longhorn: [QUESTION] Volumes stuck in attaching state
Question In our 3 node cluster, multiple volumes fail to attach. Rebooting nodes sometimes helps to resolve the issue for some volumes, but causes others to fail.
Longhorn worked just fine for 5-6 months with exactly the same cluster configuration. We did however experience latency issues with our config store (galera-cluster) in the past that caused k3s components to crash. These problems are resolved, but may have caused our issues with longhorn.
We see the following events in the namespace longhorn-system:
LAST SEEN TYPE REASON OBJECT MESSAGE
4m23s Warning Unhealthy pod/share-manager-pvc-8c08f699-a65a-41c3-a1ce-4f43327c294a Readiness probe failed: cat: /var/run/ganesha.pid: No such file or directory
4m21s Warning Unhealthy pod/share-manager-pvc-0097611e-0a90-412e-bfa3-3d53e52723dd Readiness probe failed: cat: /var/run/ganesha.pid: No such file or directory
3m11s Warning Unhealthy pod/share-manager-pvc-b424093a-da21-4856-bd2d-c98003512418 Readiness probe failed: cat: /var/run/ganesha.pid: No such file or directory
Allmost all replicas are stuck in state “stopped” for node “server914zx.mueller.de”:
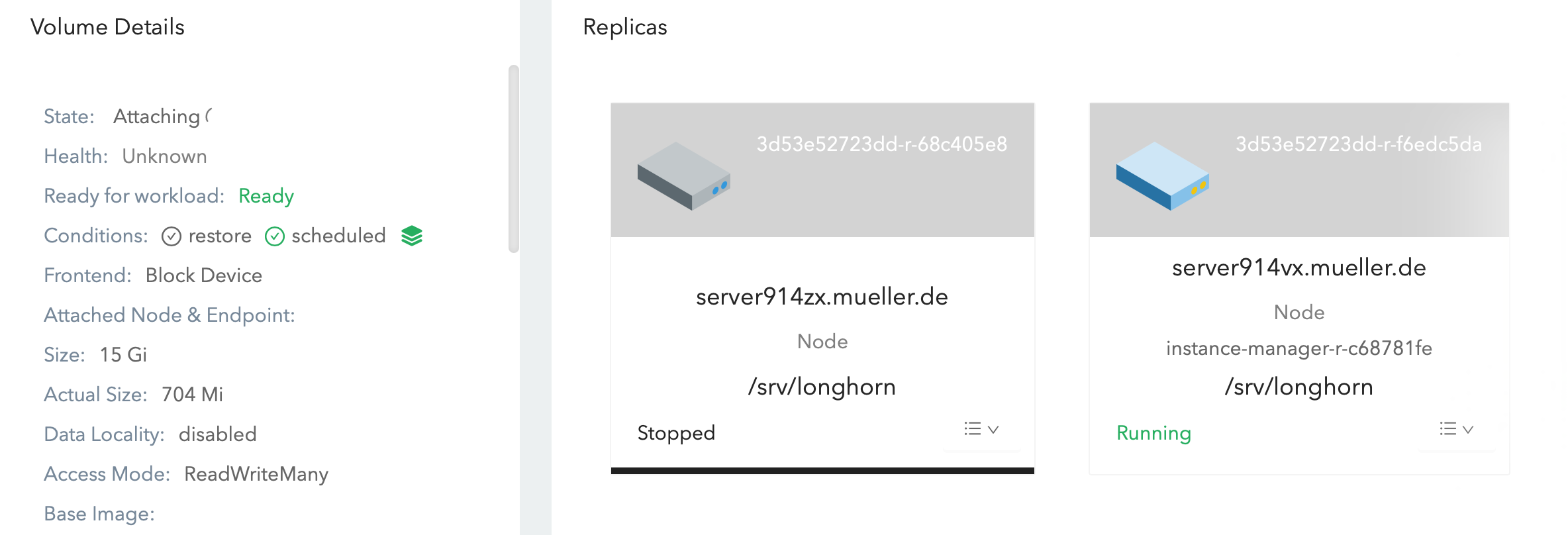
What should we do to resolve these issues?
Environment:
- Longhorn version: 1.1.0
- Kubernetes version: v1.19.7+k3s1
- Node config
- OS type and version: Ubuntu 20.04.2 LTS (GNU/Linux 5.4.0-65-generic x86_64)
- CPU per node: 32
- Memory per node: 252 GB
- Disk type: LVM, XFS, local disks
- Network bandwidth and latency between the nodes: 2x 1GBit LACP, 0.07ms ping average
- Underlying Infrastructure: Baremetal
Additional context longhorn-support-bundle_2044762c-c02e-416d-83eb-ae942f0224ab_2021-09-21T09-31-42Z.zip
About this issue
- Original URL
- State: open
- Created 3 years ago
- Reactions: 1
- Comments: 23 (6 by maintainers)
@haskell42 seems to be the same as https://github.com/longhorn/longhorn/issues/3000
Can you try to delete this instance manager:
kubectl delete instancemanager instance-manager-r-7b5c128d -n longhorn-systemhttps://github.com/longhorn/longhorn/issues/3000#issuecomment-918614544 Looks like the instance managers are ok. Did you try to scale down the workloads after the deletion?
We still experience problems attaching the following volumes:
All replicas are running, but after about 5 minutes the pods get destroyed (and attaching is aborted) because of the missing volumes.
Yesterday this worked just fine.
longhorn-support-bundle_2044762c-c02e-416d-83eb-ae942f0224ab_2021-09-22T08-16-00Z.zip
Thanks @timmy59100 for the great help! yeah, we hit the same multiple instance manager with the same spec.
This time, it happens with Longhorn
v1.1.0so this issue is not introduced by the new versionv1.2.0. We are still investigating what is the root case in the thread of longhorn/longhorn#3000