scrapy: Wrong type(response) for binary responses
Description
Binary (file) responses are identified as TextResponse instead of a plain Response in spider.parse.
Steps to Reproduce
From this URL https://www.ecb.europa.eu/press/pr/date/2004/html/pr040702.en.html
We can get this link https://www.ecb.europa.eu/pub/redirect/pub_5874_en.html (text is pdf 1692 kB).
It redirects to https://www.ecb.europa.eu/pub/pdf/other/developmentstatisticsemu200406en.pdf
Expected behavior: [What you expect to happen]
In the spider, isinstance(response, TextResponse) should be False.
Actual behavior: [What actually happens]
In the spider, isinstance(response, TextResponse) is True, even though the Content-Type header is application/pdf.
Versions
Scrapy : 1.7.3
lxml : 4.4.2.0
libxml2 : 2.9.9
cssselect : 1.1.0
parsel : 1.5.2
w3lib : 1.21.0
Twisted : 19.10.0
Python : 3.6.8 (default, Jan 14 2019, 11:02:34) - [GCC 8.0.1 20180414 (experimental) [trunk revision 259383]]
pyOpenSSL : 19.1.0 (OpenSSL 1.1.1d 10 Sep 2019)
cryptography : 2.8
Platform : Linux-4.15.0-72-generic-x86_64-with-Ubuntu-18.04-bionic
Extra info
Probably we should handle known binary types in Content-Type here https://github.com/scrapy/scrapy/blob/master/scrapy/responsetypes.py
At least, application/pdf should be in the list.
It would be nice to add some mechanism to allow developers to extend the mapping on the fly, as we can get new types in a project basis and it would be easier update the desired behavior.
About this issue
- Original URL
- State: open
- Created 5 years ago
- Reactions: 4
- Comments: 28 (23 by maintainers)
In this case I guess you are free to choose the target project. Just make sure you pick one that is actively maintained, i.e. one with recent commits.
I think we can keep that discussion to this issue, as it’s quite relevant to the issue.
And I disagree on that point with @kmike , but that’s my personal point of view. I’m not who you need to impress if you’re a gsoc student 😄 .
To my understanding, mime sniffing has two problem domains: header sniffing of a passed MIME type (and evaluating “no-sniff” X-Content-Type-Options header etc.): these can’t be done by
file/magic. This is the logic to decide if content sniffing is needed at all, or if we go by headers or file-endings and stuff.And then the other is content body sniffing. These are all the byte pattern and -mask things listed in that mimesniff spec page. These would be easily implemented using file magic grammar, from what I can see, and you’d be hard-pressed to reinvent a similarly extensible parser in a gsoc project. “mimesniff” stops after speccing mp4, webm and mp3 media type parsers, but
filehas pattern magic to detect some hundred of movie format variations alone, out of the box. Wrappinglibmagicfor scrapy could give users here a much more customizable framework solution later, than a rigid custom parser that implements the bare minimals given by “mimesniff”.Just a single example. Let’s use GIF. That whatwg spec page lists it like this:
Here is how you would write a libmagic implementation fitting that description:
That’s it, pretty much copied from the existing code. It says: start at byte 0 (don’t ignore any leading bytes), then scan for the string “GIF8”. If that matches (go to the next line), skip (those) 4 bytes and then look for string “7a”, or “9a”, and print that as the gif version number. If either of these match, return the mime type as “image/gif”. If that looks too easy, you can tell
magicto look for “47 49 46 38” as big endian byte pattern instead (now it looks more like the mime-sniff spec thing):And libmagic lets you scan for all kinds of little, big or native endian bytestrings, floating point numbers; and more. Or let’s see how libmagic detects webm by default, which requires 40 lines of parser steps on the mimesniff page:
I won’t explain those 4 lines, but they do pretty much what the whatwg parser steps ask for, if not as rigidly, except for the bigger search buffer of 4096 here versus 38-4 bytes in the “spec”.
@Gallaecio @kmike I have gone through the code of mimesniff and the specs. Looks like it only implements section 7.1 Identifying a resource with an unknown MIME type, while there are other steps in the specs that should be done, which can be found in section 7 Determining the computed MIME type of a resource …
I can work on that, maybe even through GSoC (student-alert) … what do you think?
