DeepSpeed: [BUG]: NVCC build error
Describe the bug A clear and concise description of what the bug is.
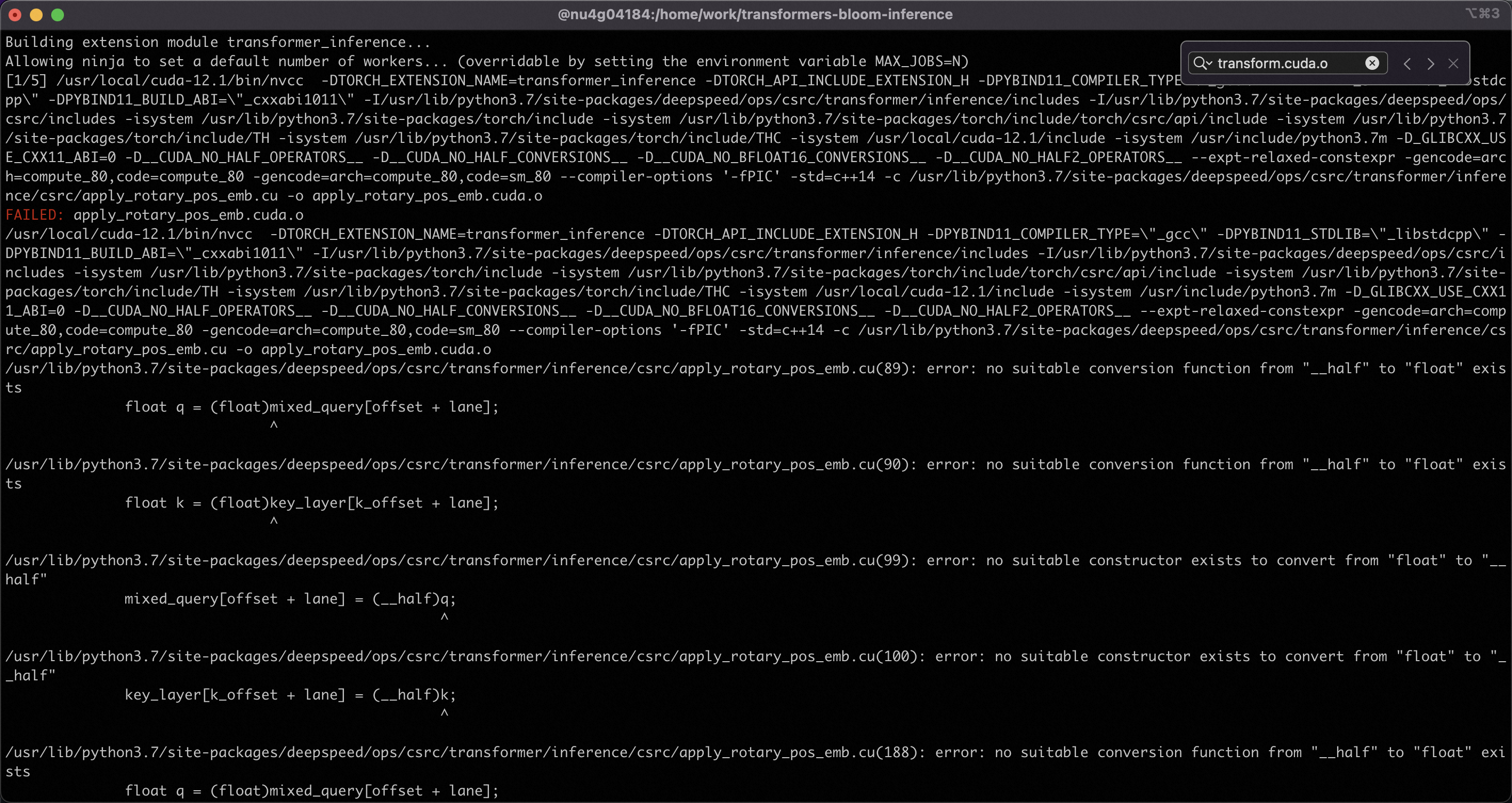
When build transformer inference: /usr/local/cuda-12.1/bin/nvcc -DTORCH_EXTENSION_NAME=transformer_inference -DTORCH_API_INCLUDE_EXTENSION_H -DPYBIND11_COMPILER_TYPE="gcc" -DPYBIND11_STDLIB="libstdcpp" -DPYBIND11_BUILD_ABI="cxxabi1011" -I/usr/lib/python3.7/site-packages/deepspeed/ops/csrc/transformer/inference/includes -I/usr/lib/python3.7/site-packages/deepspeed/ops/csrc/includes -isystem /usr/lib/python3.7/site-packages/torch/include -isystem /usr/lib/python3.7/site-packages/torch/include/torch/csrc/api/include -isystem /usr/lib/python3.7/site-packages/torch/include/TH -isystem /usr/lib/python3.7/site-packages/torch/include/THC -isystem /usr/local/cuda-12.1/include -isystem /usr/include/python3.7m -D_GLIBCXX_USE_CXX11_ABI=0 -D__CUDA_NO_HALF_OPERATORS -D__CUDA_NO_HALF_CONVERSIONS_ -D__CUDA_NO_BFLOAT16_CONVERSIONS__ -D__CUDA_NO_HALF2_OPERATORS__ --expt-relaxed-constexpr -gencode=arch=compute_80,code=compute_80 -gencode=arch=compute_80,code=sm_80 --compiler-options ‘-fPIC’ -std=c++14 -c /usr/lib/python3.7/site-packages/deepspeed/ops/csrc/transformer/inference/csrc/apply_rotary_pos_emb.cu -o apply_rotary_pos_emb.cuda.o /usr/lib/python3.7/site-packages/deepspeed/ops/csrc/transformer/inference/csrc/apply_rotary_pos_emb.cu(89): error: no suitable conversion function from “__half” to “float” exists float q = (float)mixed_query[offset + lane];
To Reproduce Steps to reproduce the behavior:
- Simple inference script to reproduce
- What packages are required and their versions
- How to run the script
- …
Expected behavior A clear and concise description of what you expected to happen.
ds_report output
Please run ds_report to give us details about your setup.
DeepSpeed C++/CUDA extension op report
NOTE: Ops not installed will be just-in-time (JIT) compiled at runtime if needed. Op compatibility means that your system meet the required dependencies to JIT install the op.
JIT compiled ops requires ninja ninja … [OKAY]
op name … installed … compatible
