redisson: RLock can only be obtained by single redisson node after failover
When utilizing RLock in a redis cluster, all redisson nodes are able to obtain a lock (as expected). After performing a redis CLUSTER FAILOVER command on the slave within the shard that holds the lock, the only instance of redisson that is able to obtain that lock going forward is the one which had the lock at the time of the redis failover. This same problem exists with base RLock, as well as FairLock and FencedLock locks.
Redis configurations: 3 shard cluster, 1 slave per shard. Problem exists in simple local redis server (via redis-cli, grokzen/redis-cluster:latest). Also reproducible using AWS elasticache.
Expected behavior After redis cluster failover is complete, all redisson clients are still able to obtain an RLock. Actual behavior Only the redisson instance which held the lock at the time of failover is ever able to obtain the named lock. Only killing the redisson node which originally held the lock allows other nodes to obtain the lock in the future. Steps to reproduce or test case
- Create 2 instances of a redisson application, have them both attempt to obtain and release the same named RLock
- Call “redis-cli CLUSTER FAILOVER” on the SLAVE node of the MASTER which holds the lock
Observe that before step 2, both redisson nodes are able to obtain lock. Observe that after step 2, only the redisson instance which held the lock at time of step 2 will ever obtain the lock again.
Redis version 6.2, 7 Redisson version 3.19.1 Redisson configuration Config config = new Config(); ClusterServersConfig clusterServers = config.useClusterServers() .setRetryInterval(3000) .setTimeout(30000); rest of the settings are default
Simple test case to reproduce (run this with 2 different apps).
LockFailoverFailApp() {
LOG.info("Starting up test...");
RLock distributedLock = redissonConnection.getRedisson().getLock("distributed_lock");
LOG.info("starting main loop in " + this.getClass().getName());
while (true) {
try {
LOG.info("My node ID: {}\tgetting lock, is currently locked: {}", redissonConnection.getRedisson().getId(), distributedLock.isLocked());
if (!distributedLock.tryLock(30, TimeUnit.SECONDS)) {
LOG.info("unable to get lock within 30 sec, will try again");
continue;
}
LOG.info("\"My node ID: {}\tobtained lock, beginning sleep to emulate work", redissonConnection.getRedisson().getId());
Thread.sleep(5000);
LOG.info("My node ID: {}\treleasing lock", redissonConnection.getRedisson().getId());
distributedLock.unlock();
LOG.info("released lock");
} catch (Exception ex) {
LOG.error("Caught exception", ex);
}
}
}
The entire repo for this test application is here: (please see class LockFailoverFailApp) https://github.com/servionsolutions/redisson-testbed/blob/main/app/src/main/java/org/example/redissonfailover/LockFailoverFailApp.java
I am happy to perform any testing and provide any logs desired. This happens the majority of the time, very quick and easy to reproduce.
Sample output:
Notice only one node is able to actually obtain lock after failover completes.

Simple script calling TTL and HGETALL on the lock via redis-cli. Notice that after failover, only 1 redisson node ever gets the lock.
