realm-core: Stable 3% (!!!) crashes realm::Allocator::translate_less_critical(realm::Allocator::RefTranslation*, unsigned long) const + 68
Goals
Realm crash free 99.N%
Expected Results
Realm crash free 99.N%
Actual Results
Realm crash free 97%
Steps for others to Reproduce
It is hard to reproduce it internally, because it’s random crashes.
Code Sample
- All Realm transactions(writes) from custom serial GCD queue within autoreleasepool.
- New Realm instance each time.
let realmWriteQueue = DispatchQueue(label: "realmWriteQueue")
realmWriteQueue.async {
autoreleasepool {
do {
let realm = try Realm(configuration: ...)
try realm.write { //all writes ALWAYS here }
} catch {}
}
}
Stack trace:

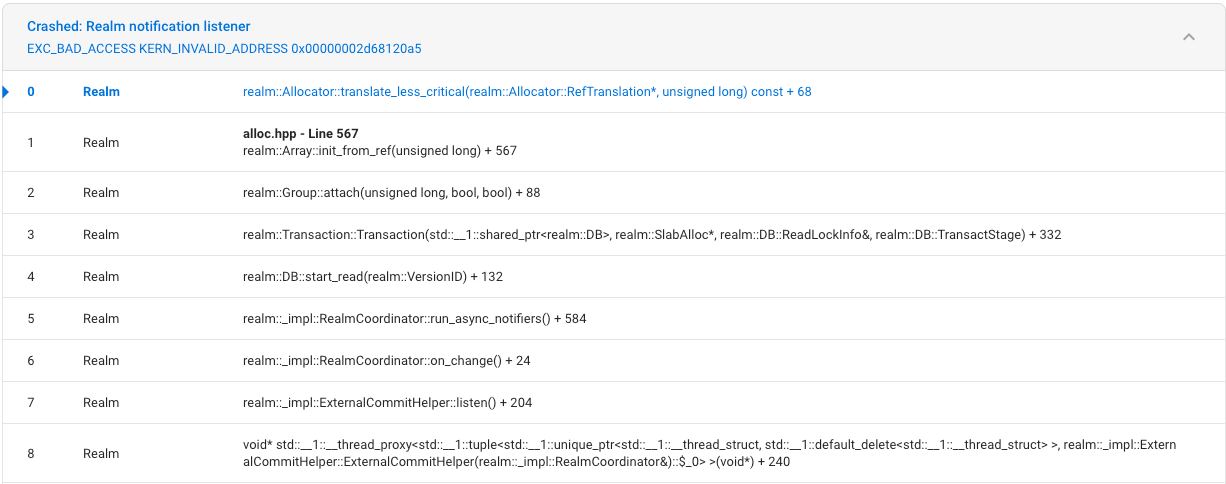
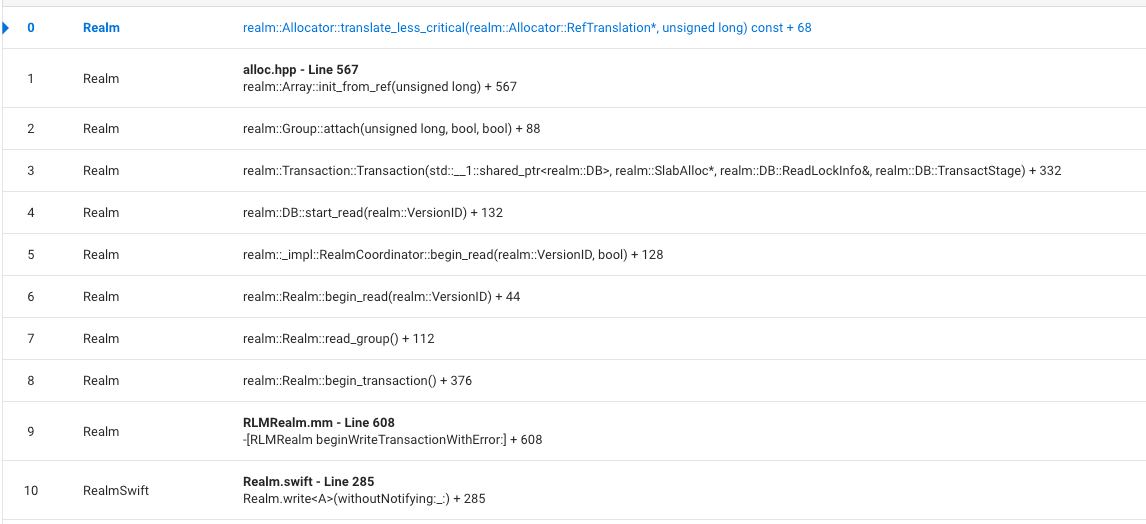
We started seeing these crashes under heavy loads with very active database writes. Reproduced by 3 percent of users.
