onnxruntime: ONNXRuntime CPU - Memory spiking continuously (Memory leak)
Hi,
Describe the issue I am using ONNX Runtime python api for inferencing, during which the memory is spiking continuosly.
(Model information - Converted pytorch based transformers model to ONNX and quantized it)
Urgency Critical
System information
- ONNX Runtime version: 1.8.1
- Python version: 3.6
- Running on a CPU backend
Inference code being used
For creating onnxruntime session:
from onnxruntime import InferenceSession, GraphOptimizationLevel, SessionOptions
options = SessionOptions()
options.intra_op_num_threads = 1
options.graph_optimization_level = GraphOptimizationLevel.ORT_ENABLE_ALL
session = InferenceSession(model_path, options, providers=["CPUExecutionProvider"])
session.disable_fallback()
for sentence in sentence_list: # sentence_list = list of sentences
ort_inputs = tokenizer(sentence, truncation=True, return_tensors="pt")
ort_inputs = {
'input_ids': ort_inputs.data['input_ids'].numpy(),
'attention_mask': ort_inputs.data['attention_mask'].numpy()
}
ort_outputs_quant = session.run(None, ort_inputs)[0] # onnx_model = instance of loaded onnxmodel
pred_logits.extend(ort_outputs_quant)
del ort_outputs_quant
del ort_inputs
y_pred = np.argmax(pred_logits, axis=1)
- Also tried with latest onnxruntime == 1.9.0 with python 3.7. The issue still persists.
Below is the code used to export DistilRobertaBase Pytorch model to ONNX and quantize it.
# Get the example data to run the model and export it to ONNX
enable_overwrite = True
inputs = {
'input_ids': input_ids[0].to(device).reshape(1, max_seq_length),
'attention_mask': attention_masks[0].to(device).reshape(1, max_seq_length)
}
model.eval()
model.to(device)
# Converting PyTorch model to ONNX format
if enable_overwrite or not os.path.exists(export_model_path):
with torch.no_grad():
symbolic_names = {0: 'batch_size', 1: 'max_seq_len'}
torch.onnx.export(model, # model being run
args=tuple(inputs.values()), # model input (or a tuple for multiple inputs)
f=export_model_path, # where to save the model (can be a file or file-like object)
opset_version=11,
do_constant_folding=True, # whether to execute constant folding for optimization
input_names=['input_ids', # the model's input names
'attention_mask'],
output_names=['output_0'], # the model's output names
dynamic_axes={'input_ids': symbolic_names, # variable length axes
'attention_mask' : symbolic_names,
'output_0' : {0: 'batch_size'}})
In above code, example value for variable inputs is:
{
'input_ids': tensor([[ 0, 44879, 4576, 35, 1437, 1437, 508, 2940, 2890, 1225,
5046, 2481, 2, 1, 1, 1, 1, 1, 1, 1]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0]])
}
Erroneous behavior
Memory keeps spiking during run.
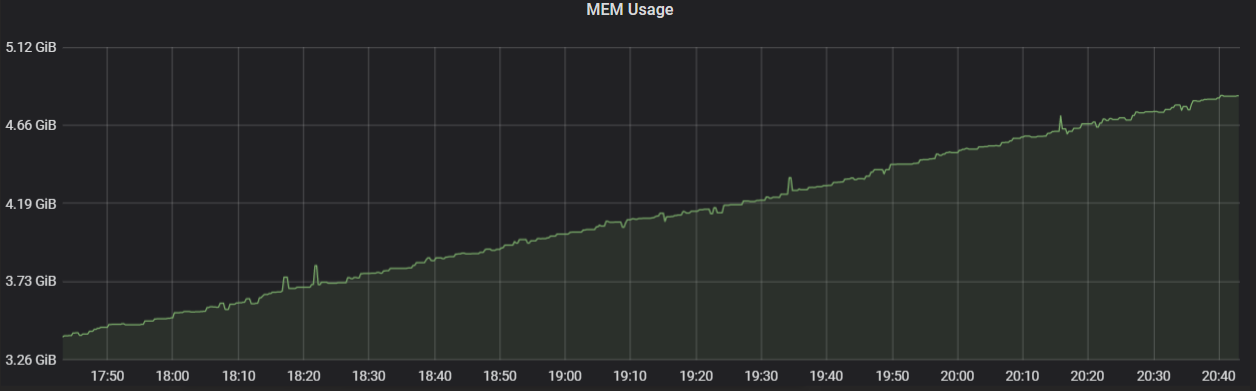
Expected behavior Expecting stable memory consumption throughout the run (no memory leaks or accumulation).
About this issue
- Original URL
- State: open
- Created 3 years ago
- Reactions: 1
- Comments: 22 (3 by maintainers)
meet this issue, too.
onnxruntime-gpu==1.11.0 with cuda 11.2 Found it occurred randomly, sometimes memory spiked fast, sometime slowly
@yaminipreethi, did you manage to solve this memory leak issue? I have tried:
with either cuda 11.1.0 or cuda 11.4.3 Nothing seems to Help. The Memory is increasing steadily without any hope of stopping and clearly is caused by the session.run() function
@yaminipreethi did you solve this problem?i alse meet this,it is very strange
I also tried using python version 3.7 with onnxruntime 1.8.1. But, this does not solve the issue. Can anyone please suggest what else can be tried out to resolve memory leak?