rancher: Unable to provision harvester rke2 cluster from rancher, stuck in provisioning on bootstrap node
Rancher Server Setup
- Rancher version: v2.6-head (
1d2b746) - Installation option (Docker install/Helm Chart): Docker
Information about the Cluster
- Kubernetes version: v1.22.6+rke2r1
- Cluster Type (Local/Downstream): Infrastructure Provider - Harvester
User Information
- What is the role of the user logged in? Admin
Describe the bug
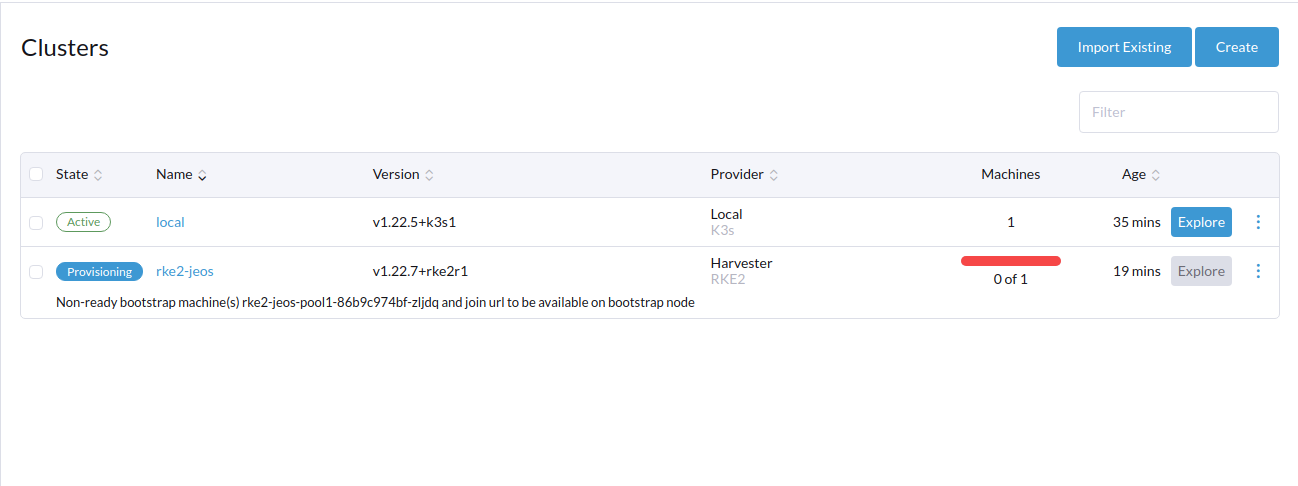
Unable to provision RKE2 cluster from rancher v2.6-head, keep in Provisioning status with message
This issue exists on both RKE2 1.22.7+rke2r1 and 1.21.10+rke2r1
Non-ready bootstrap machine(s) rke2-ubuntu-pool1-bcfd5cfbb-2pj9w and join url to be available on bootstrap node
Further checking cluster node status in RKE2 VM, it looks like node have taints to prevent component to finish deployment.
