hpx: Memory leak when using dataflow icw components
Expected Behavior
Constant (more or less) amount of memory used.
Actual Behavior
Fast increase of memory usage, depending on number of component clients involved in dataflow.
Steps to Reproduce the Problem
I can reproduce the issue I see with my code with the 1d_stencil_7.cpp distributed with HPX.
- Apply fix #4731
- Update code so
heat_partaction depends on a few partitions more instead of the 2 directly neighboring partitions (see diff below) - Run the exe using multiple localities (see script below)
Specifications
- HPX Version: 1.4.1
- Platform (compiler, OS): gcc-7, Kubuntu 18.04
Futher remarks
Some things I learned when hunting for the source of the leak the past week:
- Memory usage does not increase when using a single locality. There seems to be a dependency on the layer handling the transport of component clients.
- The component clients passed into the action do not have to actually be used at the target locality for the memory usage to increase. The issue is visible even when just copying the middle partition and not touching the other ones.
- The amount of memory used by the process is much larger than expected and increases fast
- The amount of memory used increases faster with the number of partitions passed into the action
- Memory usage does not increase when calling the action synchronously
- I used the sliding semaphore in my own code to throttle the generation of tasks, but this had no effect. That is why I think there is a leak somewhere. Also, waiting for partitions to become ready in each iteration (
wait_all) has no effect on increased memory usage over time.
I am very happy to provide more info or do additional testing. My project depends very much on a fix for this issue. It would be great if I could somehow get things going without the increased memory usage killing the process. A local hack is fine 😉
Diff for 1d_stencil_7.cpp
The relevant thing that changed is the number of partitions passed into the action. They are not actually used. Passing more neighboring partitions increases the memory usage over time, a lot.
diff --git a/examples/1d_stencil/1d_stencil_7.cpp b/examples/1d_stencil/1d_stencil_7.cpp
index 1e9672f0ffb..7a798eae2f1 100644
--- a/examples/1d_stencil/1d_stencil_7.cpp
+++ b/examples/1d_stencil/1d_stencil_7.cpp
@@ -33,10 +33,10 @@ double dx = 1.; // grid spacing
inline std::size_t idx(std::size_t i, int dir, std::size_t size)
{
- if(i == 0 && dir == -1)
- return size-1;
- if(i == size-1 && dir == +1)
- return 0;
+ if(dir < 0 && std::abs(dir) > i)
+ return size-(std::abs(dir) - i);
+ if((i + dir) >= size)
+ return (i + dir) - size
HPX_ASSERT((i + dir) < size);
@@ -45,7 +45,7 @@ inline std::size_t idx(std::size_t i, int dir, std::size_t size)
inline std::size_t locidx(std::size_t i, std::size_t np, std::size_t nl)
{
- return i / (np/nl);
+ return static_cast<std::size_t>(std::floor(i / ((double)np/nl)));
}
///////////////////////////////////////////////////////////////////////////////
@@ -258,8 +258,11 @@ struct stepper
//[stepper_7
// The partitioned operator, it invokes the heat operator above on all elements
// of a partition.
- static partition heat_part(partition const& left,
- partition const& middle, partition const& right)
+ static partition heat_part(
+ partition const& left3, partition const& left2, partition const& left,
+ partition const& middle,
+ partition const& right, partition const& right2, partition const& right3
+ )
{
using hpx::dataflow;
using hpx::util::unwrapping;
@@ -354,11 +357,16 @@ stepper::space stepper::do_work(std::size_t np, std::size_t nx, std::size_t nt)
using hpx::util::placeholders::_1;
using hpx::util::placeholders::_2;
using hpx::util::placeholders::_3;
- auto Op = hpx::util::bind(act, localities[locidx(i, np, nl)], _1, _2, _3);
+ using hpx::util::placeholders::_4;
+ using hpx::util::placeholders::_5;
+ using hpx::util::placeholders::_6;
+ using hpx::util::placeholders::_7;
+ auto Op = hpx::util::bind(act, localities[locidx(i, np, nl)], _1, _2, _3, _4, _5, _6, _7);
next[i] = dataflow(
hpx::launch::async, Op,
- current[idx(i, -1, np)], current[i], current[idx(i, +1, np)]
- );
+ current[idx(i, -3, np)], current[idx(i, -2, np)], current[idx(i, -1, np)],
+ current[i],
+ current[idx(i, +1, np)], current[idx(i, +2, np)], current[idx(i, +3, np)]);
}
}
Script to reproduce
This is what I used. The process runs out of memory on a node with 256 GiB. The nodes I use have 8 Numa nodes, having 6 real cores each. I run a single task per Numa node. Each of these use 6 OS threads.
