Nuitka: Nuitka makes plus and minus much slower
I’ve tried to compile a performance test using nuitka 0.6.13rc2 in order to again investigate in what extent can Nuitka speed up a python program. It showed Nuitka made the plus and minus operation 15%~20% slower than before, but Nuitka also speed up multiply operation about 60% that’s incredible! Besides, I’m also curious about using which compiler would make program faster msvc or mingw64?
Platform: Windows CPU: Ryzen7 1700 RAM: DDR4-3200*2 Python: 3.8.7 (x64) Nuitka: 0.6.13rc2
Before:

Compiler command (msvc):
nuitka --msvc=MSVC --windows-disable-console --standalone --show-progress --output-dir=C:\Users\home\Desktop\1 C:\Users\home\PycharmProjects\speedtest\venv\main.py

Compiler command (mingw64):
nuitka --mingw64 --windows-disable-console --standalone --show-progress --output-dir=C:\Users\home\Desktop\1 C:\Users\home\PycharmProjects\speedtest\venv\main.py

Code:
import time
import os
def plus():
a = 0
for x in range(100000000):
a += 1
def minus():
a = 100000000
for x in range(100000000):
a -= 1
def multiply():
a = 1
for x in range(100000000):
a *= 1.00000003
def divide():
a = 1000000000
for x in range(100000000):
a /= 1.00000003
if __name__ == '__main__':
s = time.time()
plus()
e = time.time()
print('Plus:',round(100000000/(e-s)/1000000,2),'M/s')
s = time.time()
minus()
e = time.time()
print('Minus:',round(100000000/(e-s)/1000000,2),'M/s')
s = time.time()
multiply()
e = time.time()
print('Multiply:',round(100000000/(e-s)/1000000,2),'M/s')
s = time.time()
divide()
e = time.time()
print('Divide:',round(100000000/(e-s)/1000000,2),'M/s')
os.system('pause')
About this issue
- Original URL
- State: closed
- Created 3 years ago
- Comments: 35 (30 by maintainers)
Part of the 0.6.13 release.
Appyling the lessons learned to binary operations for consistency also, is for 0.6.14. I will keep this open, because I want to work on the other things mentioned in that cycle potentially too.
Very cool!
The improvement for 3.9 makes this about 20% faster. For 0.6.16 we will see what Nuitka Python can do. With static linking rather than DLL linkage, I expect a huge gain again.
Much more of a speed bump than I had hoped for. I worked on the larger integer in-place support, and turns out, I found a couple of bugs in the code of factory for this, but nothing too that should impact performance I guess. Unfortunately I couldn’t get it stable with using realloc to expand longs, so I have to drop the old object after copying it manually all the time, but of course only if I believe, that “+” will overflow into a new digit, which is rare.
Expressed in decimals, if you add
4xxxand5xxxyou have to assume 5 digits could be needed, but for4xxxand4xxxyou already know it’s not the case. With the large digits of2**15or2**30that’s relatively unlikely, most of the time, the right value has less digits, in which case only a9xxxcould overflow, so this can be ruled out. What I don’t quiet like is that currently, I cannot tell the allocated size of alongbut only the used size, so once it got allocated bigger, it should not do that again, otherwise it will loose the in-place advantage we gained here. But that’s probably doable somehow.So, I took on the “PyLong” and did recreate the algorithm for “+” and “-”, following what Python2 and Python3 do. For Python2, longs gained a lot of performance from just doing that, but of course, that won’t matter much. It should get even more, with optimization for low digit amount values that are taken from Python3.
But the Python2 improvement there is only a side effect, real Python2 programs barely use them. For Python3, the immediate result was 3% more gain, which is not too bad given that on Linux, this mostly only avoids some branches and testing.
But I took it further, and for Python3, the main trick is to special case long creation for small values. Making sure we create the long values for small integers on our own, gave 8% improvement even when I use relatively large values, just because our creation code is slightly smarter I guess. And if I allow to increment a while in the -7 to 256 range, by going with “1” increments, there were relatively massive gains of 30%.
