crawler: Crawling gets slower as the number of crawled pages raises
I’ve been experiencing very slow crawling after a few hundred pages.
To ensure that the problem did not come from the client-server connection, I used a cache middleware with a greedy cache strategy, and performed a dry run to store all the pages into the cache before doing any performance testing.
Here’s a scatter plot of the time it takes to crawl a single page:
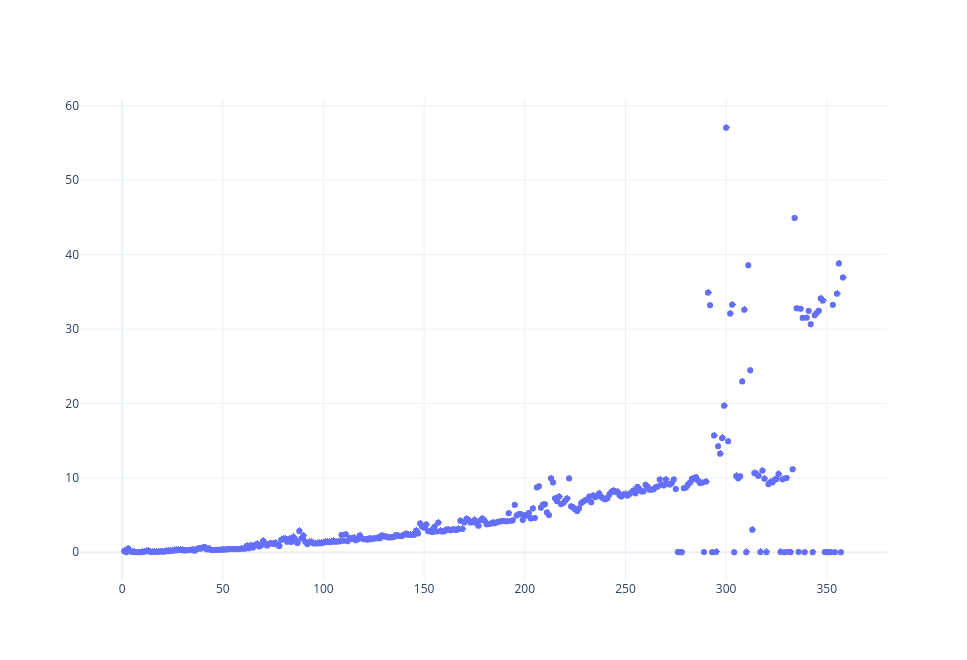
It takes an average of 10s to process a single page after only 300 pages!
To understand what made it this slow, I ran the xdebug profiler, here is the result:

It looks like recursive calls to Crawler::addToDepthTree() are eating 95% of the CPU and make the crawling shockingly slow.
Before I dig further into the code (I’m not yet familiar with it), is there any easy fix that comes to your mind, to speed this process up?
Note: I cannot attach the cachegrind file, as it’s 2.5GB.
About this issue
- Original URL
- State: closed
- Created 5 years ago
- Comments: 23 (18 by maintainers)
Hi Freek,
I think a first roadmap for v5 could be:
New features
Fixes
Code improvements
$idinCrawlUrl: Guzzle’sPoolcan yield string keys as well, we do not need an int, and can use the URL as the key to greatly simplify the codeCollectionCrawlQueueby using an indexed array rather than looping through the URLsCrawlQueue::getFirstPendingUrl() : ?CrawlUrl)CrawlQueue::hasto(CrawlUrl $crawlUrl)to be consistent with the other methodsCrawlRequestFailed|FulfilledClassfrom Guzzle by replacing it with an interface; this will allow better static analysis than a invokable class name, and make the contract more explicit, such as:public function crawlFailed(RequestException $exception, CrawlUrl $url)Cleanup
Crawler::endsWith())IMHO these improvements could push this package to the next level, allowing it to be part of larger systems that need to perform automated crawling on a daily basis, and not just one-shot jobs as it’s currently really aimed for.
Pun intended, I’m sure. 😄
@BenMorel those v5 things do sound good. Feel free to send a PR for this. Make sure to have everything covered with tests. Just target the
masterbranch in your PR. I’ll retarget it to av5if it should be necessary.About
v5take a look at this crawlzoneTotally! I missed this issue, thanks for bringing it to my attention. I was preparing a fix that is very similar to @joaomisturini’s when your message arrived.
I’m also getting rid of
nicmart/treewhich is totally useless here: every time the depth of a URL is needed, the code recursively loops through the tree to find the correct node, instead of just using a lookup array (or storing the depth directly in theCrawlUrl, which is an alternative approach).@freekmurze’s Regarding your comment on the linked issue:
I could PR a non-breaking fix, but it will not be pretty. TBH I love your library, it’s really well designed, but at the same time there are loads of things that could be improved but would require a good number of breaking changes.
Is there any chance you can change your mind and start preparing a v5 release right now (I’m willing to help on many points), or is there no way we can get this before the end of the year and the arrival of PHP 7.4?
On this last point, unless you’re willing to only target PHP 7.4+, there’s no good reason to wait until this version is released. We can right away test it against the alpha (Travis has been supporting
7.4snapshotfor a while!) and make it forward-compatible with PHP 7.4.What do you think?
Is this issue related to #210?