openMVG: Using robust_essential_spherical is not behaving as expected
Firstly, thanks for your cracking work and open sourcing this repo - I feel like I am definitely standing on the shoulders of giants!
The problem case I have is so get the relative rotation between two cameras from two spherical panoramic images, the relative cartesian transformation is a bonus. An example of two images I want to extract the camera poses for are copied below for reference (Theta_R0010732_2048.jpg (L) and Theta_R0010733_2048.jpg ®).

and

The problems (and I appreciate that this is merely a sample code) that I wondered if you could advise me on are:
-
First, and it is a big one - is my use case what this example solver is built for? I am concerned that this solver is merely for “left eye - right eye” “VR-type” solves… I don’t think this is the case as the SIFT solver is obviously generic.
-
The test images
SponzaLion000.jpgandSponzaLion001.jpgare not RGB images and seem to be a strange format - can I use RGB images like my examples above or do they need a pre-processing step? The test images look like Gaussian scale-space… -
Ordering - I have the two attached images solving when I use
-a "Theta_R0010732_2048.jpg" -b "Theta_R0010733_2048.jpg"(positioning in a clockwise order) but if I switch the order the final stage of the processing
if (RelativePoseFromEssential(
xL_spherical,
xR_spherical,
E,
vec_inliers,
&relative_pose,
&inliers_indexes,
&inliers_X))
{
...
}
never manages to satisfy
// Test if the best solution is good by using the ratio of the two best solution score
std::sort(cheirality_accumulator.begin(), cheirality_accumulator.end());
const double ratio = cheirality_accumulator.rbegin()[1] / static_cast<double>(cheirality_accumulator.rbegin()[0]);
return (ratio < positive_depth_solution_ratio);
and no pose information is output. Why is the code not agnostic to image ordering?
I think that will do for now, thank you in advance, you time is most appreciated.
About this issue
- Original URL
- State: open
- Created 2 years ago
- Comments: 22 (7 by maintainers)
Possible tips to make a better job with OpenMVG tools (leverage the fact that you have upright cameras):
Just downloaded the image you shared and ran the default openMVG example:
As we see we don’t have a perfect outlier filtering, but some of the structure seems to be matched and identified
Tweaking the code and setting a scricter threshold for ACRANSAC (
const double precision = D2R(4.0);// std::numeric_limits<double>::infinity();) is doing a more conservative filteringand seems to give something plausible for the 3D relative pose and scene points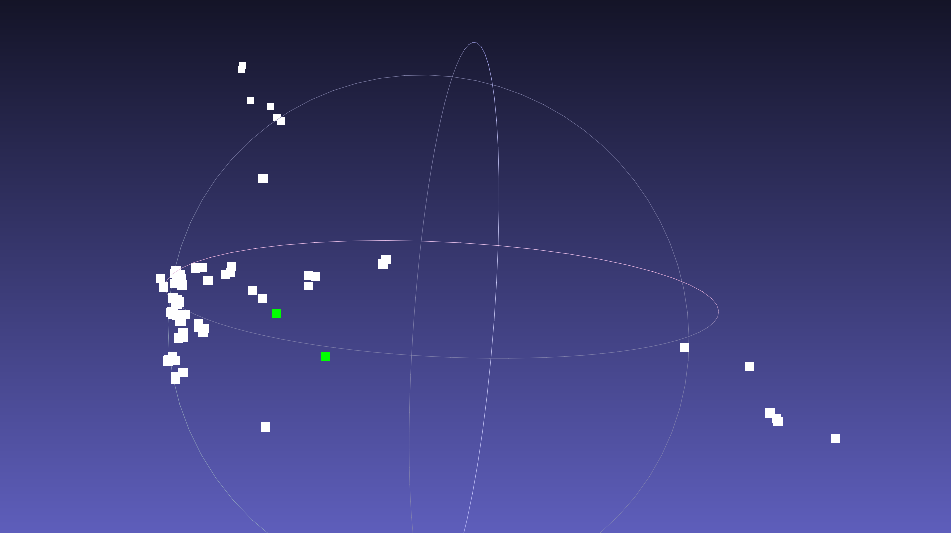
Hi @pmoulon, sorry to comeback to you on this again; I don’t have an issue per-se, so I do not want to open another thread, but would like some advice if you would be so kind…
I now have the solver above working very well for the current use case we have - getting relative pose from two panoramas. The poses returned are in some arbitrary RVU, which are crucially not the same access different solves. The use case is that I wish to plot the poses of several cameras as the photographer moves in space and with real world scale. How we are doing this currently for three images (0, 1 and 2) for example is
We then do the same for panos 1 and 2 - we then have both poses in real world scale and can then cascade the transforms to give all three poses relative to each other (we can do this for N cameras).
This is working relatively well and is only restricted by the accuracy of the depth coming out of our ML model and the inferrance of the depth to the inliers. And now my questions…
I have noticed that Agisoft can solve the relative pose positions of multiple (more than two) cameras in one batch and that the results are in the same RVU so the scaling is consistent and the relative positions are consistent.
If the answer to 2 is that it is not major work, the plan would be to solve for poses of multiple cameras in consistent RVU - but then apply a single real world scale conversion based on the best estimate from the ML to give a consistent scale across all images/poses.
I would be interested also to see if you are available for some paid consultancy work. (my email address is nfcamus<at>gmail.com if you have any interest in this).
Hi @pmoulon, I have, what I think you agree, is a fairly interesting problem. I have adjusted your example above, and have this working perfectly for what we need. The problem is that although the openMVG algos are generating the correct relative poses for the two cameras, the scaling is in some arbitrary Relative Value Units. As part of our efforts, we have a cool ML model that can convert spherical panos to depth maps and provide very accurate real world depth. So, the idea is to use the ML model and the depth maps it produces to establish the real world relative poses between two cameras - to do this I do the following:
The approach seems to work fine - HOWEVER, I think the inlier “feature points” from the
are not what I think they are. I had assumed that these feature points were actual features in the geometry, where as from some tests I have undertaken, they do not seem to be. Is there anything in any of the “sub-algos” that I can hook into to somehow get any estimation of a “physical” feature to use with my auto scaling technique (defined above)?
Again, thank you very much for your time, it is most appreciate.
*Ps. I have run tests and set the scale estimation algo to reverse engineer a depth map from the corresponding ply so I am confident (with additional unit test) that the inverse equirectangular projection I am doing is correct. *