openvino_notebooks: Why is the quantified convnext model still slower than the original 32-bit unquantified model
Describe the bug A clear and concise description of what the bug is, including steps to reproduce the bug if possible.
Expected behavior A clear and concise description of what you expected to happen.
Screenshots If applicable, add screenshots to help explain your problem.
Installation instructions (Please mark the checkbox) [ ] I followed the installation guide at https://github.com/openvinotoolkit/openvino_notebooks#-installation-guide to install the notebooks.
** Environment information **
Please run python check_install.py in the openvino_notebooks directory. If the output is NOT OK for any of the checks, please follow the instructions to fix that. If that does not work, or if you still encounter the issue, please paste the output of check_install.py here.
Additional context Add any other context about the problem here.
 这是我量化后的结果,
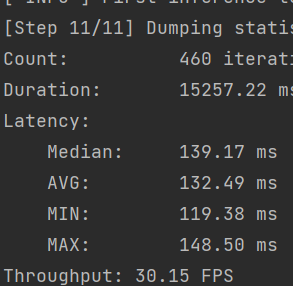
我测了一下32位IR中间模型的速度如下图
这是我量化后的结果,
我测了一下32位IR中间模型的速度如下图

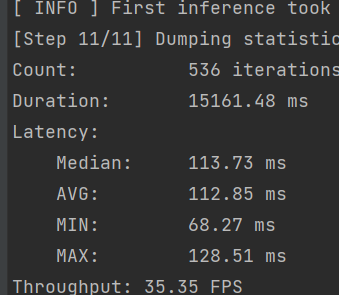
这是量化后的速度

 为什么量化后还掉了5帧
为什么量化后还掉了5帧
About this issue
- Original URL
- State: closed
- Created 2 years ago
- Comments: 16 (6 by maintainers)
INT8 quantized/re-trained/trained models make most sense if the underlying HW (SoC/CPU) has VNNI/AVXxxx/AMX/TMUL/BF16 instruction set available.
Were performance-per-layer measures done (see e.g. “https://docs.openvino.ai/latest/openvino_inference_engine_tools_benchmark_tool_README.html#per-layer-performance-and-logging”) to identify where most of the resources were used? (maybe the model’s convolution-kernel-sizes are not ideal)