Realm framework version: 10.5.0, 10.7.2 Xcode version: 12.4
iOS/OSX version: iOS 14.4
Dependency manager + version: CocoaPods 1.10.1
About this issue
- Original URL
- State: closed
- Created 3 years ago
- Reactions: 1
- Comments: 56 (20 by maintainers)
@igorvoytovich FYI we have a tentative fix in development. You can follow it here: https://github.com/realm/realm-core/pull/4534
@tgoyne @finnschiermer @jsflax
I can confirm that these problems are not present on RealmSwift 4.3.2.
We checked on the same project, everything that changed is replaced freeze() with detached() (https://github.com/realm/realm-cocoa/issues/5433#issuecomment-415066361) , because freeze was added after 4.3.2
On this SDK version, Realm works perfectly, without going beyond the size of 1 MB on our data volumes.
I beg you to tell us what to do in this situation, should we wait for any changes? Or should we consider replacing Realm or downgrading to a lower version (4.3.2)?
I hope for your understanding, because due to these problems we are suffering large financial losses and we need to resolve this as soon as possible.
Reproducable after some time using the app / Realm, here’s another example:
And so it will continue indefinitely, until it takes away all the memory. Realm works as it should for a while, then after something it breaks down and a strong memory growth begins, regardless of the activity of transactions.
@finnschiermer ,
thanks for getting back to me.
On our side, we are seeing these crashes on real iPhones. To be more specific: iPhone SE 2, iPhone 11 Pro Max. All on iOS 14.5-14.6. We also see these problems among our users in the crash analytics of the app. For development and deployment, we use only Macs with an M1 chip, integration via CocoaPods.
We’ve tried a bunch of things already, and we can’t even imagine where the mistake might be on our side, from our side the code is as simple and predictable as possible.
If you have any questions, please do not hesitate to ask anytime.
By the way, we already use 10.8.0 version of SDK, and the problem still persist.
You’ve only seen this on iOS devices and not in the simulator, right? The xover mapping logic is full of atomics that look right, but a bug in them which is hidden on x86 by the stricter memory model would make a lot of sense.
Explicitly calling
refresh()will block the main thread until the notification worker is done processing a write, while otherwise we delay notifying the main thread until that’s done so that it can continue to process user interaction. It otherwise behaves identically to automatic refreshes.Resolving a ThreadSafeReference which was created at a later version than the local Realm is at just calls
refresh()internally. It’s theoretically faster than looking up the object by PK again but it’s a negligible difference. TSR<Object> is mostly only interesting for object types without primary keys.It sounds like It sounds like https://github.com/realm/realm-core/pull/4534 is unlikely to help you (and if you were actually hitting the problem it fixes it wouldn’t help much; gracefully reporting an error rather than crashing still usually doesn’t leave the app in a working state). That’s unsurprising as it was basically just a blind stab at finding a problem and fixing the first thing I found. I will keep digging for more potential things. Any more information you can provide about what’s scenarios cause problems would help, but I don’t have any specific suggestions.
The big advantage of this function over a manual loop is that it mostly avoids allocating any temporary objects. In theory it should work for arbitrarily large arrays.
@jpstern thank you very much for the information.
@finnschiermer @tgoyne Since the current version is not production-ready, could you tell if we should wait for this problem to be fixed, or would it be more correct to roll back to the old version (4.3.2, for example, as mentioned above)? Thanks.
For the realm team - we were ultimately able to reliably reproduce the crash by running sustained very high volume concurrent writes. Not necessarily a realistic real world scenario, but it was the only way to get the crash to happen.
It’s possible low RAM is a factor for the the RLMRealm being autoreleased during a write transaction. A noticeable percentage of the crashes showed low RAM on Crashlytics, usually under 100MB remaining. Our realm files usually get up to about 80mb in production. (prob not ideal, but it is what it is)
We force deleted the realm file to prevent rollback issues. The files aren’t compatible so your users will get a crash if you try to just rollback. Luckily our data syncs from a server, so deleting the realm didn’t have any side effects
FWIW - we rolled back to 4.3.2, which was the version we used before upgrading to the most recent and the crashes have disappeared.
We were previously seeing 100-4000 instances of this crash daily depending on app usage.