opensearch-k8s-operator: Cluster failure after migrating nodepool 'master not discovered or elected yet, an election requires at least 2 nodes with ids'
With a successfully running cluster with 3 master I needed to migrate to a new nodepool (unrelated)
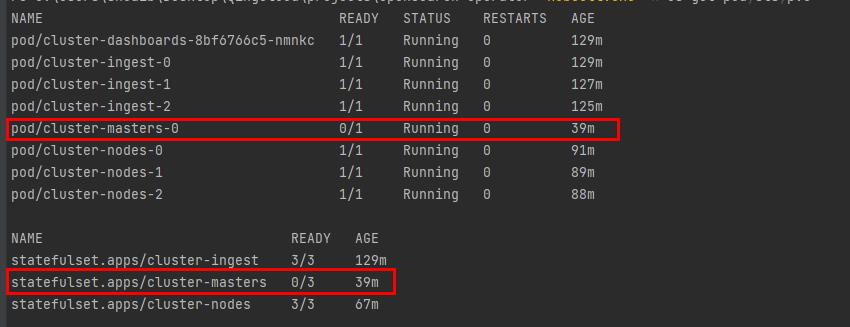
However after migration the cluster was in an unusable state a single master was running cluster-master-0 with the following error in the logs
[cluster-masters-0] master not discovered or elected yet, an election requires at least 2 nodes with ids from [LNCCMf06T4-3j8DIibFf2g, Y4A36mMzRNeVtsWy7A2kEw, RLoWaFxKSDy04rOanWh50Q],have discovered [{cluster-masters-0}{Y4A36mMzRNeVtsWy7A2kEw}{s43hlqGfRfq1IaTL7kXAtw}{cluster-masters-0} {10.104.8.14:9300}{dm}{shard_indexing_pressure_enabled=true}] which is not a quorum; discovery will continue using [] from hosts providers and [{cluster-masters-0}{Y4A36mMzRNeVtsWy7A2kEw}{s43hlqGfRfq1IaTL7kXAtw}{cluster-masters-0}{10.104.8.14:9300}{dm}{shard_indexing_pressure_enabled=true}]from last-known cluster state; node term 6, last-accepted version 50 in term 5
I think i need to add a podDisruptionBudget to ensure 2 pods are running while doing a migration of this sort, but I cannot see that option in the cluster config
About this issue
- Original URL
- State: closed
- Created 2 years ago
- Reactions: 1
- Comments: 17 (1 by maintainers)
Ran into this issue. I scaled the operator to zero replicas, then deleted the statefulset with
--cascade=orphan, then recreated the statefulset withpodManagementPolicyset toParallel. then once recovered, delete the statefulset again and switch it back toOrderedReady.@ahmedrshdy
(with Operator installed via helm chart version 2.0.4) After the cluster was fully formed I ran
kubectl delete pod my-cluster-masters-2. The pod was recreated and became healthy. I’m testing this on a local k3d cluster.Right, sorry, didn’t think of this.
@ahmedrshdy
I cannot reproduce this. Deploying a cluster and then deleting a master pod will recreate the pod and after about two minutes the pod was healthy again in my experiments.
@mahdiG
The case with deleting just one pod I could not reproduce. In my experiments the other pods stayed up. But I agree that if all the pods are deleted at the same time the cluster currently does not come back up again.
As this issue is already a mix of discussion I’ve created #289 to track this problem separately.
@wesleyjconnorsesame. In regards to Downsizing not happening with enabled smartscaler: This is likely the same cause as in #227, PR is on the way.
@jinchengsix: I think I understand now what is happening: The statefulsets for the nodepools are configured with a podManagementPolicy of
OrderedReady. This means kubernetes waits for the first pod to be ready before starting the second. This is normally a good thing as it helps the operator do operations in a rolling manner while always keeping the cluster in a working state. During initial cluster setup the operator works around the quorum problem by launching a separate bootstrap pod to faciliate that. But all this means that for your case the cluster will not come back up as the first pod never gets ready without being able to form a quorum. Not sure if this is a situation we want to handle in the operator. If you feel so please open a new issue so we have it on the roadmap as a potential enhancement. As a hack to recover a cluster in this situation you can try to manually edit the statefulset (cluster-mastersin your case) and temporarily set thepodManagementPolicytoParallel.@swoehrl-mw hi , I got the same error, not sure if it’s the the same, what I did is as follow
opensearch-cluster.yaml
screenshot