This is creating and working with
PyLongObject *which require allocation. It will get plenty more interesting, if we reuse the object in the in-place operation, this will need more refinements. Most importantly, rather than withPyLongObjectthe sub/add algorithm needs to work with pointers of digits, and signs separated.If done correctly, we should be able to make the
addof these be able to work on digits as both input and output, i.e. the operation will be in-place all the time. The only thing that might happen, is that a “carry” requires an extra digit, in which case we have to trigger a re-allocation of the object to grow it by a digit. That way, in-place of integer values will be real and there is hope for a massive increase, as the malloc/free cycle must be painful.Right now I didn’t update factory with this code yet, as I am still evaluatings its correctness in my internal CI, was looking good so far though. The described steps seem not too hard. I think we will get into big trouble though, when we look at e.g.
longmultiplication. So I might just continue and perfect the add/sub operations of longs with the described method.Of course, what we are doing here is to catch up with Nuitka and Python3 lagging behind. For Windows, the avoided calls do not play a role here, in fact, the slot original usage was probably roughly as good within 3-8% margins, so I am not expecting any extra bonus from that side of things. However, there is
PyInt_FromLongcalls in many places, and for Python2, a similar optimization of having our own creation code will give also a few perfect, but also very importantly avoid the Windows DLL call overhead. So I might be tempted to do a similar optimization for theintvalues of Python2 as well. It’s easy enough it seems.Being able to pass the “+= 1” as a CLONG value rather than an object, that’s where I expect more optimization to happen from the C compiler side, because that’s easier for it, that should give a few extra percent plus smaller programs, if it were not for the overhead of having these special entry points for operations in the first place.
So this is on a roll. I am hoping this could become part of the next release already, but then it’s probably overdue already.
Python: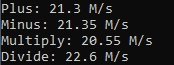
Nuitka Factory: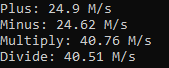
WOW!
Windows 10 20H2
python 3.9.2nuitka (--clang)nuitka (--mingw64)So, I have done actually a lot of refactoring, and made it so that the binary operation code is going to be re-usable for in-place. While doing that, more types were adding, namely
strandunicodefor concat, and repeat and concat slots are now also generated, instead of done manually, and also should be a lot easier to reuse.I have started the work on avoiding the CPython API for inlining. With all but lists, I think there is no special inlining code for any known type. So we basically only have to reuse the binary operation code for that, and then check if an in-place operation will be possible for them. That will be easy, but doing the full
OBJECT_OBJECTcall manually ourselves is what I am aiming at, so a bit more work will be needed, to fit the in-place repeat and concat there as well. But it all seems well prepared now.This was basically cleaning up massive amounts of technical debt for the code generation using inline and manual helpers in a mix, and only partial completion, and initially things being done with
returnbased results, where nowgotoexits for various C types, allow much neater code. For the binary operation it won’t matter as much, but for in-place it will be allowing a huge improvement over what CPython can do. I will be very exited, once we see the float in-place re-use the same object storage and therefore being incredibly fast.Obviously also very time consuming activity, but luckily 3.9 is sorted out, so there is room for that until 3.10 detracts me again.
For Python3 it’s using
BINARY_OPERATION_ADD_LONG_LONG_INPLACEwhich ought to be good.For the
+=on Python2 it’s usingBINARY_OPERATION_ADD_OBJECT_INT_INPLACEwhich has unnecessary overhead. That is because it might overflow to alongobject, so that the type inference gives up, and the alternative type, which would allow for bothlongandintis not yet implemented, as it’s also waiting for the Clongtype. So that’s expected.I feel there is nothing I really want to do about the float case, it’s pathological in that having an
elsebranch for reference count not being 1 causes the reference count path to be slower. Not that the check is not done, just that there is an else, of what the compiler must clearly see is an exit really soon. Moving the return there don’t help. So I am just going to let that one slide. It is going to make the cases where floats get added first and only time faster. I blame gcc on this.The good news is that none of the extra variables introduced to make the code reusable and more well suited for generation will be hurt. And of course, we want the
FLOAT_FLOATto happen in the normal case anyway, although, thinking of it, that should have the same issue.Ok, my macro skills in Jinja are good, I made it such that if such a fast path exists, the code is put into a function to not inline, and otherwise the code is inline, as it’s the only thing we got there, giving a nice 1.5% boost even to inplace long multiplication, where our special case is not really all that special.
