terraform-provider-rancher2: [BUG] Occasionally RKE2 cluster gets destroyed after cluster configuration is changed using terraform provider
Important: Please see https://github.com/rancher/terraform-provider-rancher2/issues/993#issuecomment-1611922983 on the status of this issue following completed investigations.
Rancher Server Setup
- Rancher version: 2.6.8
- Installation option (Docker install/Helm Chart):
- installed as helm chart
- running on k3s 1.24.4
- Proxy/Cert Details: N/A
Information about the Cluster
- Kubernetes version: 1.23.9
- Cluster Type Downstream:
- Custom
RKE2 v1.23.9+rke2r1running on AWS - Provisioned with Terraform provider
rancher/rancher2version1.24.1
- Custom
cluster configuration:
{
"kubernetesVersion": "v1.23.9+rke2r1",
"rkeConfig": {
"upgradeStrategy": {
"controlPlaneConcurrency": "1",
"controlPlaneDrainOptions": {
"enabled": false,
"force": false,
"ignoreDaemonSets": true,
"IgnoreErrors": false,
"deleteEmptyDirData": true,
"disableEviction": false,
"gracePeriod": 0,
"timeout": 10800,
"skipWaitForDeleteTimeoutSeconds": 600,
"preDrainHooks": null,
"postDrainHooks": null
},
"workerConcurrency": "10%",
"workerDrainOptions": {
"enabled": false,
"force": false,
"ignoreDaemonSets": true,
"IgnoreErrors": false,
"deleteEmptyDirData": true,
"disableEviction": false,
"gracePeriod": 0,
"timeout": 10800,
"skipWaitForDeleteTimeoutSeconds": 600,
"preDrainHooks": null,
"postDrainHooks": null
}
},
"chartValues": null,
"machineGlobalConfig": {
"cloud-provider-name": "aws",
"cluster-cidr": "100.64.0.0/13",
"cluster-dns": "100.64.0.10",
"cluster-domain": "cluster.local",
"cni": "none",
"disable": [
"rke2-ingress-nginx",
"rke2-metrics-server",
"rke2-canal"
],
"disable-cloud-controller": false,
"kube-apiserver-arg": [
"allow-privileged=true",
"anonymous-auth=false",
"feature-gates=CustomCPUCFSQuotaPeriod=true",
"api-audiences=https://<REDACTED>-oidc.s3.eu-central-1.amazonaws.com,https://kubernetes.default.svc.cluster.local,rke2",
"audit-log-maxage=90",
"audit-log-maxbackup=10",
"audit-log-maxsize=500",
"audit-log-path=/var/log/k8s-audit/audit.log",
"audit-policy-file=/etc/kubernetes-/audit-policy.yaml",
"authorization-mode=Node,RBAC",
"bind-address=0.0.0.0",
"enable-admission-plugins=PodSecurityPolicy,NodeRestriction",
"event-ttl=1h",
"kubelet-preferred-address-types=InternalIP,Hostname,ExternalIP",
"profiling=false",
"request-timeout=60s",
"runtime-config=api/all=true",
"service-account-key-file=/etc/kubernetes-wise/service-account.pub",
"service-account-lookup=true",
"service-account-issuer=https://<REDACTED>-oidc.s3.eu-central-1.amazonaws.com",
"service-account-signing-key-file=/etc/kubernetes-wise/service-account.key",
"service-node-port-range=30000-32767",
"shutdown-delay-duration=60s",
"tls-min-version=VersionTLS12",