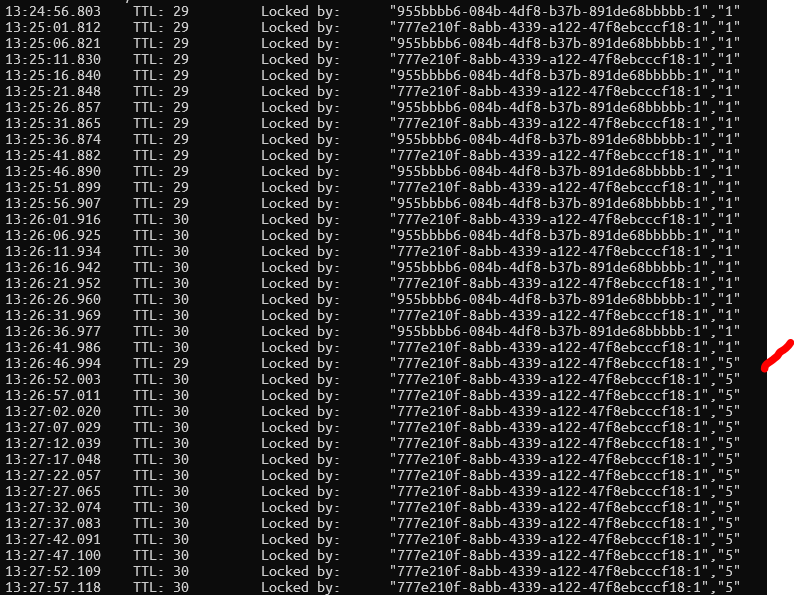
DEBUG level logs (can provide trace if desired) app01.log app02.log
In these test logs, I had to perform the “CLUSTER FAILOVER” command twice to trigger the error, but the vast majority of the time it only takes one FAILOVER command to induce the problem. This is a problem for us because we have a use case where all redisson nodes must be able to obtain a given RLock at some point in time.
About this issue
- Original URL
- State: closed
- Created a year ago
- Comments: 49 (22 by maintainers)
Commits related to this issue
- Fixed - a new attempt should be made on WAIT error during failover. #4822 — committed to redisson/redisson by deleted user a year ago
- Fixed - RLock can only be obtained by single redisson node if "None of slaves were synced" error occurred #4822 — committed to redisson/redisson by deleted user a year ago
- Fixed - Node hasn't been discovered yet error isn't resolved by a new attempt for RBatch and RLock objects #4822 — committed to redisson/redisson by deleted user a year ago
- Fixed - Node hasn't been discovered yet error isn't resolved by a new attempt for RBatch and RLock objects #4822 — committed to redisson/redisson by deleted user a year ago
- Fixed - Node hasn't been discovered yet error isn't resolved by a new attempt for RBatch and RLock objects #4822 — committed to redisson/redisson by deleted user a year ago
- Fixed - RLock can only be obtained by single redisson node if "None of slaves were synced" error occurred #4822 — committed to redisson/redisson by deleted user a year ago
- Fixed - RedisClusterDownException, RedisLoadingException, RedisBusyException, RedisTryAgainException, RedisWaitException are thrown by RBatch and RLock objects even if these errors disappeared after n... — committed to redisson/redisson by deleted user a year ago
- Fixed - Node hasn't been discovered yet error isn't resolved by a new attempt for RBatch and RLock objects #4822 — committed to redisson/redisson by deleted user a year ago
- Fixed - continuously attempts of INFO REPLICATION command execution until attempts limit reached by RLock object after failover. #4822 — committed to redisson/redisson by deleted user a year ago
- Fixed - "READONLY You can't write against a read only replica.." is thrown after failover in sentinel mode. #4822 — committed to redisson/redisson by deleted user a year ago
- Fixed - no retry attempts are made for "None of slaves were synced" error. #4822 — committed to redisson/redisson by deleted user a year ago
@servionsolutions
By the end of this month. Thank you for testing!
@servionsolutions
Thanks for update.
Please try attached version.
redisson-3.20.1-SNAPSHOT.jar.zip
Resolved.
@servionsolutions
Many thanks for testing!
@servionsolutions
It happened because INFO_REPLICATION command was bounded to Redis node explicitly.
Can you try version attached?
redisson-3.20.1-SNAPSHOT.jar.zip
@servionsolutions
Can you try version attached?
redisson-3.20.1-SNAPSHOT.jar.zip
@servionsolutions
Thanks much for the testing!
Yeah, I’m working on it.
@servionsolutions
Thanks for report. That’s wired. It seems like even if CLUTERDOWN is thrown the write operation is made, but it shouldn’t be.
Can you try attached version?
redisson-3.19.4-SNAPSHOT.jar.zip
could this be related to observing lock states internally using pubsub?