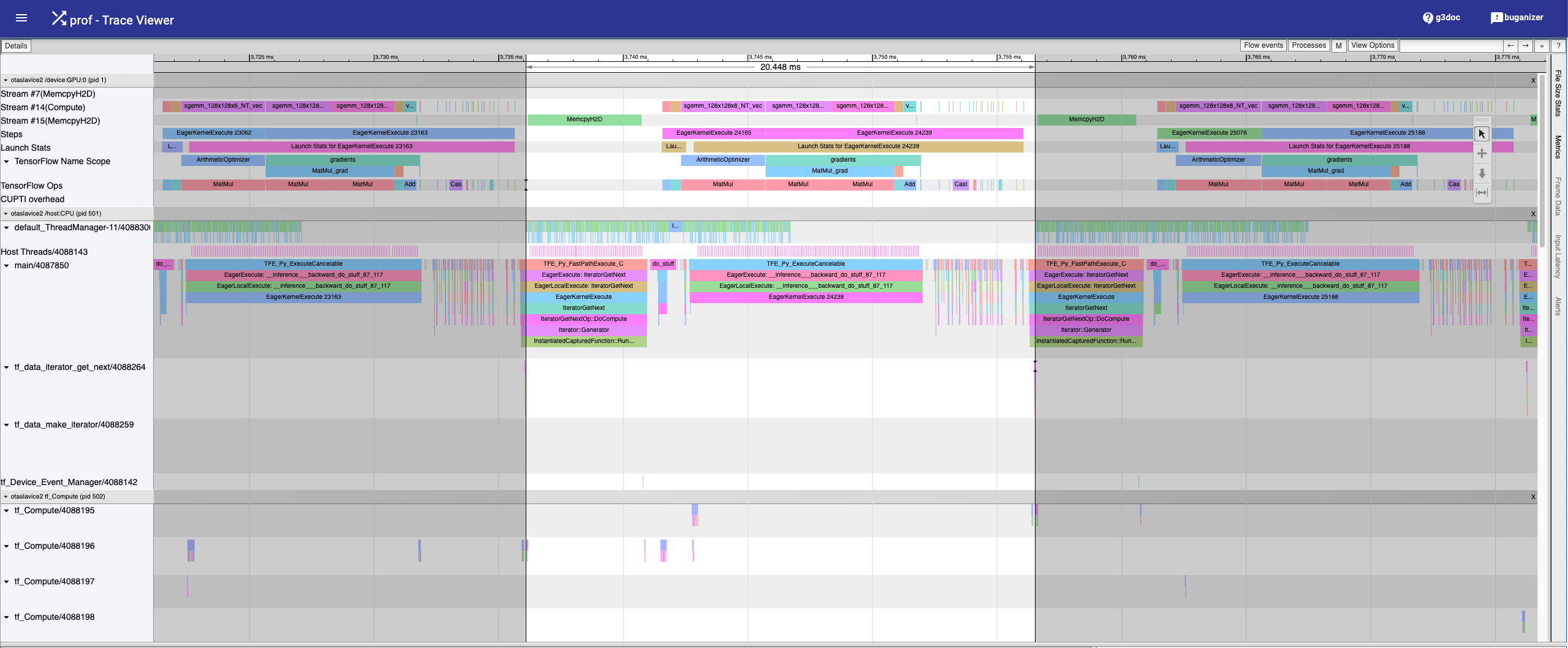
prefetch_to_device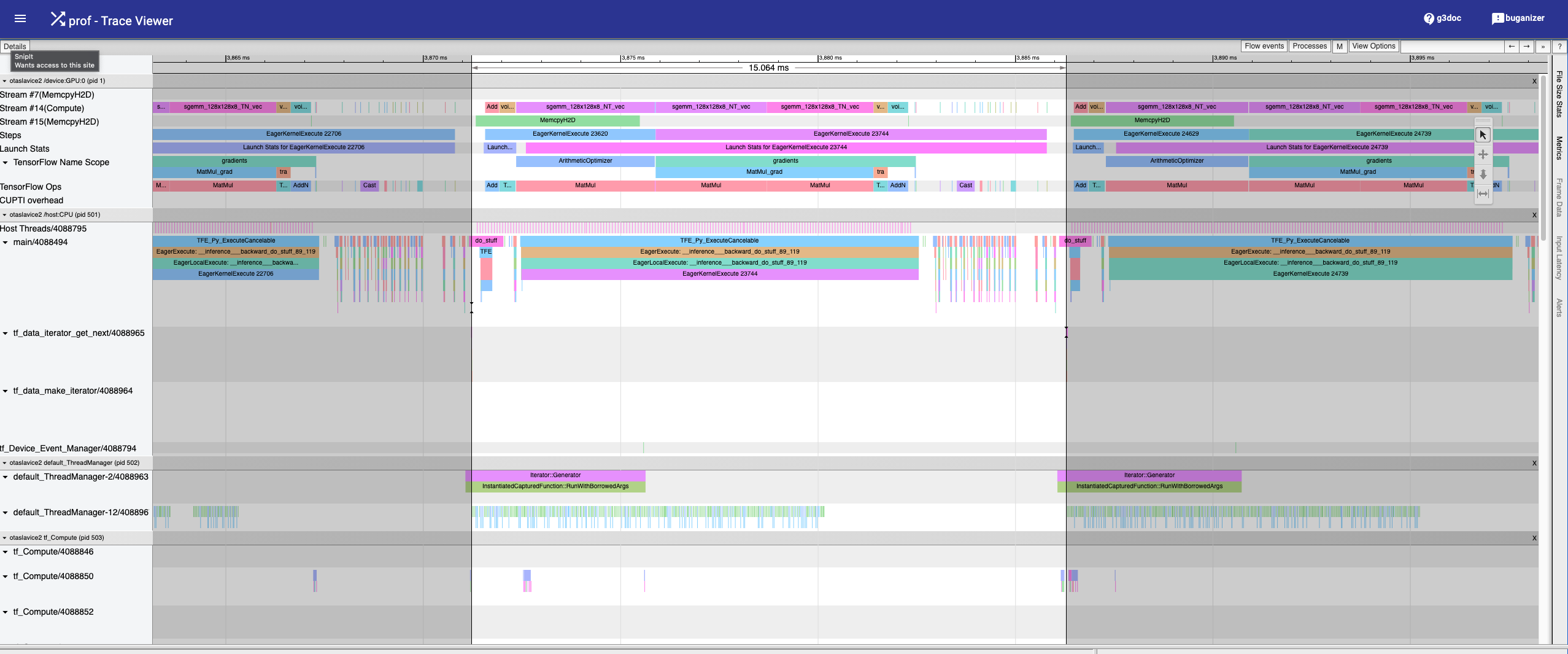
@jsimsa
So the conclusion is:
prefetch_to_deviceactually works, but it needs be to used withmap().batch()to get better performance?And where can I get such information? From TensorFlow source code?
@aaudiber Thank you for taking the time to review this. It’s true that that was a mistake in this example. I can confirm that option 3 (prefetch_to_device) is as fast as option 2 (copy to device + prefetch).
However, I do still see a noticeable time that the GPU is performing nothing else than MemcpyH2D. I am not sure if I’m reading this correctly, but why would that be the case?
@jsimsa i see that you were able to get the tracer to show prefetching (memcpy overlap with gpu compute)
but did you see an actual improvement in training speed?
time_ds(ds)time_ds(pf_ds)time_ds(gpu_pf_ds)all 3 show roughly 8 seconds per 100 steps on colab GPU
Same to me. After using
dataset = dataset.apply(tf.data.experimental.prefetch_to_device(device='/gpu:0', buffer_size=16)), it is faster thandataset = dataset.prefetch(buffer_size=16).But there is still noticeable time spent on
cudaMemcpyH2D. Please see here for more details.Maybe
prefetch_to_devicedoes not reallyprefetch?