With that, float add inplace went down from 7.7M ticks to 4.5M ticks, but it seems it’s 4.25M ticks on stable, that is still a 5% loss, need to check that out. Floats do get preferential treatment for a long time too.
I experimented further, and compared this with Python int, aka long, and there is of course no valid comparison with stable, which had 71.4M ticks and now does 28.2M on current factory, but applying what I learnt there from Python2 int, moving the bulk of the fallback code out of sight, improves this too, and 26.7M seems a lot of reduction, that is a 5.5% gain just like that.
I am now almost convinced, that the binary operations are doing it wrong, as they have done this for longer, and probably also will be able to gain around that range. Depending on type there seem to be differences, but Python2 int numbers improve by 7% even, that would suggest that float value operations will also benefit even more.
Now I just need to adapt the Jinja2 code generation in a fashion that this is automatic, making the improvements universal. Not sure if I want to include binary operations immediately. Something in me wants to, but I also need to make the release finally.
I have started the performance comparison, and I noticed that integer inplace add, and other operations are actually slower now when done with partial knowledge. This has two reasons.
First, the delegation to the
INT_INThelper is not as fast as doing right there, essentially we are not forcing an inline of that function. That’s not too hard, it brings things down from >17M ticks to >16M ticks, but the stable version was still at ca 15.4M ticks. Second, turns out, that if I replace the old generic inplace code fallback (that is unused), it goes down to 14.4M ticks, the new code is big. Even when I modified the code by hand, moving the unused code to the outside in a separate function to be called, that result persisted.So, the question is, how to get those 14.4M ticks without sacrificing sanity. Something is causing that function to be inlined, even if big, and that to be a slow down to its fast path. Since it’s calling an external function when it’s fast, I assume that making it e.g. not “static” might help and it does, somewhat, performance goes ti 14.6M in that case. Removing the inline annotation doesn’t change anything, compilers ignore that anyway these days.
Very annoying to loose 0.2M ticks to a code path not taken. And marking that branch to be “likely” that guards the specialization actually lost another 0.2M ticks to 14.8M. Using
HEDLEY_NEVER_INLINEhas the same effect as removingstatic, same ticks.I am very disappointed, by
likelyfailing to improve, that’s worth an investigation if there is something astray there, since the branch is always taken, it cannot really be slower.However, it seems, the strategy needs to be, to make these mixed type things use a separate function for the slow fallback paths and making that noinline. But then, apparently, a code path that wasn’t supposed to be improved, namely the in-place integer add of Python2, will be too. The new Jinja templated code going over clong exits that cascade seems to be a lot better than the old one.
When I tried to just replace the new code with the old code, time is going up by 0.3M ticks (in what seems to be the best environment for such code to live), that’s still in percentage ranges.
It will take a bit of cleanups to manage and get that slow path stuff sorted out that way.
Without any further changes, this is on develop now and will be part of the next release. The
CLONGstuff will be done as part of the next iteration.Even more work on large integer in-place support, and I think it’s ready for prime time. During the work I found a few more bugs, e.g. when translating to in-place, some cases were not setting the sign away from previous sign, because they did’t change the default sign of a new object, bugs and stuff, that was pretty touch to debug in some cases.
Still need to figure out how to access the actual allocation size of a long value when doing the in-place, but since overflow of digits back and forth is not going to be all that common, this is not needed. I think these improvements are now ready for prime time, and my next step will be that experimental usage of
LONG_CLONGandINT_CLONGoperations I have been talking of.For that, the code should be well prepared with the functions working on digit pointers already, and it should be possible to abstract this further. But since for
intof Python2, I have the templating already in place, again that’s where I am going to start this, but of course, once it works, doing the Jinja templating work to also have it forlongwill work that’s doable.Checking out other operations, e.g.