"tls-cipher-suites=TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256,TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256,TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305,TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384,TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305,TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384",
"tls-min-version=VersionTLS12",
"v=2"
],
"kube-apiserver-extra-mount": [
"/etc/kubernetes-wise:/etc/kubernetes-wise:ro",
"/var/log/k8s-audit:/var/log/k8s-audit:rw"
],
"kube-controller-manager-arg": [
"allocate-node-cidrs=true",
"attach-detach-reconcile-sync-period=1m0s",
"bind-address=0.0.0.0",
"configure-cloud-routes=false",
"feature-gates=CustomCPUCFSQuotaPeriod=true",
"leader-elect=true",
"node-monitor-grace-period=2m",
"pod-eviction-timeout=220s",
"profiling=false",
"service-account-private-key-file=/etc/kubernetes-wise/service-account.key",
"use-service-account-credentials=true",
"terminated-pod-gc-threshold=12500",
"tls-min-version=VersionTLS12",
"tls-cipher-suites=TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256,TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256,TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305,TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384,TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305,TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384",
"tls-min-version=VersionTLS12"
],
"kube-controller-manager-extra-mount": [
"/etc/kubernetes-wise:/etc/kubernetes-wise:ro"
],
"kube-proxy-arg": [
"conntrack-max-per-core=131072",
"conntrack-tcp-timeout-close-wait=0s",
"metrics-bind-address=0.0.0.0",
"proxy-mode=iptables"
],
"kube-scheduler-arg": [
"bind-address=0.0.0.0",
"port=0",
"secure-port=10259",
"profiling=false",
"leader-elect=true",
"tls-min-version=VersionTLS12",
"v=2",
"tls-cipher-suites=TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256,TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256,TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305,TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384,TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305,TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384",
"tls-min-version=VersionTLS12"
],
"kubelet-arg": [
"network-plugin=cni",
"cni-bin-dir=/opt/cni/bin/",
"cni-conf-dir=/etc/cni/net.d/",
"feature-gates=CustomCPUCFSQuotaPeriod=true",
"config=/etc/kubernetes-wise/kubelet.yaml",
"exit-on-lock-contention=true",
"lock-file=/var/run/lock/kubelet.lock",
"pod-infra-container-image=docker-k8s-gcr-io.<REDACTED>/pause:3.1",
"register-node=true",
"tls-cipher-suites=TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256,TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256,TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305,TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384,TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305,TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384",
