bullmq: Stalled/failed jobs stay in queue
We’re seeing something very similar to this issue, where stalled/failed jobs remain in the queue, even when removeOnComplete and removeOnFail are true in the job’s options.
#1042 claims to fix it by not allowing progress updates after a job was removed from the queue (missing job key). The PR was released in v1.68.1, we’re on v1.78.2.
We can work around the issue as mentioned in #977 by periodically clearing the queue ourselves, but it definitely feels like a bug with job scheduler.
In either case, setting the removeOnComplete and removeOnFail flags in job options should make sure the job is removed, even if stalled. Effectively leaving an empty queue if no job is scheduled for a certain amount of time. We see failed jobs in the queue even after having a job scheduler connected and running for >5h:
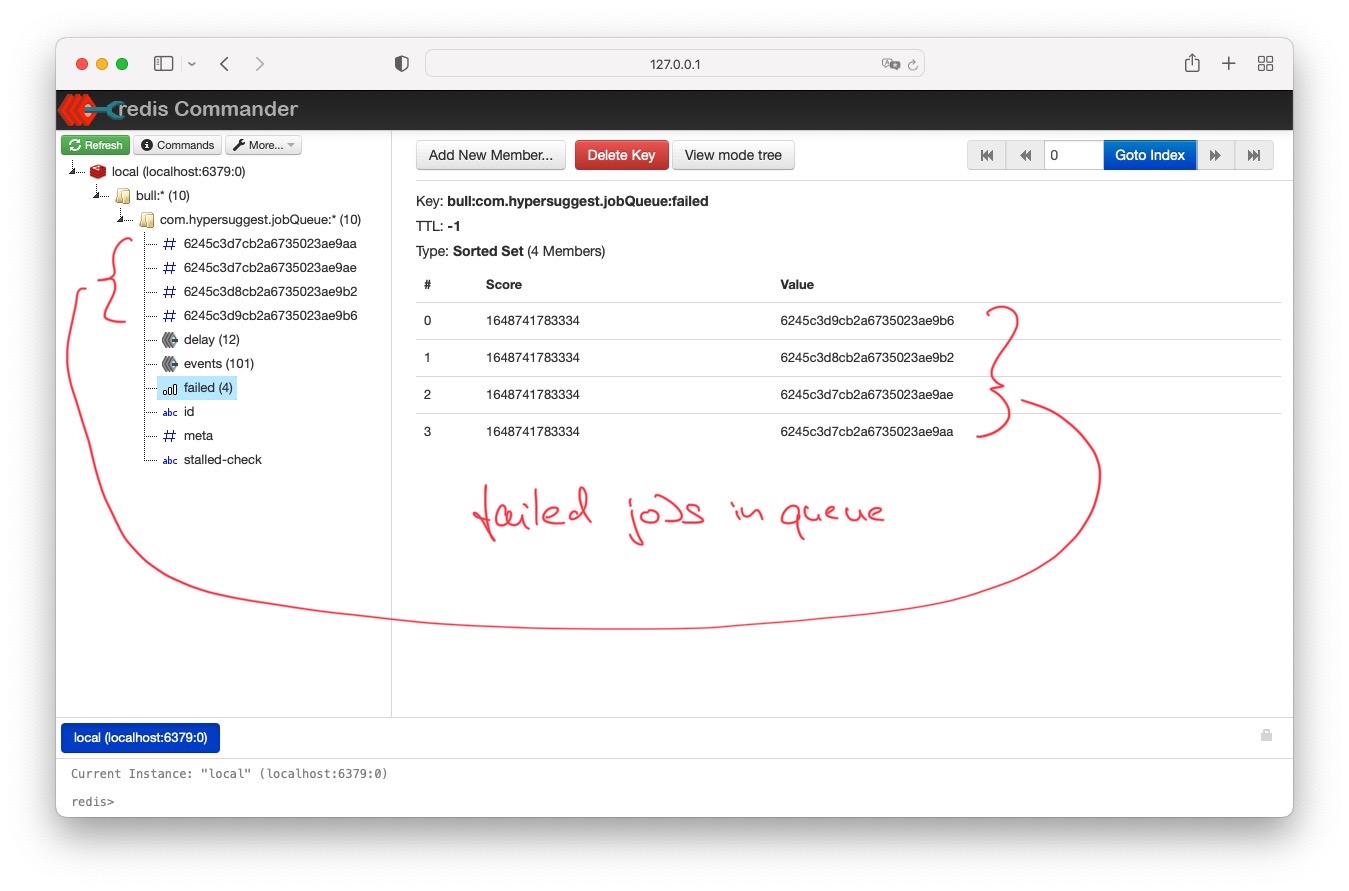
I’ve noticed that the jobs in question have in common that they perform very long running http requests (>1min), but they’re async so stalling should not be caused by that, right?
About this issue
- Original URL
- State: closed
- Created 2 years ago
- Comments: 16 (11 by maintainers)
Commits related to this issue
- fix(stalled): consider removeOnFail when failing jobs (#1225) fixes #1171 — committed to taskforcesh/bullmq by roggervalf 2 years ago
- chore(release): 1.81.2 [skip ci] ## [1.81.2](https://github.com/taskforcesh/bullmq/compare/v1.81.1...v1.81.2) (2022-05-03) ### Bug Fixes * **stalled:** consider removeOnFail when failing jobs ([#12... — committed to taskforcesh/bullmq by semantic-release-bot 2 years ago
@manast Is this change still part of 3.0.0? I’m upgrading from bull and running in to some errors.
We have a similar use-case as Daniel in that I make heavy use of custom jobIds and
removeOnFail: true. I’m running in to a lot ofMissing lock for job <T>: failederrors that then result in (presumably) a stalled job that wasn’t removed and the inability to add new ones until flushing redis.Any help/insight would be appreciated!