pulumi: pulumi {preview/up/...} is slow with medium sized TS stack
I have a medium sized stack (181 total resources) with an AKS cluster, a few supporting azure resources, nginx-ingress, cert-manager, and a few other kubernetes resources.
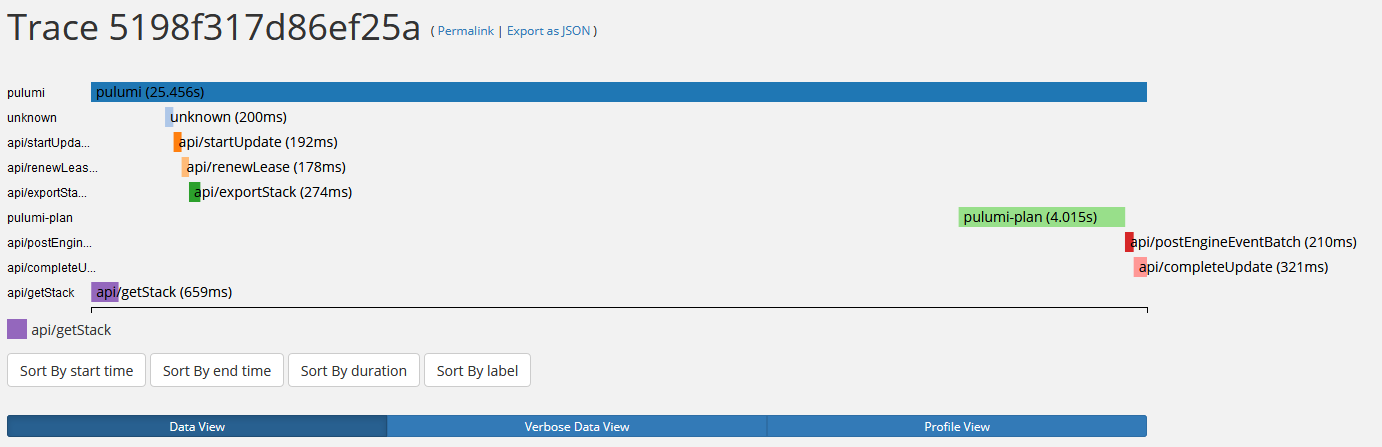
I took a trace of a no-op up:
pulumi up --skip-preview --tracing=file:./up.trace
If you want to take a look, I can send you the details (update url and trace file [170MB]) per email or chat. (note to self: it’s update # 27)
A few things I noticed myself: there are a lot of calls to api/decryptValue, each about 150ms to 200ms.
The pulumi trace alone is 1m 9s:

Also, apparently the time logging is wrong/incomplete. In the console output it says Duration: 35s (I didn’t stop the time myself), but in the trace file its over a minute.
Inside there, it’s mostly /pulumirpc.ResourceMonitor/RegisterResource and /pulumirpc.ResourceMonitor/RegisterResource with 1s to 6s each.

I’m on windows 10 x64 with pulumi 3.9.0. The environment is Typescript / node. I’m mostly using “@pulumi/azure-native” and “@pulumi/kubernetes”.
Edit: I ran pulumi up --skip-preview (no-op) again and stopped the time with my phone. It took 1m 4s in reality, the cli output said 32s.
Edit2: pulumi refresh --target i_do_not_exist takes about 30 seconds:
About this issue
- Original URL
- State: open
- Created 3 years ago
- Reactions: 7
- Comments: 15 (3 by maintainers)
similar issue, deploy 90+ cronjob to k8s
pulumi python
after skip checkpoint deploy is fast
@0x53A Have you find a solution ? I’m still stuck on a stack with 1300 resources… And no solution other than remove resources in my state file… I’m still searching another way to manage secrets. I will probably use vault (hashicorp).