nerfstudio: Implementation of `urban_radiance_field_depth_loss` and `ds_nerf_depth_loss` are wrong?
Describe the bug
At least in the way that I am using these loss terms, I am pretty sure there is a fundamental error in the way they are implemented.
In both of these depth loss functions, the general setup/aim is:
- We have a ground truth depth value for each ray (from the provided depth map)
- We look at the samples along each ray, and increase the weight values at samples whose depth is close to the ground truth depth
- (In
urban_radiance_field_depth_losscase, we additionally reduce weight values at samples with depth < ground truth depth)
The problem for me with the current implementation is that I think we compare samples on ALL rays to ground truth depth values on ALL rays. This seems wrong: shouldn’t we be comparing a ray’s ground truth depth only to the samples on that ray?
To Reproduce
Here is a toy example illustrating the problem, with just one part of the urban_radiance_field_depth_loss function.
import torch
sigma = 0.01
# imagine we have 3 samples for ray 1, then 4 samples for ray 2
steps = [0.9, 1.0, 1.1, 0.8, 0.9, 1.0, 1.1]
# our ground truth depth for our two rays
termination_depth = [1.0, 1.1]
# assume weights are all just 10.0
weights = [10.0] * len(steps)
# Get the shapes consistent with what happens in the code
steps, termination_depth, weights = [torch.FloatTensor(_).unsqueeze(-1) for _ in [steps, termination_depth, weights]]
termination_depth = termination_depth.unsqueeze(-1)
line_of_sight_loss_empty_mask = steps < termination_depth - sigma
print(f"line_of_sight_loss_empty_mask.shape = {line_of_sight_loss_empty_mask.shape}")
line_of_sight_loss_empty = (line_of_sight_loss_empty_mask * weights**2)
print(f"line_of_sight_loss_empty = {line_of_sight_loss_empty[:,:,0]}")
Output:
line_of_sight_loss_empty_mask.shape = torch.Size([2, 7, 1])
line_of_sight_loss_empty = tensor([[100., 0., 0., 100., 100., 0., 0.],
[100., 100., 0., 100., 100., 100., 0.]])
When I run my code and pdb.set_trace() in the urban_radiance_field_depth_loss function, I can see that steps has shape [num_samples, 1], termination_depth has shape [num_rays, 1, 1], and weights has shape [num_samples, 1].
Thus in the above toy example, I set up the steps, termination_depth and weights variables all to values that would be typical during training.
In this part of the loss function, the goal is to find samples with values less than the ground truth depth (minus sigma). So we have steps < termination_depth - sigma. Due to broadcasting, the shape of this ends up being [2, 7, 1], or in general [num_rays, num_samples, 1]. This means we are doing the comparison for all rays, against all samples, which doesn’t make any sense. We should be comparing the depth value for each ray against only the samples for that ray.
This leads to an incorrect loss being computed. The loss (before averaging) we saw printed above was:
line_of_sight_loss_empty = tensor([[100., 0., 0., 100., 100., 0., 0.],
[100., 100., 0., 100., 100., 100., 0.]])
But our sampling points were:
steps = [0.9, 1.0, 1.1, 0.8, 0.9, 1.0, 1.1]
That is:
ray_0_steps = [0.9, 1.0, 1.1]
ray_1_steps = [0.8, 0.9, 1.0, 1.1]
And our ground truth depth for the two rays were 1.0 and 1.1:
In a correct implementation, the loss should (or could) be:
line_of_sight_loss_empty = tensor([[100., 0., 0., nan, nan, nan, nan],
[ nan, nan, nan, 100., 100., 100., 0.]])
This way, we are pushing down the weights on the correct samples (those that are < gt_depth - sigma for each ray).
I put the nan’s here to illustrate the fact that we should not be comparing samples from ray 0 to the depth from ray 1, and vice-versa. In reality these would be 0’s.
Note: while the toy example above is just for the line_of_sight_loss_empty component of urban_radiance_field_depth_loss, the same concept/issue applies to the line_of_sight_loss_near component, AND to ds_nerf_depth_loss.
Am I missing something
This seems like a pretty big oversight. Is it possible that the problem is that I am using packed samples and that’s not supported properly here?
Solution
If we pass in ray_indices, then we can use some indexing to compare the correct depth values with each sample value and corresponding weight value. I implemented this and in my case it led to a 3x speedup (plus it probably uses a lot less memory). Interestingly despite these issues the original URF loss still seems to achieve its aims for me (perhaps because all the incorrect loss terms just create noise and cancel each other out), but my ‘fixed’ version also seems to work just as well or better (plus it’s faster). Happy to submit a PR with this version, just thought I would explain the issue first to check I haven’t made some mistakes of my own here.