"tls-min-version=VersionTLS12",
"v=4"
],
"profile": "cis-1.6",
"protect-kernel-defaults": true,
"service-cidr": "100.64.0.0/13"
},
"additionalManifest": "<REDACTED>",
"registries": {
"mirrors": {
"docker.io": {
"endpoint": [
"<REDACTED>"
]
},
"gcr.io": {
"endpoint": [
"<REDACTED>"
]
},
"k8s.gcr.io": {
"endpoint": [
"<REDACTED>"
]
},
"quay.io": {
"endpoint": [
"<REDACTED>"
]
}
},
"configs": {
"<REDACTED>": {}
}
},
"etcd": {
"snapshotScheduleCron": "0 */6 * * *",
"snapshotRetention": 12,
"s3": {
"endpoint": "s3.eu-central-1.amazonaws.com",
"bucket": "etcd-backups-<REDACTED>",
"region": "eu-central-1",
"folder": "etcd"
}
}
},
"localClusterAuthEndpoint": {},
"defaultClusterRoleForProjectMembers": "user",
"enableNetworkPolicy": false
}
Additional info:
- I am using custom CNI: aws-vpc-cni installed via
additional_manifest
Describe the bug
Occasionally simple cluster configuration change for example change lables in manifests passed via additional_manifest applied with terraform provider causing managed RKE2 cluster to destroy.
terraform plan looks similar to this:
Terraform Plan output
Terraform will perform the following actions:
# module.cluster.rancher2_cluster_v2.this will be updated in-place
~ resource "rancher2_cluster_v2" "this" {
id = "fleet-default/o11y-euc1-se-main01"
name = "o11y-euc1-se-main01"
# (10 unchanged attributes hidden)
~ rke_config {
~ additional_manifest = <<-EOT
---
apiVersion: v1
kind: Namespace
metadata:
labels:
- test: test
+ test1: test1
name: my-namespace
EOT
}
}
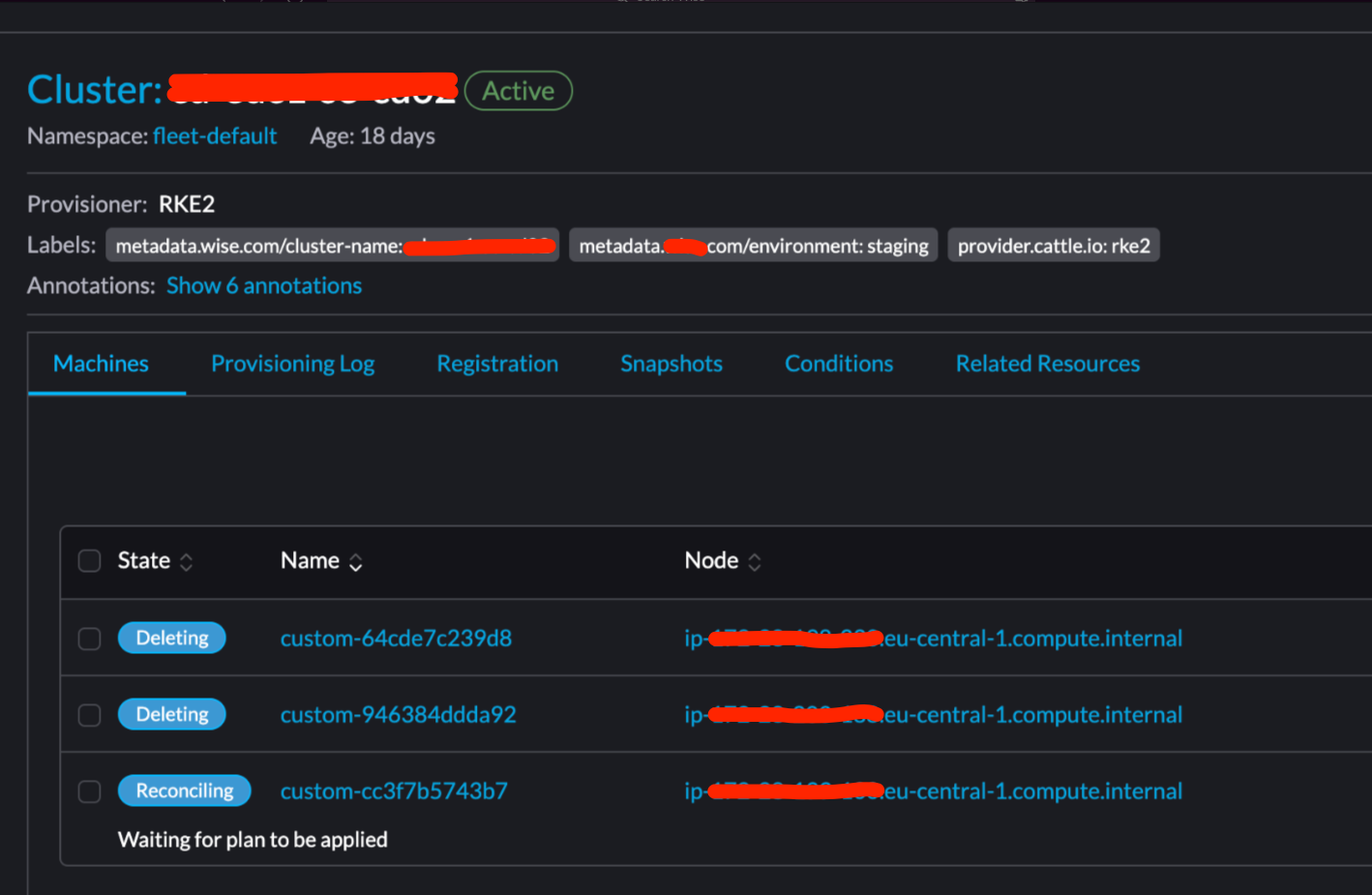
Sometimes once change like this is applied rancher immediately trying to delete that managed cluster for some reason. On UI it looks like this:
Rancher UI screenshot:
Rancher logs:
rancher logs:
2022/09/08 08:58:30 [DEBUG] [planner] rkecluster fleet-default/<REDACTED>: unlocking 810235e7-ecc0-4ba7-81c8-55d778594926
2022/09/08 08:58:30 [INFO] [planner] rkecluster fleet-default/<REDACTED>: waiting: configuring bootstrap node(s) custom-7808e68fb38f: waiting for plan to be applied
2022/09/08 08:58:30 [DEBUG] [CAPI] Cannot retrieve CRD with metadata only client, falling back to slower listing
2022/09/08 08:58:30 [DEBUG] DesiredSet - Patch rbac.authorization.k8s.io/v1, Kind=Role fleet-default/crt-<REDACTED>-nodes-manage for auth-prov-v2-roletemplate-<REDACTED> nodes-manage -- [PATCH:{"metadata":{"annotations":{"objectset.rio.cattle.io/applied":"H4sIAAAAAAAA/4xRTY/bIBD9K9UcK5Oa4NjYUk899FCph9WqlyqHAYYNXQwW4LTSKv+9IrtVrK36cYMH8+Z9PMFMBQ0WhOkJMIRYsLgYcr1G9Y10yVR2ycWdxlI87Vx85wxMgGs5sSXFMzvvWYqeCs2Lx0JMG0ar5mypx5ZD80ei+D1QYg/nR5hgxoAPNFMomw9n0bz55IJ5fxc93b8s+CdhwJlgghANZfbM+18zeUFdB+HSgE50DeLezZQLzgtMYfW+AY+K/F/jOWE+wQS94vuDGMS+l0O3Jz0oGgY96rFFtKq1qA2146Gv214U61Rep8deudjqtJ6oMEMWV1+qw+rkjiwlCpoyTF+fABf3hVJ2McAEtS5Xzy48bFOuHT26UGv94NdcKMFN029trtf+ueJCKdsx3fKedQcpmLIG2SDwICxHYcjC5XhpIK3+JuZjiutSb6CfN+1+sEeZdy7CsYFEOa5J0+fq8vppzSXOjFNr0XDkUiA0v1CSqDk/jGPf9zdUKKV6MnLUvb2hfTsMrUBOYlQ3tBOi10PX7Tu7YRhkK6mXVgm5YRiF4aPppDooudV61TmjPrlAuT6cKakr+BaOl+PlZwAAAP//1WFOc2MDAAA"}},"rules":[{"apiGroups":["cluster.x-k8s.io"],"resourceNames":["custom-1e0fad1a183a","custom-e8ac11599666","custom-3bbb6ed89c6f","custom-607703a1e39b","custom-4336c74424f6","custom-7808e68fb38f","custom-93d19d48b5b8"],"resources":["machines"],"verbs":["*"]}]}, ORIGINAL:{"apiVersion":"rbac.authorization.k8s.io/v1","kind":"Role","metadata":{"annotations":{"objectset.rio.cattle.io/applied":"H4sIAAAAAAAA/4yRT4/bLBDGv8qrOb4KqQk2xpZ66qGHSj2sql6qHAYYNnRtsACnlaJ894rsVo626p8bPDDP/GaeC8xU0GJBGC+AIcSCxceQ6zXqr2RKprJPPu4NljLR3sc33sIIuJYTW1I8s/OBpThRoXmZsBAzltFqOFvqseGw+61R/BYoscfzE4wwY8BHmimUuw9nsfvvgw/27UOc6NNLg78aBpwJRgjRUmbPvv9Ukxc0tRCuO5hQ0/THLZwwn2AEqfmhE704SNW3BzK9pr43gxkaRKcbh8ZSM3Symr6AmVReL4m9gr3HcRNRYZYcrlOpg1TgB3KUKBjKMH65AC7+M6XsY4ARaiq+nn14vF9mjeLJh5reu2nNhRJsTL+Ett5i5poLrV3LTMMlazslmHYWWS+wE46jsOTgerzuIK3TBvM+xXWpNzDPnfbf2ZPKex/huINEOa7J0Mc65e3TmkucWa8aRVI5LZSD3U91EJYPtlW602pTOTUOLUeuBG4qKTScd8MgpdxUobWWZNVg5J2vbPq+EchJDHpTWyGk6dv20Dp5z3rjnNGcfKBcH86U9E38H47X4/VHAAAA///VWUNFSgMAAA","objectset.rio.cattle.io/id":"auth-prov-v2-roletemplate-<REDACTED>","objectset.rio.cattle.io/owner-gvk":"management.cattle.io/v3, Kind=RoleTemplate","objectset.rio.cattle.io/owner-name":"nodes-manage","objectset.rio.cattle.io/owner-namespace":""},"labels":{"objectset.rio.cattle.io/hash":"6b125373268742ec7be77c9c90aafb0facde0956"},"name":"crt-<REDACTED>-nodes-manage","namespace":"fleet-default","ownerReferences":[{"apiVersion":"provisioning.cattle.io/v1","kind":"Cluster","name":"<REDACTED>","uid":"1b13bbf4-c016-4583-bfda-73a53f1a3def"}]},"rules":[{"apiGroups":["cluster.x-k8s.io"],"resourceNames":["custom-7808e68fb38f","custom-93d19d48b5b8","custom-1e0fad1a183a","custom-e8ac11599666","custom-3bbb6ed89c6f","custom-607703a1e39b","custom-4336c74424f6"],"resources":["machines"],"verbs":["*"]}]}, MODIFIED:{"kind":"Role","apiVersion":"rbac.authorization.k8s.io/v1","metadata":{"name":"crt-<REDACTED>-nodes-manage","namespace":"fleet-default","creationTimestamp":null,"labels":{"objectset.rio.cattle.io/hash":"6b125373268742ec7be77c9c90aafb0facde0956"},"annotations":{"objectset.rio.cattle.io/applied":"H4sIAAAAAAAA/4xRTY/bIBD9K9UcK5Oa4NjYUk899FCph9WqlyqHAYYNXQwW4LTSKv+9IrtVrK36cYMH8+Z9PMFMBQ0WhOkJMIRYsLgYcr1G9Y10yVR2ycWdxlI87Vx85wxMgGs5sSXFMzvvWYqeCs2Lx0JMG0ar5mypx5ZD80ei+D1QYg/nR5hgxoAPNFMomw9n0bz55IJ5fxc93b8s+CdhwJlgghANZfbM+18zeUFdB+HSgE50DeLezZQLzgtMYfW+AY+K/F/jOWE+wQS94vuDGMS+l0O3Jz0oGgY96rFFtKq1qA2146Gv214U61Rep8deudjqtJ6oMEMWV1+qw+rkjiwlCpoyTF+fABf3hVJ2McAEtS5Xzy48bFOuHT26UGv94NdcKMFN029trtf+ueJCKdsx3fKedQcpmLIG2SDwICxHYcjC5XhpIK3+JuZjiutSb6CfN+1+sEeZdy7CsYFEOa5J0+fq8vppzSXOjFNr0XDkUiA0v1CSqDk/jGPf9zdUKKV6MnLUvb2hfTsMrUBOYlQ3tBOi10PX7Tu7YRhkK6mXVgm5YRiF4aPppDooudV61TmjPrlAuT6cKakr+BaOl+PlZwAAAP//1WFOc2MDAAA","objectset.rio.cattle.io/id":"auth-prov-v2-roletemplate-<REDACTED>","objectset.rio.cattle.io/owner-gvk":"management.cattle.io/v3, Kind=RoleTemplate","objectset.rio.cattle.io/owner-name":"nodes-manage","objectset.rio.cattle.io/owner-namespace":""},"ownerReferences":[{"apiVersion":"provisioning.cattle.io/v1","kind":"Cluster","name":"<REDACTED>","uid":"1b13bbf4-c016-4583-bfda-73a53f1a3def"}]},"rules":[{"verbs":["*"],"apiGroups":["cluster.x-k8s.io"],"resources":["machines"],"resourceNames":["custom-1e0fad1a183a","custom-e8ac11599666","custom-3bbb6ed89c6f","custom-607703a1e39b","custom-4336c74424f6","custom-7808e68fb38f","custom-93d19d48b5b8"]}]}, CURRENT:{"kind":"Role","apiVersion":"rbac.authorization.k8s.io/v1","metadata":{"name":"crt-<REDACTED>-nodes-manage","namespace":"fleet-default","uid":"2d3678e7-1904-442f-bfa6-ef4ad97baa40","resourceVersion":"32202831","creationTimestamp":"2022-09-08T07:56:23Z","labels":{"objectset.rio.cattle.io/hash":"6b125373268742ec7be77c9c90aafb0facde0956"},"annotations":{"objectset.rio.cattle.io/applied":"H4sIAAAAAAAA/4xRS48UIRD+K6aOphmboYd+JJ48eDDxsNl4MXMooNjBpaED9Giymf9umF3TkzU+bvBBffU9nmCmggYLwvQEGEIsWFwMuV6j+ka6ZCq75OJOYymedi6+cwYmwLWc2JLimZ33LEVPhebFYyGmDaNVc7bUY8uh+SNR/B4osYfzI0wwY8AHmimUmw9n0bz55IJ5fxc93b8s+CdhwJlgghANZfbM+18zeUFdB+HSgE50DeLezZQLzgtMYfW+AY+K/F/jOWE+wQRS8f1B9GIvh77bk+4V9b0e9dgiWtVa1Iba8SDrthfFOpXX6bFXLm51Wk9UmCGLqy/VYXVyR5YSBU0Zpq9PgIv7Qim7GGCCWperZxceblOuHT26UGv94NdcKMGm6bc212v/XHGhlO2Ybrlk3WEQTFmDrBd4EJajMGThcrw0kFa/ifmY4rrUG+jnTbsf7HHIOxfh2ECiHNek6XN1ef205hJn1g/tQHKwSgwWml/oKAwfTTeogxo2lFNr0XDkg8ANpQE154dxlFJuqFBKSTLDqOUNr2z7vhXISYxqQzshpO67bt9Zeav1qnNGfXKBcn04U1JX8C0cL8fLzwAAAP//skxNxGMDAAA","objectset.rio.cattle.io/id":"auth-prov-v2-roletemplate-<REDACTED>","objectset.rio.cattle.io/owner-gvk":"management.cattle.io/v3, Kind=RoleTemplate","objectset.rio.cattle.io/owner-name":"nodes-manage","objectset.rio.cattle.io/owner-namespace":""},"ownerReferences":[{"apiVersion":"provisioning.cattle.io/v1","kind":"Cluster","name":"<REDACTED>","uid":"1b13bbf4-c016-4583-bfda-73a53f1a3def"}],"managedFields":[{"manager":"rancher","operation":"Update","apiVersion":"rbac.authorization.k8s.io/v1","time":"2022-09-08T07:58:00Z","fieldsType":"FieldsV1","fieldsV1":{"f:metadata":{"f:annotations":{".":{},"f:objectset.rio.cattle.io/applied":{},"f:objectset.rio.cattle.io/id":{},"f:objectset.rio.cattle.io/owner-gvk":{},"f:objectset.rio.cattle.io/owner-name":{},"f:objectset.rio.cattle.io/owner