tensorflow: keras layers LSTM uses inconsistent dropout approach
System information
- TensorFlow version (use command below): 2.2
Describe the current behavior The input dropout mask is the same for the respective input, forget, update, and output computation.
from the call method in the LSTM class in recurrent_v2.py
dropout_mask = self.get_dropout_mask_for_cell(inputs, training, count=4)
if dropout_mask is not None:
inputs = inputs * dropout_mask[0]
However, the recurrent dropout mask is unique for the input, forget, update, and output computation
h_tm1_i = h_tm1 * rec_dp_mask[0]
h_tm1_f = h_tm1 * rec_dp_mask[1]
h_tm1_c = h_tm1 * rec_dp_mask[2]
h_tm1_o = h_tm1 * rec_dp_mask[3]
If the input dropout mask approach was the intended behavior can someone link me a reference paper that explains why and shouldn’t we at least set the count=1. To me it seems like we are attempting to follow the approach from “A Theoretically Grounded Application of Dropout in Recurrent Neural Networks”
Describe the expected behavior I’d have thought the input dropout mask would be unique to the input, forget, update, and output computation
About this issue
- Original URL
- State: closed
- Created 4 years ago
- Comments: 19 (8 by maintainers)
Thanks for reporting the issue. Let me check the change history and related paper/math, and I will post some updates.
I don’t think stand alone code would help to describe this issue since the issue is heavily embedded into the LSTM implementation. I’ll write the equations which are being performed and what I expect to occur.
Current Behavior
for each sequence the masks $\mathbf{m}_{x}$, $\mathbf{m}_{hi}$, $\mathbf{m}_{hf}$, $\mathbf{m}_{ha}$, and $\mathbf{m}_{ho}$ are sampled then used in the following LSTM update
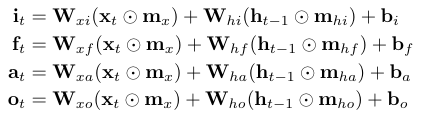
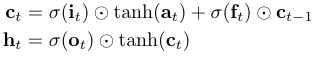
Expected Behavior
I would expect $\mathbf{m}_{xi}$, $\mathbf{m}_{xf}$, $\mathbf{m}_{xa}$, and $\mathbf{m}_{xo}$ to be different for each gate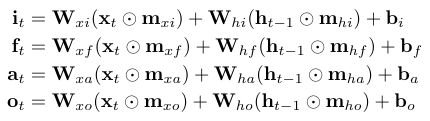
I’m guessing this is not currently being done b/c there is a desire to use the gpu implementation and that doesn’t seem to allow 4 different masked
inputsvalues