rclone: env_auth=true not working with Minio provider
What is the problem you are having with rclone?
Trying to authenticate with an s3 type, provider minio, while using env_auth=true
Hint: using access-key/secret key configurations inside ~/.config/rclone/rclone.conf does work
i configured this in ~/.config/rclone/rclone.conf
[minio1]
type = s3
provider = Minio
env_auth = true
endpoint = https://minio1.<redacted-host>:<redacted-non-default-port>
location_constraint = de
acl = authenticated-read
I also have the following env variables set (as by https://rclone.org/s3/)
RCLONE_S3_PROVIDER=Minio
RCLONE_S3_ENDPOINT=https://minio1.<redacted-host>:<redacted-non-default-port>
RCLONE_S3_LOCATION_CONSTRAINT=de
RCLONE_S3_ACL=authenticated-read
RCLONE_S3_ACCESS_KEY_ID=<redacted-access-key>
RCLONE_S3_SECRET_ACCESS_KEY=<redacted-acces-secret>
It seems like the authentication either fails or even the wrong endpoint is used (thus the rather long 60s timeout?).
workarround
if i just add/change ~/.config/rclone/rclone.conf
env_auth = false
access_key_id = <redacted-access-key>
secret_access_key = <redacted-acces-secret>
to my rclone alias configuration - it will work without issues. So my general access and transport layer / secrets are just fine.
It just started with the fact that i want to use env based authentication to split the secrets out of the rclone.conf
What is your rclone version (output from rclone version)
rclone --version
rclone v1.57.0
- os/version: debian 11.2 (64 bit)
- os/kernel: 5.10.0-9-amd64 (x86_64)
- os/type: linux
- os/arch: amd64
- go/version: go1.17.2
- go/linking: static
- go/tags: none
Which OS you are using and how many bits (e.g. Windows 7, 64 bit)
debian 11.2 (64 bit)
Which cloud storage system are you using? (e.g. Google Drive)
The source s3 is an most recent Minio
The command you were trying to run (e.g. rclone copy /tmp remote:tmp)
rclone sync --verbose minio1:testbucket /tmpt/test
A log from the command with the -vv flag (e.g. output from rclone -vv copy /tmp remote:tmp)
2022/02/13 10:13:52 INFO :
Transferred: 0 B / 0 B, -, 0 B/s, ETA -
Elapsed time: 3m0.1s
2022/02/13 10:14:52 INFO :
Transferred: 0 B / 0 B, -, 0 B/s, ETA -
Elapsed time: 4m0.1s
How to use GitHub
- Please use the 👍 reaction to show that you are affected by the same issue.
- Please don’t comment if you have no relevant information to add. It’s just extra noise for everyone subscribed to this issue.
- Subscribe to receive notifications on status change and new comments.
About this issue
- Original URL
- State: closed
- Created 2 years ago
- Comments: 18 (5 by maintainers)
And memory management… boy, it’s first class! I’ve never expected the program to be willing to release unused memory immediately when it moved to smaller files!
Compare and contrast with: https://www.google.com/search?q=restic+heavy+memory+usage (and I’m the one with the largest triple-digit memory usage on record in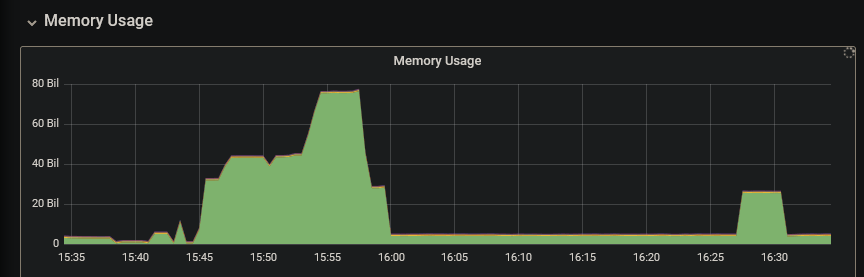
resticin this very smoke test - there peak memory usage was 220 GiB and constantly growing in a hatchet pattern vs. peak 75 GiB here (used only when needed, i.e. during attempted uploads of those failing 18 huge 5GB+ files and then released dynamically as soon as it’s was no longer needed, when we moved to small files, I mean, this is how memory mgmt should work everywhere, you deserve a medal:):Yes, but the S3 limitation you metion it is very useful if you want to skip these huge files qualifying for the multipart (if it is not handled correctly by MinIO and breaks your process or would slow it down from hours do weeks). To achieve this it’s enough to set
--s3-chunk-sizeto more than 5G (getting the expected error - perfectly handled inrcloneby (unlike inrestic, which crashed every time on first such file):Here you even also get a detailed list, complete with the source path (even without verbose option, just using progress is sufficient) of all those “too big to send” files so you can compress them and re-try the backup:
Note to self: switching off multipart uploads (e.g. if S3 / minio does not handle them correctly like in our case apparently) can be also achieved more elegantly and with significantly lower memory footprint by setting
--max-size 5G(which is the maximum allowed for single part in S3 multipart uploads - note it’s G not T:).