napari: Blocked UI while loading images in notebook
🐛 Bug
In Juan’s “Intro to Neural Nets” napari notebook scrolling through the 10,000 tests cases is slow because some of the layers are computed on the fly. Unlike #845 (multi-scale) or #1300 (large images) in this case the images are all very small and there is minimal IO.
Instead here the slowness is a machine learning (torch) computation. Accessing the image data via asarray triggers a computation that takes some time to produce the data. While waiting for the computation to finish the UI is blocked.
To Reproduce
- Get the “napari” branch of https://github.com/jni/noise2self
- Run
jupyter notebookthen run “Intro To Neural Nets” in the notebooks directory. - In cell 15 napari is launched showing a time series of 10,000 small images, 3 layers each.
- Use the slider to scroll through the time series.
Each image takes maybe 500ms to load on a new macbook. This makes the slider extremely awkward to use, and the overall experience is poor.
Expected behavior
- The UI should not be blocked. You should be able to move the slider freely at all times.
- The
clean_test_dasklayer is not computed on the fly. It should be display as soon as possible, before the other layers are ready.
With both 1 and 2 working the end result would be almost more like a custom application than just an image viewer. You can quickly scroll through the input images to find one you like, then you pause and wait for the result to be computed and displayed.
Specifically the clean_test_dask layer could be shown quickly:
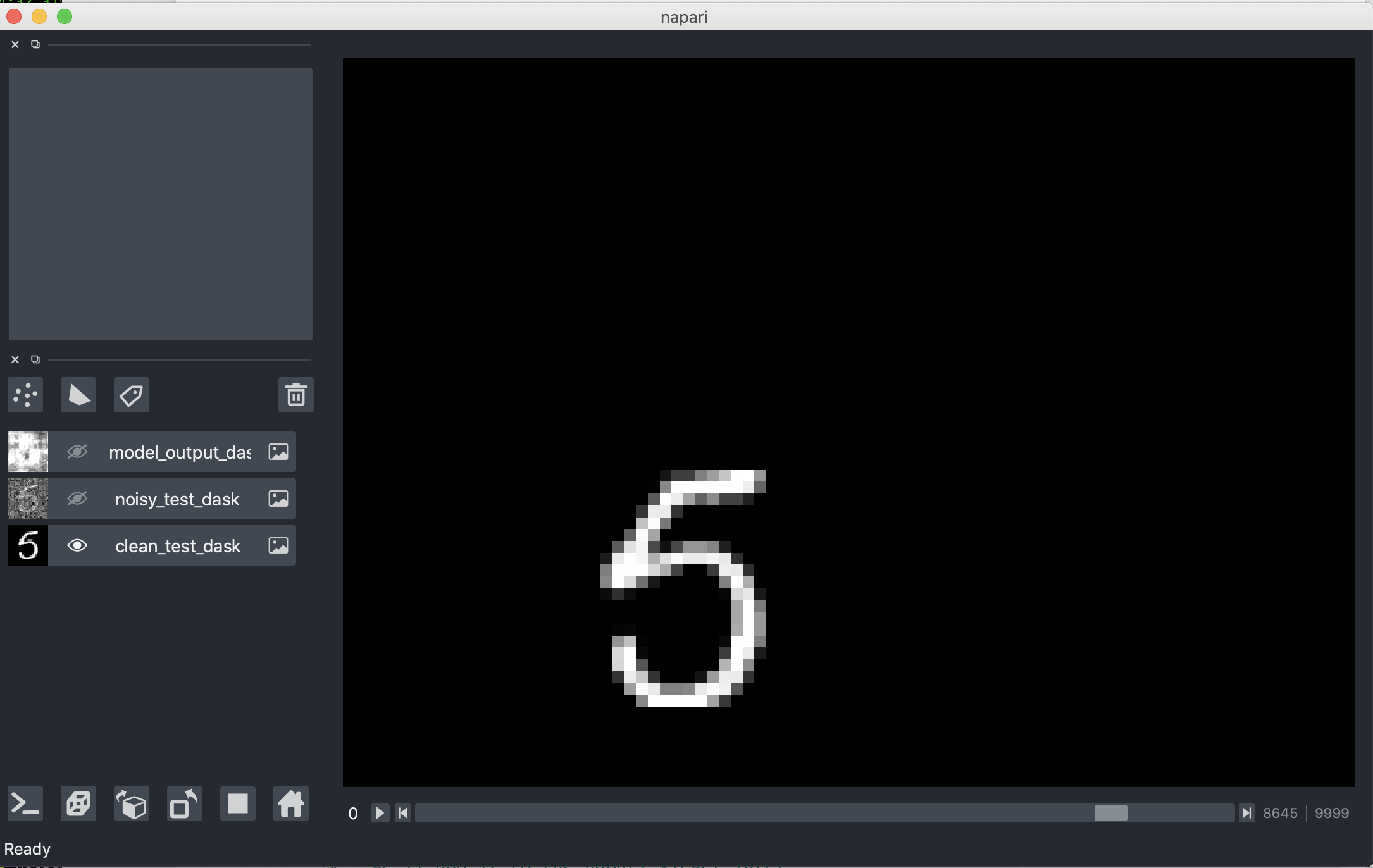
Then the other 2 layers added when available:
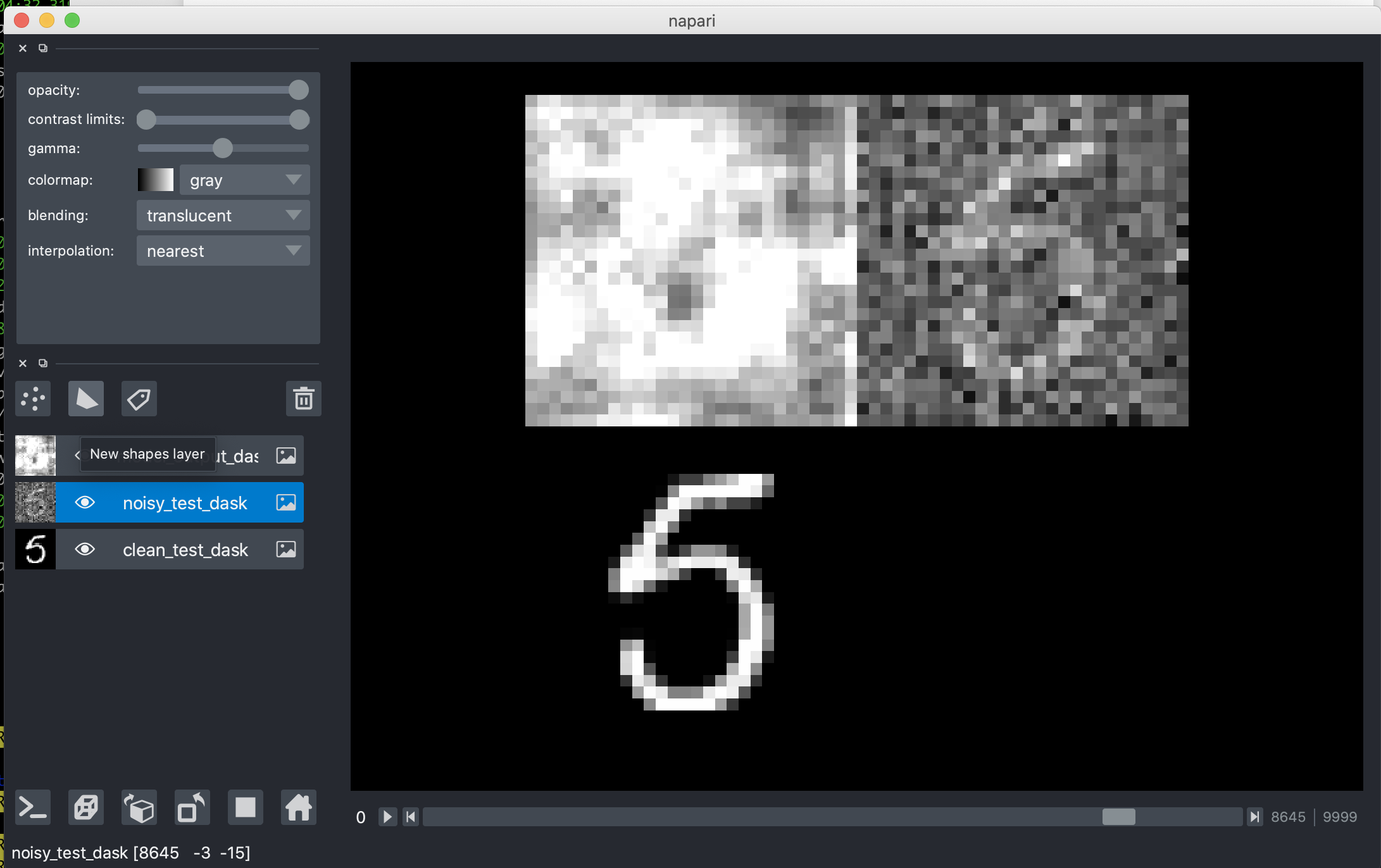
Additional context
We are writing a document that will propose a solution for the three blocked UI issues: this one, #845 and #1300.