*and even%, I noticed it’s really terrible code that needs to be written there. I might throw that in on a bad day, but it’s not an immediate goal. I want to first strengen code generation now, and then type tracing in loops so as to get rid of theOBJECT_LONGthat we are seeing, and only then revisit the specialization of more operators.So, now on factory, in-place
+=and-=of long values are indeed not allocating a new object, at least not with “single digit long” values, it will follow for others. I am not sure if100000000falls into that category, but if it doesn’t, you would see a difference between the plus and minus example, and potentially only get a relatively small improvement. On some platforms only values up to+-2**15are covered, on others+-2**30are, I didn’t bother to check.For a single in-place benefiting from it, and one not, I close to observed 50% improvement, indicating that not doing the memory allocation is all the effort. I changed the test do do 5 ones where only the first one is not covered, I have yet to check the result of that though. But the number is going to be dependent on how much of the inplace allows reuse and will skew the results very much from that detail.
When considering the
CLONGpassing, I noticed it’s not yet done forINT_CLONGyet, now thatLONG_CLONGwould be something to work on, and then I noticed that code generation is not smart enough yet. I stopped there at the time, but I have had ideas that should make this work. ForOBJECT_CLONGthere will a need to useOBJECT_ILONGwhere the later is a structure with flags indicating if the Clongor thePyObject *are value, and the constant passed should be a prepared one, and then in passing that, it could dispatch toLONG_CLONGfromOBJECT_CLONGonce it run time checked theOBJECTto be that kind of object. In that case, we can use the object for the branches, where we don’t find a specialization of ours yet.But step one will be for binary operations to create a new engine for selecting the helper function to use, that will consider the type shape and the value shape of its arguments. Right now, it cannot take advantage of knowing that its argument is not just
longbut actually a constant value, that it could only do with variable references. Basically, had Nuitka support for C long C type for variables, this would work better than other things:But the current code generation engine could not do that:
So that’s a distinct problem that needs fixing. In this case, by picking helpers based on the value shape being limited, and e.g. knowing that 1 and 2 are good
CLONGvalues, we can attempt to do that, triggering an attempt to useLONG_CLONGand therefore using a C type to generate the second argument.For that of course, the clong C type in Nuitka needs an implementation already. And once it’s done, using it for variable storage will be an easy step. For starters, we could limit the new approach for constant values, but the other constructs should already be relatively target type aware from my previous work on boolean C type and void C type, so this might be easy.
I will introduce this with an experimental flag that guards the use, so this can be checked for non-breakage a while in paralell, and with making diffs of generated code, to prove it’s only better at least visually.
See, plus and minus are not slower anymore, which is mostly due to the avoiding of the CPython API it does now, and Windows specific.
I made more optimizations the other day, and I noticed that float devide got a special treatment already, so it reuses the object already, giving that big boost for that and multiply. I am going to turn my attention to the
LONGtype now, which at this time cannot take advantage of anything really, falling back to the CPython code always.I will try and specialize at least
+for long, but these arbitrary length things are difficult. That ought to give a boost already, but on Windows callingPyLong_FromLongetc. is actually going to be slow, such that for in-place things might be faster there, but for non-inplace, anything that computes manually and then creates a new object through such API is not going to be faster, so it might well be that there will be defines to not do it on Windows, but let code in the DLL do it.Which is a shame, because in-place for these things is not implemented in CPython, and of course could make all the difference, with a hard part being, that if a long result is a small integer, expectation is that these are converted to singleton objects, and do not exist in a second object ever.
So, the binary operations code is actually used for all in-place operations, which will then allow to avoid the CPython API, giving a faster
OBJECT_OBJECTin-place as well as mixed forms likeOBJECT_FLOATto be optimized. The repeat semantics for in-place is a bit different, but the tests revealed that.I have also made some cleanups on the binary and sequence concat/repeat code that avoids generating useless code, and adds assertions when things were previously assigned to
NULLand then tested for!= NULLgiving the C compiler the responsibility to throw away code. There is plenty more of this, I will add it with time.There are identical type optimizations for in-place already, but same or similar types has decicated code in operations, that is not taking effect here yet. That will be the next step, to replace the existing optimization for some forms of in-place, e.g.