# ssh to rke2 virtual machine
export KUBECONFIG=/etc/rancher/rke2/rke2.yaml
/var/lib/rancher/rke2/bin/kubectl get nodes -o yaml
spec:
podCIDR: 10.42.0.0/24
podCIDRs:
- 10.42.0.0/24
taints:
- effect: NoSchedule
key: node.cloudprovider.kubernetes.io/uninitialized
value: "true"
To Reproduce
- Create a one node or three nodes harvester cluster
- Prepare SLES JeOS image
SLES15-SP3-JeOS.x86_64-15.3-OpenStack-Cloud-GM.qcow2 - Enable virtual network to
harvester-mgmt - Create virtual network
vlan1with id1 - Import harvester in rancher v2.6-head
- Create cloud credential
- Provision a RKE2 cluster with SLES JeOS image
- Check the RKE2 cluster provisioning to
Ready
Result
Provisioning stuck in Non-ready bootstrap machine(s) rke2-ubuntu-pool1-bcfd5cfbb-2pj9w and join url to be available on bootstrap node
Expected Result
Can provision RKE2 cluster in harvester correctly in acceptable time for major OS image (e.g SLES, Ubuntu)
Additional context
-
Harvester support bundle supportbundle_74b92604-c442-4d1d-a70d-7313e32ac47c_2022-03-02T13-14-35Z.zip
-
Rancher container log rancher2.6-head_rke2_sles.log
About this issue
- Original URL
- State: closed
- Created 2 years ago
- Comments: 34 (5 by maintainers)
Commits related to this issue
- Bump harvester-cloud-provider 0.1.10 Related issue: https://github.com/rancher/rancher/issues/36716 https://github.com/harvester/harvester/issues/1999 Signed-off-by: yaocw2020 <yaocanwu@gmail.com> — committed to yaocw2020/rke2 by yaocw2020 2 years ago
- Bump harvester-cloud-provider 0.1.10 Related issue: https://github.com/rancher/rancher/issues/36716 https://github.com/harvester/harvester/issues/1999 Signed-off-by: yaocw2020 <yaocanwu@gmail.com> — committed to yaocw2020/rke2 by yaocw2020 2 years ago
- Bump harvester-cloud-provider 0.1.10 Related issue: https://github.com/rancher/rancher/issues/36716 https://github.com/harvester/harvester/issues/1999 Signed-off-by: yaocw2020 <yaocanwu@gmail.com> — committed to yaocw2020/rke2-charts by yaocw2020 2 years ago
- Bump harvester-cloud-provider 0.1.10 Related issue: https://github.com/rancher/rancher/issues/36716 https://github.com/harvester/harvester/issues/1999 Signed-off-by: yaocw2020 <yaocanwu@gmail.com> — committed to yaocw2020/rke2-charts by yaocw2020 2 years ago
- Bump harvester-cloud-provider 0.1.10 Related issue: https://github.com/rancher/rancher/issues/36716 https://github.com/harvester/harvester/issues/1999 Signed-off-by: yaocw2020 <yaocanwu@gmail.com> — committed to rancher/rke2-charts by yaocw2020 2 years ago
- Bump harvester-cloud-provider 0.1.10 Related issue: https://github.com/rancher/rancher/issues/36716 https://github.com/harvester/harvester/issues/1999 Signed-off-by: yaocw2020 <yaocanwu@gmail.com> — committed to rancher/rke2-charts by actions-user 2 years ago
Closing it as it was supposed to be closed a few days ago and got reopened due to Zube requiring “Done” label on issues. @TachunLin, I see a comment above by @lanfon72 that this may still be an issue or there is another related issue, please handle it as necessary.
According to what I learnt (thanks @FrankYang0529 ), the harvester-cloud-provider is the one removing the taint
node.cloudprovider.kubernetes.io/uninitializedonce it considers the node is ready. That provider fails with the error:And thus it is unable to remove the taint.
I am confused about why it requires the CNI plugin to be running. The url
https://192.168.0.131:6443/apis/....looks like a call to kube-api and kube-api is running inhostNetwork: true, i.e. it does not require a cni plugin to run. Could you verify if192.168.0.131is the IP where kube-api is running?Let me ask around. Before adding that toleration, I want to make sure that it will not introduce regression or other problems
@thedadams, it looks like the root cause is
Calicocan’t be installed. If we change CNI toCanal, RKE21.22.7+rke2r1can be installed.In RKE2
1.22.7+rke2r1, it upgradestigera-operatortov1.23.5. Also,tigera-operatorupdates tolerations incalico-typha. Originally, intigera-operator v1.17.6, it use tolerations forcalico-typhalike following, so we can install RKE21.21.10+rke2r1without error.However, in
tigera-operator v1.23.5, it adds keys to tolerations like following, socalico-typhacan’t toleratenode.cloudprovider.kubernetes.io/uninitialized.@TachunLin The SLES issue seems to be unrelated to the issue with Ubuntu. Rancher is not responsible for installing the apparmor-parser, so the SLES issue is understood (the installation of apparmor-parser could be added to rancher-machine when the SLES operating system is detected).
For the Ubuntu image case, the nodes are tainted as
NoSchedulebecause the cloud-provider (Harvester, in this case) isn’t setup on the node. Has it been verified that the Harvester cloud-provider is running successfully on these nodes? And has the Harvester cloud-provider been tested on Kubernetes v1.22+ outside of Rancher provisioning?