@ejulio, @Gallaecio
ScrapyAgent._cb_bodydonemethod… chooses response class: https://github.com/scrapy/scrapy/blob/e22a8c8c36e34ffaf12ef9e330624df654582605/scrapy/core/downloader/handlers/http11.py#L395-L400responsetypes.from_argsmethod performs several checks with following logic:Response,Response- another response class will be returned ignoring results of previous checks.https://github.com/scrapy/scrapy/blob/e22a8c8c36e34ffaf12ef9e330624df654582605/scrapy/responsetypes.py#L107-L119
In this case: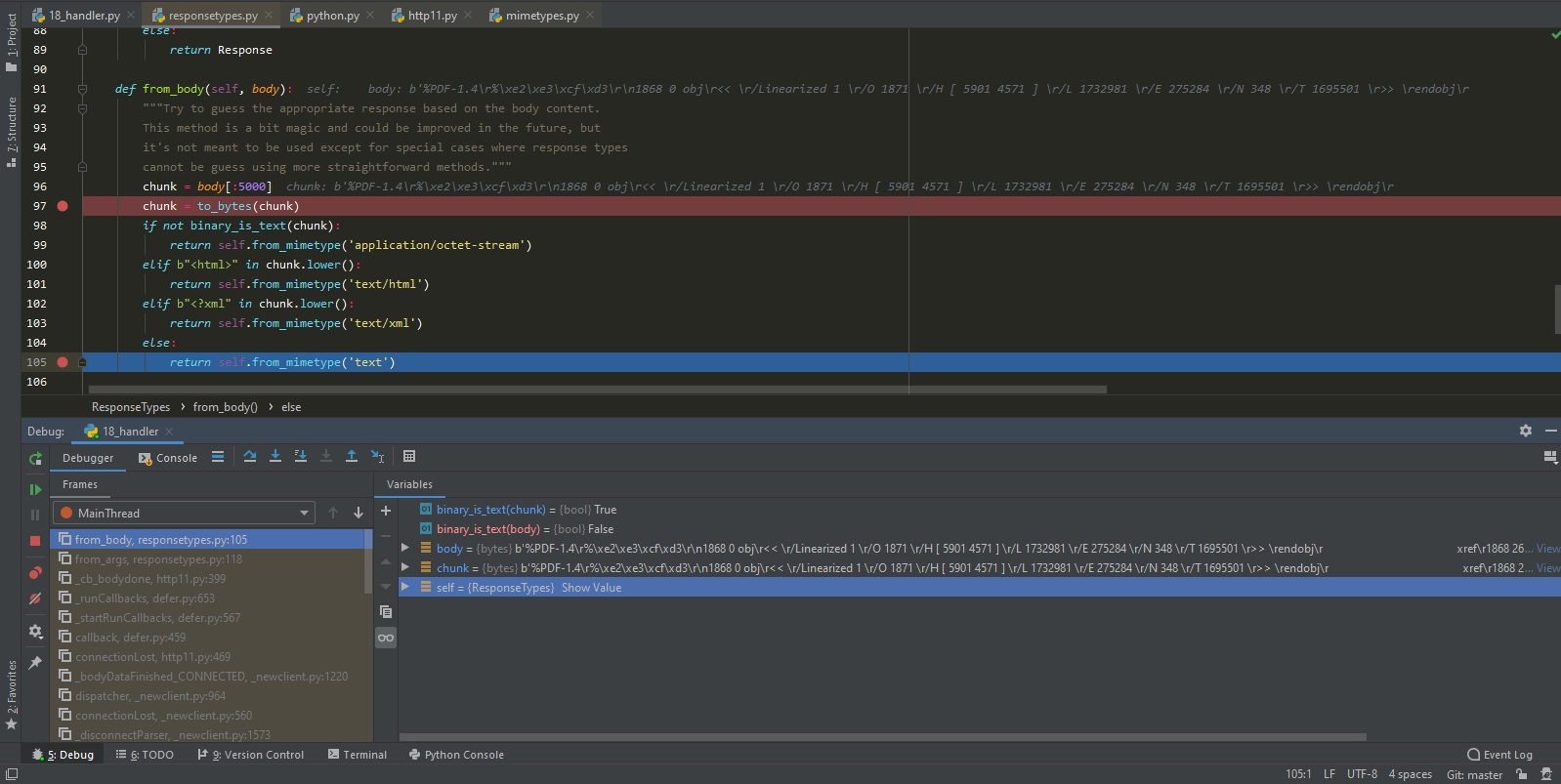 As You can see on the debugger screenshot: this result of
As You can see on the debugger screenshot: this result of
.from_headersand.from_filenamemethods return plainResponseclass. method.from_bodyidentified content of this pdf file as text. As result<class 'scrapy.http.response.text.TextResponse'>will be returned despite results of response headers and url checks:.from_bodymethod based on checking only first 5000 bytes of response body while the same check on the whole response body clearly indicate that response is binary.Thanks a lot @Gallaecio @ejulio for the reviews. I have tried to incorporate your feedback into the proposal and made some changes.
Looks good to me. I was personally hoping to see libmagic-related work earlier out of pure curiosity, but the proposed calendar makes sense, better to follow an order close to that of the specification we are implementing 🙂
@ejulio @Gallaecio I have made a draft proposal for this project. Here is the link https://docs.google.com/document/d/1Zpmm-4mKGr-s74UWGRRooMIjl89PMmefB-dRmJiWXAk/edit?usp=sharing I would be very happy to get some feedback. Comment access has been given.
I think it would make sense to implement the body-based detection in libmagic syntax following the conventions from the standard, and have regular libmagic as a fallback for cases not supported by the standard.
I think the point of aiming to implement the standard is to imitate the behavior of a web browser (which we are assuming will follow the standard as well, if they don’t do it already), potentially even making the same mistakes on purpose in some scenarios, unless there’s a reason why we should not.
I believe that is @kmike’s point, yes. We are open to reusing existing libraries, but the point is to get the best possible implementation, and at the moment it looks like the best way to do that may be a custom implementation from scratch.
@gigatesseract, +1 for mentioning and looking at MIME sniffing vulnerabilities. I can’t answer authoritatively on the GSoC q, but so it doesn’t get overlooked: I believe the
/contributeissue list is for onboarding, it saysAs such, I believe you’re free to contribute to issues with a higher level of difficulty, if they fit otherwise.
Hi @kmike @Gallaecio, I am a 3rd year EE/CS student interested in this year’s GSoC. I’ve programmed in Python for 2 years and have some open-source experience. This is my Github: https://github.com/Mckinsey666.
I’m currently going through the MIME sniffing protocols and the scrapy functions mentioned above. Are there any other updates on this idea or possible contributions I can make before the GSoC proposal?
Thanks a ton!
Best, Brian
There seems to be already such a project: https://pypi.org/project/mimesniff/
IMHO a correct solution would be to implement https://mimesniff.spec.whatwg.org/, though it looks like a significant amount of work (something like a GSoC project?). Ideally, as an external library which Scrapy uses.
responsetypesis a poor man’s mime sniffing implementation.