openvino: [Bug]inference speed of OCR recognition with OpenVINO slower than onnxruntime
System information (version)
- OpenVINO=> 2022.1
- Operating System / Platform => ubuntu 22.04

Detailed description
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/doc/doc_ch/models_list.md

I am using this ocr model of paddle, here is the download address:
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tar
Steps to reproduce
This is my configuration, I loaded the paddle model directly, and converted it to the onnx model with paddle2onnx, without any modification.

But I found that when I use openvino inference, it takes at least 2.5ms, although there are fluctuations, it is always above 2ms

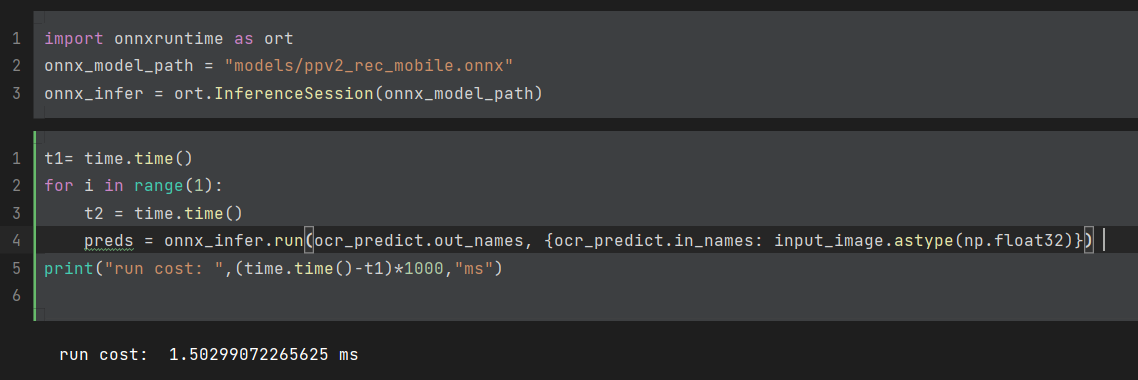
However, the inference time under onnxruntime only needs to be within 2ms, and even 1.6ms , compared with openvino is much faster.
I have also tried to read the converted onnx file directly with openvino, the phenomenon is still unchanged.
I want to know what is the reason for this? How can I fix it, thanks!
About this issue
- Original URL
- State: closed
- Created a year ago
- Comments: 15 (7 by maintainers)
Hello @jiwaszki , I totally found the problem, the key is :
det_net.reshape(input_image.shape), the static graph mode will run faster.But for OCR task, we can’t set the shape completely static, because the length may be different, so the last parameter can’t be fixed:
det_net.reshape([1,3,32,-1])That way it’s not as fast, but still faster than onnx.Overall I’ve completely solved this problem, cheers to openvino 😄
Thanks again for your serious help.
You completely answered my doubts, thank you very much for your serious reply! 👍
I have one final question, where can I get the latest async API? The api manuals on the documentation seem to be aligned with the c++ version, i want to see the python code.