[WARNING] async_io requires the dev libaio .so object and headers but these were not found. [WARNING] async_io: please install the libaio-devel package with yum [WARNING] If libaio is already installed (perhaps from source), try setting the CFLAGS and LDFLAGS environment variables to where it can be found. async_io … [NO] … [NO] cpu_adagrad … [NO] … [OKAY] cpu_adam … [YES] … [OKAY] fused_adam … [NO] … [OKAY] fused_lamb … [NO] … [OKAY] quantizer … [NO] … [OKAY] random_ltd … [NO] … [OKAY] [WARNING] please install triton==1.0.0 if you want to use sparse attention sparse_attn … [NO] … [NO] spatial_inference … [NO] … [OKAY] transformer … [NO] … [OKAY] stochastic_transformer . [NO] … [OKAY] transformer_inference … [NO] … [OKAY] utils … [YES] … [OKAY]
DeepSpeed general environment info: torch install path … [‘/usr/lib/python3.7/site-packages/torch’] torch version … 1.13.1+cu117 deepspeed install path … [‘/usr/lib/python3.7/site-packages/deepspeed’] deepspeed info … 0.9.2+297cd9ed, 297cd9ed, master torch cuda version … 11.7 torch hip version … None nvcc version … 12.1 deepspeed wheel compiled w. … torch 1.13, cuda 11.7
Screenshots
If applicable, add screenshots to help explain your problem.
System info (please complete the following information):
- OS: [e.g. Ubuntu 18.04]
- GPU count and types [e.g. two machines with x8 A100s each]
- (if applicable) what DeepSpeed-MII version are you using
- (if applicable) Hugging Face Transformers/Accelerate/etc. versions
- Python version
- Any other relevant info about your setup
Docker context Are you using a specific docker image that you can share?
Additional context Add any other context about the problem here.
About this issue
- Original URL
- State: closed
- Created a year ago
- Comments: 15 (3 by maintainers)
The running model is microsoft/bloom-deepspeed-inference-fp16.@mrwyattii The problem maybe cuda version, my CUDA version is 12.1, while torch version 1.13.1+cu117。Change my cuda verison to 11.7,same as torch,problem solved.
The error happens when -D__CUDA_NO_HALF_OPERATORS -D__CUDA_NO_HALF_CONVERSIONS_ -D__CUDA_NO_BFLOAT16_CONVERSIONS__ -D__CUDA_NO_HALF2_OPERATORS__ are using when compile,which determined in ./usr/lib/python3.7/site-packages/torch/utils/cpp_extension.py