-namespace":{}},"f:labels":{".":{},"f:objectset.rio.cattle.io/hash":{}},"f:ownerReferences":{".":{},"k:{\"uid\":\"1b13bbf4-c016-4583-bfda-73a53f1a3def\"}":{}}},"f:rules":{}}}]},"rules":[{"verbs":["*"],"apiGroups":["cluster.x-k8s.io"],"resources":["machines"],"resourceNames":["custom-7808e68fb38f","custom-93d19d48b5b8","custom-1e0fad1a183a","custom-e8ac11599666","custom-3bbb6ed89c6f","custom-607703a1e39b","custom-4336c74424f6"]}]}]
2022/09/08 08:58:30 [DEBUG] DesiredSet - Updated rbac.authorization.k8s.io/v1, Kind=Role fleet-default/crt-<REDACTED>-nodes-manage for auth-prov-v2-roletemplate-<REDACTED> nodes-manage -- application/strategic-merge-patch+json {"metadata":{"annotations":{"objectset.rio.cattle.io/applied":"H4sIAAAAAAAA/4xRTY/bIBD9K9UcK5Oa4NjYUk899FCph9WqlyqHAYYNXQwW4LTSKv+9IrtVrK36cYMH8+Z9PMFMBQ0WhOkJMIRYsLgYcr1G9Y10yVR2ycWdxlI87Vx85wxMgGs5sSXFMzvvWYqeCs2Lx0JMG0ar5mypx5ZD80ei+D1QYg/nR5hgxoAPNFMomw9n0bz55IJ5fxc93b8s+CdhwJlgghANZfbM+18zeUFdB+HSgE50DeLezZQLzgtMYfW+AY+K/F/jOWE+wQS94vuDGMS+l0O3Jz0oGgY96rFFtKq1qA2146Gv214U61Rep8deudjqtJ6oMEMWV1+qw+rkjiwlCpoyTF+fABf3hVJ2McAEtS5Xzy48bFOuHT26UGv94NdcKMFN029trtf+ueJCKdsx3fKedQcpmLIG2SDwICxHYcjC5XhpIK3+JuZjiutSb6CfN+1+sEeZdy7CsYFEOa5J0+fq8vppzSXOjFNr0XDkUiA0v1CSqDk/jGPf9zdUKKV6MnLUvb2hfTsMrUBOYlQ3tBOi10PX7Tu7YRhkK6mXVgm5YRiF4aPppDooudV61TmjPrlAuT6cKakr+BaOl+PlZwAAAP//1WFOc2MDAAA"}},"rules":[{"apiGroups":["cluster.x-k8s.io"],"resourceNames":["custom-1e0fad1a183a","custom-e8ac11599666","custom-3bbb6ed89c6f","custom-607703a1e39b","custom-4336c74424f6","custom-7808e68fb38f","custom-93d19d48b5b8"],"resources":["machines"],"verbs":["*"]}]}
2022/09/08 08:58:30 [DEBUG] DesiredSet - No change(2) /v1, Kind=ServiceAccount fleet-default/custom-7808e68fb38f-machine-plan for rke-machine fleet-default/custom-7808e68fb38f
2022/09/08 08:58:30 [DEBUG] [plansecret] reconciling secret fleet-default/custom-7808e68fb38f-machine-plan
2022/09/08 08:58:30 [DEBUG] [plansecret] fleet-default/custom-7808e68fb38f-machine-plan: rv: 32202835: Reconciling machine PlanApplied condition to nil
2022/09/08 08:58:30 [DEBUG] DesiredSet - No change(2) /v1, Kind=Secret fleet-default/custom-7808e68fb38f-machine-plan for rke-machine fleet-default/custom-7808e68fb38f
2022/09/08 08:58:30 [DEBUG] DesiredSet - No change(2) rbac.authorization.k8s.io/v1, Kind=Role fleet-default/custom-7808e68fb38f-machine-plan for rke-machine fleet-default/custom-7808e68fb38f
2022/09/08 08:58:30 [DEBUG] DesiredSet - No change(2) rbac.authorization.k8s.io/v1, Kind=RoleBinding fleet-default/custom-7808e68fb38f-machine-plan for rke-machine fleet-default/custom-7808e68fb38f
2022/09/08 08:58:30 [DEBUG] [CAPI] Reconciling
2022/09/08 08:58:30 [DEBUG] [CAPI] Cluster still exists
2022/09/08 08:58:30 [DEBUG] DesiredSet - Delete cluster.x-k8s.io/v1beta1, Kind=Cluster fleet-default/<REDACTED> for rke-cluster fleet-default/<REDACTED>