#!/usr/bin/env bash
set -e
# → Update this path to local conventions
install_prefix=$LUE_OBJECTS/_deps/hpx-build
nr_threads_per_locality=6
nr_localities=8
nr_partitions=5625
partition_size=160000
nr_time_steps=500
# Submit job to SLURM scheduler
sbatch --job-name heat_ring << END_OF_SLURM_SCRIPT
#!/usr/bin/env bash
#SBATCH --nodes=1
#SBATCH --ntasks=8
#SBATCH --cpus-per-task=12
#SBATCH --cores-per-socket=6
#SBATCH --partition=allq
set -e
module purge
module load opt/all
module load userspace/all
module load gcc/7.2.0
module load boost/gcc72/1.65.1
module load mpich/gcc72/mlnx/3.2.1
module load libraries/papi/5.7.0
srun --ntasks $nr_localities --kill-on-bad-exit --mpi=pmi2 \
$install_prefix/bin/1d_stencil_7 \
--hpx:ini="hpx.parcel.mpi.enable=1" \
--hpx:ini="hpx.os_threads=$nr_threads_per_locality" --hpx:bind="thread:0-5=core:0-5.pu:0" \
--hpx:print-bind \
--no-header \
--np=$nr_partitions \
--nx=$partition_size \
--nt=$nr_time_steps
END_OF_SLURM_SCRIPT
About this issue
- Original URL
- State: closed
- Created 4 years ago
- Comments: 23 (23 by maintainers)
I used today’s master, git tag 57f2f7671b9
1d_stencil_7. 2 localities with 2 threads each.1d_stencil_7to pass a few more partitions to the action, memory increases as described above. To me it seems all of the above is still an issue with the current sources.This is a screenshot of a graph showing the load per core and the increasing memory usage. At the end I killed the process.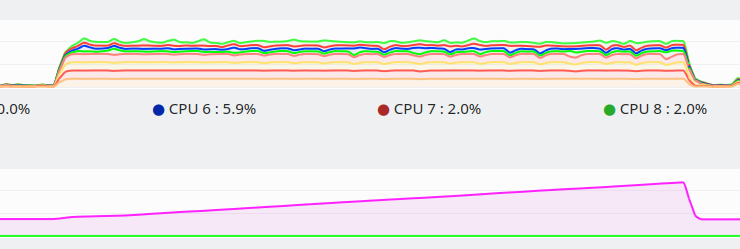
This sounds like we don’t properly release references to the objects that are passed as arguments. I’ll try to have a look to understand what’s wrong.
It is in my own code, in the loop iterating of the time steps: https://github.com/pcraster/lue/blob/f2ec7aa30c3e2b73f3ef6554f00487a6a6546458/source/framework/benchmark/src/benchmark_model.cpp#L179 I took inspiration from
1d_stencil_4_throttle.cpp.WRT garbage collection, I already use
hpx.agas.max_pending_refcnt_requests!=400to get rid of lingering components servers faster than by default (4048). This has helped me to keep the overall memory usage of the processes much lower. The issue I report here is about a continuously increasing amount of memory.To me the core of the problem seems to be that when asynchronously calling an action passing in component clients on localities that are not the same as the current one, memory is leaked. The amount leaked scales with the number of component clients passed along as arguments. The action itself does not need to use the component clients. Just creating a single new partition and returning the component client instance is enough. Replacing the asynchronous call to a synchronous one solves the issue, as does working on a single locality.
On a 1D ring with two neighboring partition clients the issue is visible, but small. It increases fast with the number of neighboring partition clients passed (see diff above). In my code I use a 2D array with 8 neighbors, in which case it takes a few seconds for the process to allocate all memory.
For ease of reproducing the issue on a local machine I can try to reproduce the issue with hpxrun, if that is useful.