About this issue
- Original URL
- State: closed
- Created 4 years ago
- Reactions: 1
- Comments: 37 (37 by maintainers)
Above @jni notes that this is not faster when you turn async on:
The reason is napari thinks the image is multi-scale, and multi-scale is not async yet. I added a log message, when this
Imageis created it logs:It’d be nice if there were a clearer indication in the UI whether a layer was single-scale or multi-scale. Either in the layer widget or with some type of “layer properties” or “layer status” dialog box that lists the layers and has columns of information about them. For example dimensions, type (rgb, rgba), loading speed, etc. Kind of like Mac’s Activity Monitor but showing the layers instead of processes.
Progress with #1354, not pushed yet. We figured out that we need to convert input arrays with
np.arraybecause using dask from them is slow due to: https://github.com/dask/dask/issues/5913See below for a newer/better GIF, I removed this one it’s dated.
I fixed the “multi-scale renders as black” problem in #1495. Multi-scale images were never being marked as “loaded”. When an image is not “loaded” the vispy node is invisible.
Long term it might be nice to leave up the previous image until the new one is ready to draw, to avoid going to black. Figuring the “wrong” image at least is a point of reference. For example with the “hand tracking” one above, seeing the hand skeleton on top of the “wrong” image seems like it’d look better than black.
But you do need some visual indication it’s the wrong/stale image, and some indication when it’s updated to the correct image, when the layers are synced up again. Also it might not be totally simple to implement since you need to keep the old/wrong image around where today we get rid of it as soon as we start loading the new image.
We might have to try a few things until we get something that looks/feels right. We can try to do something now or keep it as black until we are further along.
I think the above error alludes the big difference between threads and processes. All the memory in the process is available to all the threads. So when you pass data “to” worker thread or “from” a worker thread, nothing is passed except references. All the data stays put, zero copies, and is available to everyone.
With processes by default it serializes the data and transfers it somehow between them. By default that means pickle. Early on I hit a problem that it couldn’t pickle my weakref Layer objects. Couldn’t pickle Layer objects themselves either I’m sure. Because the Layer doesn’t exist in the other process. That was easy to fix I added
ChunkLoader.layer_mapand in theChunkRequestI only storeid(layer)which you can throw around between processes just fine.The Dask docs suggest pickling large numpy arrays does not work well, which could be an issue! The Dask docs say a lot about serialization and pickingly and they have their own protocols and things.
I’m wondering if shared memory has a role. Dask discusses it but it’s not clear which problems it solves and which remain. You maybe still need serialization because the share memory needs to be purely “data” it can’t have references to anything because it would not exist in both processes? There is a learning curve here. https://docs.dask.org/en/latest/shared.html
At any rate we are just scratching the surface with worker processes and we either figure out how to make them work well or we don’t.
I spoke to @tlambert03 about this. This is a great prototype and the fuctionality is pretty close to what we want. Definitely proves out the concept I think some changes for the real version are:
Create a global
ChunkPagerobject with a thread pool, instead of havingWorkerBasejust create an “anonymous” pool under the hood on they fly. We’ll want to submit requests to theChunkPagerfrom various places, query it, configure it, and generally have a “thing” that is our pager. We might have multiple pagers, like for different layer types, so maybe create aChunkManagerwith one or more pagers?Add some type of
DataSourceobject thatImageholds. The data source may or may not have the data in memory. If it does it has what’s inImage._data_rawbasically.Instead of calling
_set_dataafter the chunk is loaded, we’ll just set the data in theDataSourceand then trigger a refresh. Here he moved some stuff into_set_datathat we obviously can’t move in there.We talked about how
_set_view_sliceis more or less just adraw()orrender()method at least forImage. We call it to draw the layer even if the slice was not changed at all.We have to figure out how many layers do we load at once (size of the global thread pool) and how do we figure out the right order. We want to load the fastest layers first. Lot’s of TBD there.
Other than that it’s a pretty good prototype of what we want.