About this issue
- Original URL
- State: closed
- Created a year ago
- Comments: 24 (15 by maintainers)
@Ilyabasharov And notice this problem like I just mentioned, you would better visualize the weight and the ideal distribution you used before add the depth supervision~
Agree, if you have different number of samples per ray, it is needed to rewrite depth losses. Basically, for the second question answer is yes, the idea of URF and DS NeRF papers is to focus weights of a ray to dirac function. It means that before and after termination depth weights should be zeros. See DS-NeRF (fig. 3) paper visualisation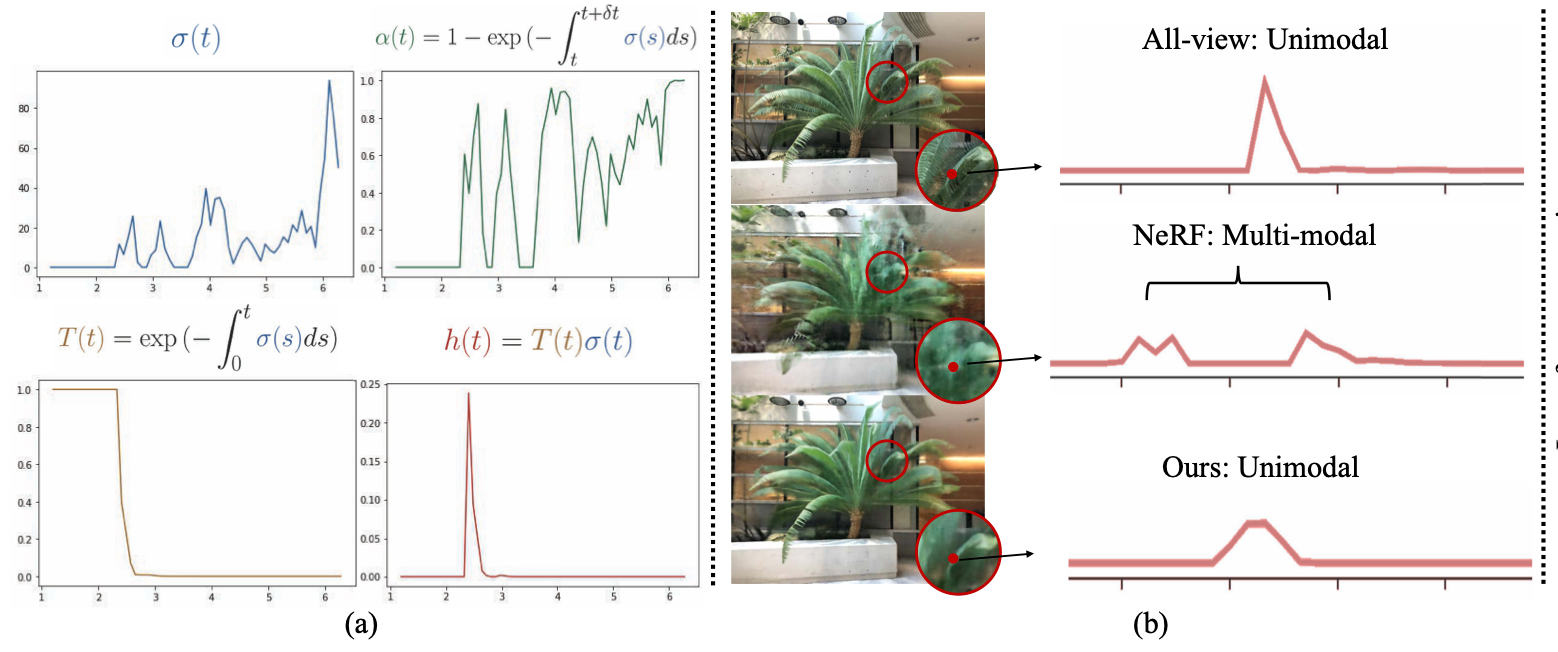
Thank you very much!
If you have a sparse point cloud, then use the distance between the farthest point and the center point cloud as scale_factor, if only pose, then use the distance between the farthest pose and the center pose, and then set the scale of the peripheral scene bbox to 15, finally try down the effect is not bad
I myself try down in fact urbanRF’s depth supervision can achieve a very good effect. But it seems that no one is using the right. Here is a comparison of my before and after results using UrbanRF depth supervision
 You can see that only RGB supervision learns the wrong geometry for details such as the road surface, but adding depth supervision generates the correct geometry
You can see that only RGB supervision learns the wrong geometry for details such as the road surface, but adding depth supervision generates the correct geometry


So you can see that urbanRF’s depth supervision is really effective
If the shapes you pass into the function do not match the shapes in the type spec, the code won’t work as intended. For weights you need a ‘num_samples’ dimension since that’s what we compare the depth with for each ray.
That being said, the way the code is currently written is also not correct with respect to the type spec. We should ideally write
termination_depth[..., None, :]when we add the ‘num_samples’ dim. However, it will work as long as there is only one batch dim. This will not fix your problem but it’s probably worth refactoring the code a bit.Looping in @mpmisko as he implemented these functions.