longhorn: [BUG] PVC Failed due to instance manager is down
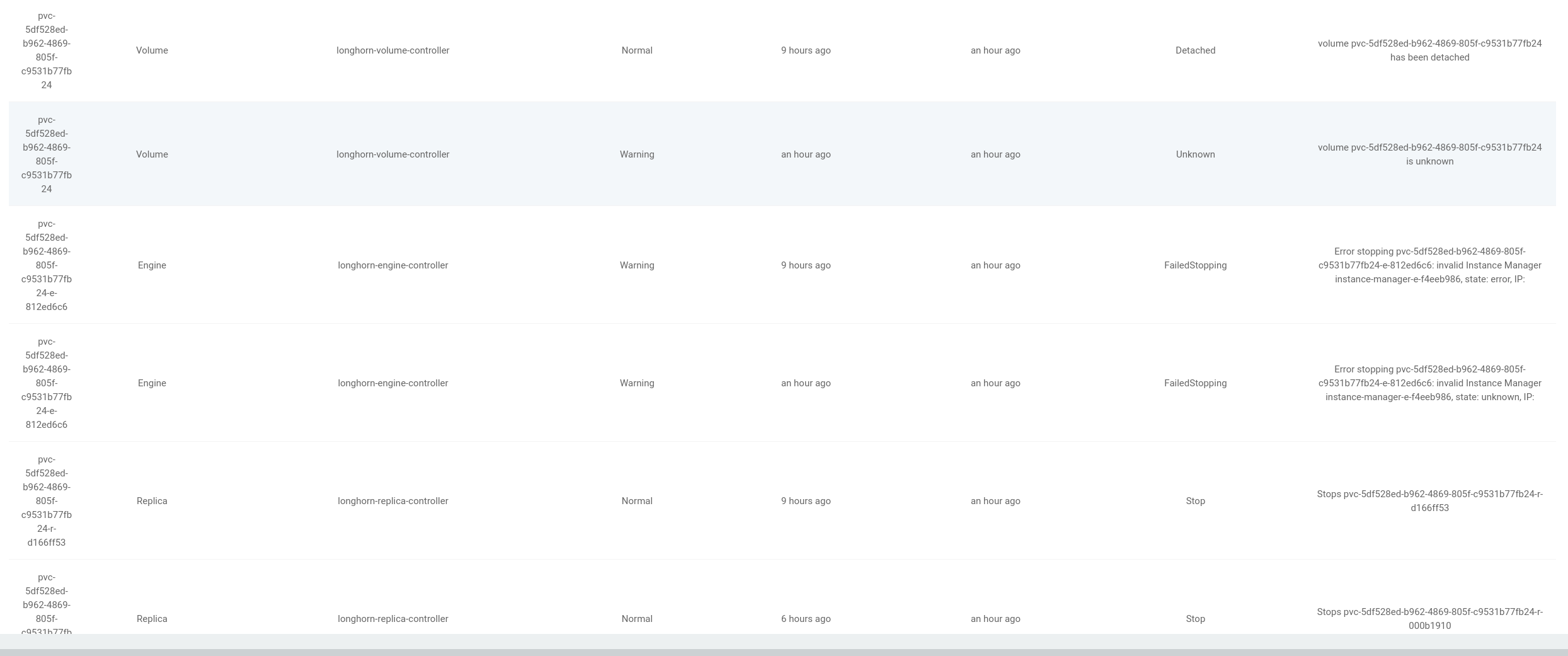
We have a large PVC which have about 50TB totally with XFS in host instance file system, and we attached it successfully as a minio backend. when we start more job on cloud, the instance manager is down. and the PVC start the stop action. but the stop action failed due to the instance manager pod is failed due to no resource in the cluster. Then our PVC can’t restart anymore.
the problem is:
- how can we avoid the problem like this?
- if that happened, how can we recover the storage volume?
Version: v1.1.0
About this issue
- Original URL
- State: open
- Created 3 years ago
- Comments: 19 (8 by maintainers)
hope this problem can be solved, longhorn is much easy to deploy and maintain than Rook
I think you are talking about Longhorn volumes rather than PVCs. Longhorn volumes are controlled by instance manager pods. In other words, if an instance manager pod is down, the related volumes will become
DegradedorFaulted. To avoid instance manager pods being evicted by resource exhaust, you can check & config the settingGuaranteed Engine CPUfirst.