longhorn: [BUG] Volume attachment take long time, which may be caused by the replica controller queue being flooded by the backing image events
Question there is no problem when there are few resources but very slow for attach detach on more backup and restore pod 40+, some pod includes multi volume, exp: 10+ every pod has one volume base on backing storage class, backing file like os image, size 800M+ or 6G+ volume 250+ backup 40+ restore 40+ Environment:
- Longhorn version: 1.2.2(upgrade from 1.1.2)
- Kubernetes version: 1.18+
- Node config * 4
- OS type and version centos7.6
- CPU per node: 32
- Memory per node: 128G
- Disk type longhorn default disk: hdd 512G
- Underlying Infrastructure (e.g. on AWS/GCE, EKS/GKE, VMWare/KVM, Baremetal): Baremetal
Additional context Tried if modify queue.AddRateLimited --> queue.Add on replicas、engine and volume controller’s enqueue func(longhorn-manager) example: https://github.com/longhorn/longhorn-manager/blob/b661af0c6315d0f910a3400b650b0e9fba2df577/controller/replica_controller.go#L377 the performance will be normal, look like good why use queue.AddRateLimited? Isn’t it just on because of failure?
delay
add log to record limit delay(just for longhorn-replica controller) and use go vendor mod build, find resource delay is very long time
log position: https://github.com/kubernetes/client-go/blob/e627be7959e730f91a38c18674c29b0256c4bb2e/util/workqueue/delaying_queue.go#L243

metrics
About this issue
- Original URL
- State: closed
- Created 3 years ago
- Comments: 22 (11 by maintainers)
I just tested the patch by:
shuowu/longhorn-manager:bi-scalability, which is based on themasterversion as well as including the patch & some logs.After all volumes become running, attaching a newly created volume with a backing image set takes around 12 seconds.
As for the 1-hour enqueuing count, in the env mentioned above, the backing-image-related enqueuing count is around one-tenth of the total count:
[Updated] When I switch the longhorn manager image to
masterfor this env, creating or deleting a volume will get stuck. This means the patch does fix the issue.I just checked the backing image enqueuing logic in the replica controller. It does enqueue too many irrelevant replicas for each backing image. Here is the patch. If possible, can you take a quick try and see if it works? Or I can create a PR then request QAs to help test it.
@shuo-wu hdd emmmm…
replica count = volume count * 3, count is ok but the result is now, not then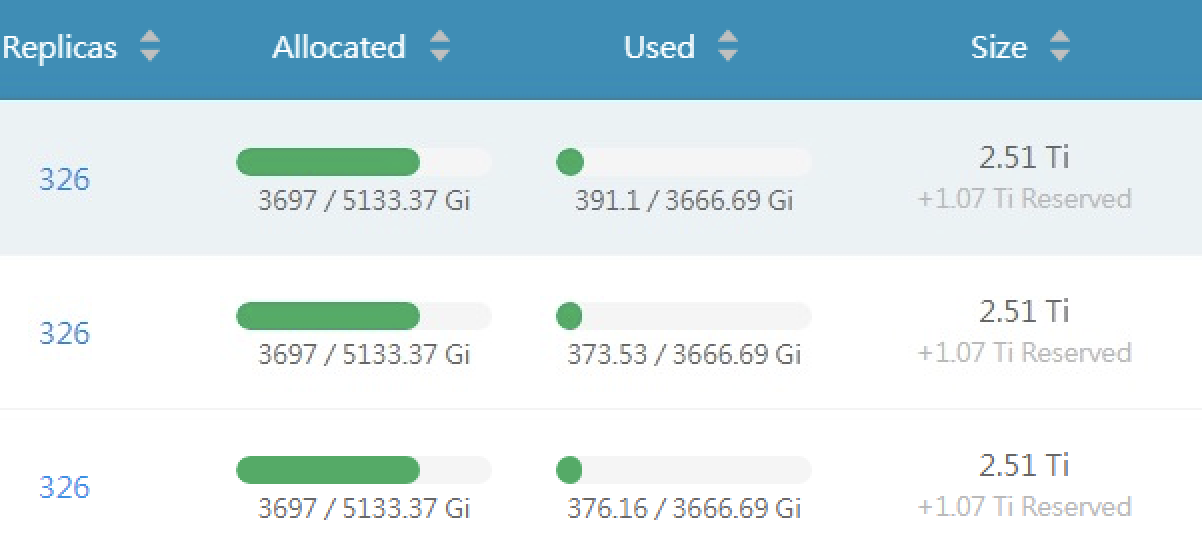

each node 3.6T hdd