LIST_LISTand adding the ones forFLOAT_FLOAT. After that, the in-place assignment will stop creating objects.Right now, the binary operation code does this:
where we know it’s a C float, to return a Python object. That enters the Python C API again, and therefore is slower on Windows, but for the time being (until we have a C type float code generation) is has to be that way. But for in-place we will get to check the reference count, and if we are luckly, and in a loop usage, we ought to be that, we can just overwrite the C float, and be extremely fast despite not having the special code C float type yet.
If it I am not mistaken, CPython cannot do that in general, there are only a few cases, e.g. strings, where it does it manually, this will then be very exciting progress.
Extra steps should then mean that
longbecomes a type considered “similar” to float, so thatsome_float += 1is fast, and then to supportCLONGandCFLOATto avoid going through a Python constant object for1and1.0used in operations. That will also give smaller programs, as passing C constants is easier than looking up a Python constant to the C compiler, not even considering chances for LTO compilation to take benefit of knowing one value for an operation.If you want to, please re-run your tests @Pro100rus32 as they ought to be improved by a lot. More is come, but it would be nice to see how much of an impact on Windows performance this already has.
So, I did the really tough thing, and started unifying the macro that currently is used for
intbinary and in-place operations. The later was only done by a workaround, which is semi-fine withintas there is no real in-place done with these in CPython, as small integers are singletons, and cannot be modified anyway, but have to be deduplicated when they are created.Without the workaround, the macro code is split up in two parts, one which produces outputs, and one which assigns it to the target. I have progressed some with this, and in fact, could experiment with actual non-deduplicate for ints, which we will want to have for
long(i.e. Python int) objects I think. Were that done with a macro as well, that would be really sweet.When that’s done, I think I will feel that implementing the long operations will be much more meaningful. And float should be easy at that point, as it’s only a lot simpler, no singletons for starters. It will be a while to complete that work still, but I hope to have something soonish.
I am making it a release goal to have this in there, with at least fast add/sub long operations for (relatively) small values.
@Pro100rus32 is this
clangcl.exeorclang.exe?--clangfaster then msvc or mingw.Mingw: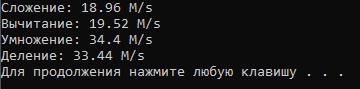
Clang: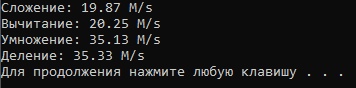
So I just pushed to factory improvements that cover the in-place float division as well with special code. Re-opening, since it seems I am working on it. 🥇
Ah my bad, your numbers to actually say that.
For division, I just noticed this one:
While floats do not yet get their own functions, these do avoid the slow paths of the DLL for these operations. I need to check, but probably the
ZeroDivisionErrorwas preventing us from doing similar. So should it not also have been slow for you? It’s going through the CPython DLL.I am closing the issue, but I guess, I will give it stab with implementing the Inplace add protocol at least. We should be able to reuse almost everything from the standard add operation anyway.
Ah, this is because Nuitka is using
PyNumber_AddPyNumber_InPlaceAdd which involves a round trip to the CPython DLL on Windows, which is incredibly slow. On all other platforms, this would be fast, esp. where LTO can be used. Windows is therefore affected by everything Nuitka doesn’t optimize in a way where it can be slower.For the similar operation that is not in-place, it wouldn’t have the issue, this one doesn’t go through a DLL entry point per operation. This is basically just incomplete work.
That makes this unfortunately the duplicate of other existing issues that state similar things.
To answer your question, previously I thought that the winlibs gcc should be fastest, but I think that MSVC with LTO should be even better. Notice, that the LTO doesn’t cover the DLL issue, but will help with the Nuitka own library calls made here.
That said, I will return to optimization and C types, but my priorty is to get first list appending loops to properly handle the append call optimized into list type shape and respective operations. For now, what it does with integers is faster outside of these technical issues of Windows, and I was OK with that. Esp. since the integer inplace operation ought to really not be done with objects at all in the future.
For multiply and devide, type inference ought to work, but the
floattype is not yet specialized, otherwise that would be even faster.