2022/09/08 08:58:30 [DEBUG] DesiredSet - Delete rke.cattle.io/v1, Kind=RKEControlPlane fleet-default/<REDACTED> for rke-cluster fleet-default/<REDACTED>
2022/09/08 08:58:30 [DEBUG] DesiredSet - Delete rke.cattle.io/v1, Kind=RKECluster fleet-default/<REDACTED> for rke-cluster fleet-default/<REDACTED>
2022/09/08 08:58:30 [DEBUG] [rkecontrolplane] (fleet-default/<REDACTED>) Peforming removal of rkecontrolplane
2022/09/08 08:58:30 [DEBUG] [rkecontrolplane] (fleet-default/<REDACTED>) listed 3 machines during removal
2022/09/08 08:58:30 [DEBUG] [UnmanagedMachine] Removing machine fleet-default/custom-607703a1e39b in cluster <REDACTED>
2022/09/08 08:58:30 [DEBUG] [UnmanagedMachine] Safe removal for machine fleet-default/custom-607703a1e39b in cluster <REDACTED> not necessary as it is not an etcd node
On RKE2 bootstrap node in rke2-server logs we can see this:
rke2-server logs on bootstrap node
Sep 07 11:41:57 ip-xxx-xx-xx-xxx rke2[1080]: time="2022-09-07T11:41:57Z" level=info msg="Removing name=ip-yyy-yy-yy-yyy.eu-central-1.compute.internal-ee7ac07c id=1846382134098187668 address=172.28.74.196 from etcd"
Sep 07 11:41:57 ip-xxx-xx-xx-xxx rke2[1080]: time="2022-09-07T11:41:57Z" level=info msg="Removing name=ip-zzz-zz-zz-zzz.eu-central-1.compute.internal-bc3f1edb id=12710303601531451479 address=172.28.70.189 from etcd"
Sep 07 11:42:10 ip-xxx-xx-xx-xxx rke2[1080]: time="2022-09-07T11:42:10Z" level=info msg="Stopped tunnel to zzz.zz.zz.zzz:9345"
Sep 07 11:42:10 ip-xxx-xx-xx-xxx rke2[1080]: time="2022-09-07T11:42:10Z" level=info msg="Stopped tunnel to yyy.yy.yy.yyy:9345"
Sep 07 11:42:10 ip-xxx-xx-xx-xxx rke2[1080]: time="2022-09-07T11:42:10Z" level=info msg="Proxy done" err="context canceled" url="wss://yyy.yy.yy.yyy:9345/v1-rke2/connect"
Sep 07 11:42:10 ip-xxx-xx-xx-xxx rke2[1080]: time="2022-09-07T11:42:10Z" level=info msg="Proxy done" err="context canceled" url="wss://zzz.zz.zz.zzz:9345/v1-rke2/connect"
To Reproduce Unfortunately I can’t reproduce this reliably but this happens very often. Steps I am using to reproduce this issue:
- provision RKE2 cluster with terraform
- modify
additional_manifestfor RKE2 cluster - apply change
Result Occasionally managed cluster gets deleted by rancher.
Expected Result Change is actually applied and clusters is not deleted.
I did some tests that does exactly the same change (modify additional_manifest) bypassing terraform by calling rancher API directly and that never caused cluster deletion for 2k+ iterations. While using terraform provider some times it takes up to 10 attempts to reproduce this issue.
I am happy to provide any other info to investigate this further. This is causing massive outages for my clusters as they are just getting destroyed.
