pandas: "cannot reindex from a duplicate axis" when groupby().apply() on MultiIndex columns
Code Sample, a copy-pastable example if possible
import pandas as pd
import numpy as np
df = pd.DataFrame(
np.ones([6, 4], dtype=int),
columns=pd.MultiIndex.from_product([['A', 'B'], [1, 2]])
)
(
df
.groupby(level=0, axis=1)
.apply(
lambda df: pd.concat(
[df.xs(df.name, axis=1), df.sum(axis=1).to_frame('Total')],
axis=1
)
)
)
Problem description
The code above produces the error:
cannot reindex from a duplicate axis
I believe this is a bug because, as described below, essentially the same operations can be successfully run along the other axis.
Expected Output
It should, as far as I can tell, produce the following output:
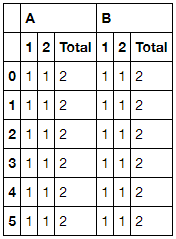
The desired output can be obtained when working on the transposed DataFrame along the index rather than the columns:
(
df
.T
.groupby(level=0)
.apply(
lambda df: pd.concat(
[df.xs(df.name), df.sum().to_frame('Total').T]
)
)
.T
)
Output of pd.show_versions()
pd.show_versions() pd.show_versions()
INSTALLED VERSIONS
commit: None python: 2.7.9.final.0 python-bits: 64 OS: Windows OS-release: 8 machine: AMD64 processor: Intel64 Family 6 Model 69 Stepping 1, GenuineIntel byteorder: little LC_ALL: None LANG: None LOCALE: None.None
pandas: 0.20.2 pytest: None pip: 9.0.1 setuptools: 34.3.3 Cython: None numpy: 1.13.0 scipy: 0.19.0 xarray: None IPython: 5.3.0 sphinx: None patsy: None dateutil: 2.6.0 pytz: 2017.2 blosc: None bottleneck: None tables: None numexpr: None feather: None matplotlib: 2.0.0 openpyxl: None xlrd: 1.0.0 xlwt: None xlsxwriter: None lxml: None bs4: None html5lib: 0.999 sqlalchemy: None pymysql: None psycopg2: 2.7.1 (dt dec pq3 ext lo64) jinja2: 2.9.5 s3fs: None pandas_gbq: None pandas_datareader: None
About this issue
- Original URL
- State: closed
- Created 7 years ago
- Reactions: 2
- Comments: 18 (15 by maintainers)
I’m facing the same issue when trying to interpolate each series within a group:
Anything obvious?
Edit: It works, however, if I
df.reset_index(inplace=True)before grouping.@pwwang - mutating a DataFrame in apply is not supported, see here:
https://pandas.pydata.org/docs/user_guide/gotchas.html#mutating-with-user-defined-function-udf-methods
@bdforbes If you follow the instructions on website, it’s not too hard.
https://pandas.pydata.org/docs/development/contributing.html#creating-a-python-environment
There is an hour or two to set up a C-compiler, git etc, but after that you can clone the repo and work current master/PR branches.
@kernc Thank you thank you for the amazing workaround!
i.e.
I have the same issue here. This seems to have something to do with index of the data frame. Please see the following example to reproduce the error:
Error:
ValueError: cannot reindex from a duplicate axisHowever, the following code which only differs by one element in the index will execute without producing the error:
Note that the only change is the index of the second row.
python 3.5 pandas 0.20.3