About this issue
- Original URL
- State: open
- Created 2 years ago
- Reactions: 1
- Comments: 54 (9 by maintainers)
Just to expand on the reasoning for the move to Q3, the issue should no longer be reproducible in about-to-be-released Rancher 2.7.5 due to https://github.com/rancher/rancher/issues/41887 fixed there.
This issue is now specifically to fix TFP side to no longer clear finalizers as it’s still not ideal it does that. The priority is much lower though given this “data loss” issue should no longer be happening on Rancher 2.7.5+.
Per @jakefhyde to fix this we will need to switch to using Steve (v1) APIs from currently used Norman (v3) - or even to native k8s - both are pretty big undertakings so this may take a while to address especially since the immediate issue is now addressed on
rancher/ranchersince 2.7.5+.@jakefhyde sure,
This was happening even without backup/restore but after backup/restore it was much easier to reproduce so I am not sure if that is related.
I will try to reproduce this with latest rancher and latest tf provider.
@riuvshyn , thank you for confirming this. We will however keep this issue open as we want to address TF provider removing finalizers as well.
I can confirm that I can not reproduce it anymore on 2.7.5! 🥳 🥳 🥳 🥳 🥳 cc @snasovich @jakefhyde @Oats87 Thank you very much!
@Oats87 Thank you for looking into this. I will investigate this issue
Did some digging into this and it looks like what is happening is
terraformis clearing the finalizers on theprovisioning.cattle.ioobject. Unfortunately, our generating controller will tell run an empty apply (deletion) if this is the case: https://github.com/rancher/rancher/blob/a05de31fccb10059447c169f28dcc2068982a6f0/pkg/controllers/provisioningv2/provisioningcluster/controller.go#L289-L292This is a bug caused by problems in multiple components and while we can resolve it in the codebase for Rancher, I have not deduced a good workaround for this issue at this point. This is likely going to cause problems in other parts of the provider as well, for example, during deletion I would expect that wiping finalizers can lead to orphaned objects.
@jakefhyde
Ok, got this reproduced on fresh setup, even without backup/restore rancher version: 2.7.3 terraform provider: 3.0.0 rke2 version: v1.24.9+rke2r2 terraform: 1.0.8
It took
19iterations to reproduce the only change was applying is label:here is example of
rancher2_cluster_v2resource maybe that will help to reproduce it.Rancher 2.7.2 and TF provider 1.25 - same here. Updated RKE, K3s clusters. RKE2 clusters destroyed and recreated.
Reproduced on
2.7.1I also noticed that issue is much easier to reproduce after performing rancher backup/restore might be it somehow related…cc @Josh-Diamond @jakefhyde
@jakefhyde I have an update on this one: I believe that this is rancher backup/restore operator causing this. Sometimes when I perform rancher restore operation I am hitting errors like that:
And that is happening I believe because rancher backup / restore operator is supposed to scale down rancher before doing actual restore and it is doing that
but it doesn’t wait for it to actually be fully stopped and starts restore right away and since termination is not instant and restore is already happening it corrupts the data somehow and after restore is complete with such errors then this bug can be reproduced changing just a label via terraform on a managed cluster cause cluster deletion.
So maybe there is nothing to do with terraform provider actually…
@jakefhyde I think I finally figured out how to reproduce it… Recently on one of the rancher env setups I wasn’t able to reproduce this issue at all, which was very confusing because few days before It was definitely happening there. So then I’ve noticed that this cluster that hosts rancher was re-provisioned and it is in kind of “fresh” state. I’ve also checked that on previous iteration of that cluster were executed some tests for backup/restore rancher with backup-restore-operator. So on that “fresh” rancher setup I have provisioned rke2 cluster the same way it is described in this ticket, performed backup and restrore of rancher and then started simple test (modify cluster label and label in manifests defined in all nodes are deleted except this one I guess it is stuck on some finalizer.
all nodes are deleted except this one I guess it is stuck on some finalizer.
additional_manifest) again and my on 3rd iteration my cluster got to that state:so steps to reproduce it:
nodeCommandprune: falserancher2_cluster_v2change cluster labels and anything inadditional_manifestX times until issue is reproduced.Additional notes: when that issue happens and I destroy broken cluster (it disappear from rancher UI) then re-provision the same cluster back everything looks normal but that issue is still can be reproduced with this cluster just by modifying cluster config via terraform provider.
I hope that will help you to reproduce this.
This seems to be outdated information. RKE2 provisioning is GA since a long time… I believe with 2.6.3 it got GA. Just K3S seems to be tech preview, still.