framework: Job keeps retrying (and failing) every minute when scheduled for every 15 minutes
- Laravel Version: 6.1.0
- PHP Version: 7.3.9
- Database Driver & Version: MariaDB 10.4.8
Description:
One of the Jobs defined in Kernel.php keeps retrying every minute even when the first run was successful and the Job was scheduled to run every 15 mins in Kernel.php
$schedule->job(new GeneratePopularDownloadStats())->everyFifteenMinutes()->runInBackground();
Steps To Reproduce:
See this thread: https://old.reddit.com/r/laravel/comments/dhax10/scheduled_job_keeps_failing_and_retrying_but_when/
This all happens on my Homestead VM, all latest version.
Job:
<?php
namespace App\Jobs;
use Illuminate\Bus\Queueable;
use Illuminate\Contracts\Queue\ShouldQueue;
use Illuminate\Foundation\Bus\Dispatchable;
use Illuminate\Queue\InteractsWithQueue;
use Illuminate\Queue\SerializesModels;
use App\Models\PopularReleases;
use Illuminate\Support\Facades\DB;
class GeneratePopularDownloadStats implements ShouldQueue
{
use Dispatchable, InteractsWithQueue, Queueable, SerializesModels;
public $tries = 3;
/**
* Create a new job instance.
*
* @return void
*/
public function __construct()
{
//
}
/**
* Execute the job.
*
* @return void
*/
public function handle()
{
$tvStats = DB::table('download_stats as dl')->select('r.id', 'r.searchname', 'r.guid', 'r.categories_id', 'c.title', 'rc.title as root_category', 'r.grabs', 'dl.count')->join('releases as r', 'dl.release_id', '=', 'r.id')->join('categories as c', 'r.categories_id', '=', 'c.id')->join('root_categories as rc', 'c.root_categories_id', '=', 'rc.id')->whereBetween('r.categories_id', [5000, 5999])->limit(100)->get();
foreach ($tvStats as $tv) {
$popular = PopularReleases::updateOrCreate(['release_id' => $tv->id]);
$popular->release_id = $tv->id;
$popular->searchname = $tv->searchname;
$popular->guid = $tv->guid;
$popular->category = $tv->root_category . ' > ' . $tv->title;
$popular->type = 2;
$popular->grabs = $tv->grabs;
$popular->count = $tv->count;
$popular->save();
}
}
}
The error I keep getting when it fails is:
App\Jobs\GeneratePopularDownloadStats has been attempted too many times or run too long. The job may have previously timed out.
Which makes sense because somehow it keeps being retried. I flushed Redis (which is my queue driver), truncated failed_jobs table and started queue:work again. This happened:
[2019-10-13 20:15:06][1] Processing: App\Jobs\GeneratePopularDownloadStats
[2019-10-13 20:15:06][1] Processed: App\Jobs\GeneratePopularDownloadStats
[2019-10-13 20:16:36][1] Processing: App\Jobs\GeneratePopularDownloadStats
[2019-10-13 20:16:36][1] Processed: App\Jobs\GeneratePopularDownloadStats
[2019-10-13 20:18:06][1] Processing: App\Jobs\GeneratePopularDownloadStats
[2019-10-13 20:18:06][1] Processed: App\Jobs\GeneratePopularDownloadStats
[2019-10-13 20:19:36][1] Processing: App\Jobs\GeneratePopularDownloadStats
[2019-10-13 20:19:36][1] Failed: App\Jobs\GeneratePopularDownloadStats
[2019-10-13 20:21:06][1] Processing: App\Jobs\GeneratePopularDownloadStats
[2019-10-13 20:21:07][1] Failed: App\Jobs\GeneratePopularDownloadStats
[2019-10-13 20:22:37][1] Processing: App\Jobs\GeneratePopularDownloadStats
[2019-10-13 20:22:37][1] Failed: App\Jobs\GeneratePopularDownloadStats
[2019-10-13 20:24:07][1] Processing: App\Jobs\GeneratePopularDownloadStats
[2019-10-13 20:24:07][1] Failed: App\Jobs\GeneratePopularDownloadStats
[2019-10-13 20:25:37][1] Processing: App\Jobs\GeneratePopularDownloadStats
[2019-10-13 20:25:37][1] Failed: App\Jobs\GeneratePopularDownloadStats
[2019-10-13 20:27:07][1] Processing: App\Jobs\GeneratePopularDownloadStats
[2019-10-13 20:27:07][1] Failed: App\Jobs\GeneratePopularDownloadStats
[2019-10-13 20:28:37][1] Processing: App\Jobs\GeneratePopularDownloadStats
[2019-10-13 20:28:37][1] Failed: App\Jobs\GeneratePopularDownloadStats
[2019-10-13 20:30:04][2] Processing: App\Jobs\GeneratePopularDownloadStats
[2019-10-13 20:30:04][2] Processed: App\Jobs\GeneratePopularDownloadStats
[2019-10-13 20:30:07][1] Processing: App\Jobs\GeneratePopularDownloadStats
[2019-10-13 20:30:07][1] Failed: App\Jobs\GeneratePopularDownloadStats
[2019-10-13 20:31:34][2] Processing: App\Jobs\GeneratePopularDownloadStats
[2019-10-13 20:31:34][2] Processed: App\Jobs\GeneratePopularDownloadStats
[2019-10-13 20:31:37][1] Processing: App\Jobs\GeneratePopularDownloadStats
[2019-10-13 20:31:37][1] Failed: App\Jobs\GeneratePopularDownloadStats
Easier to see as an image:
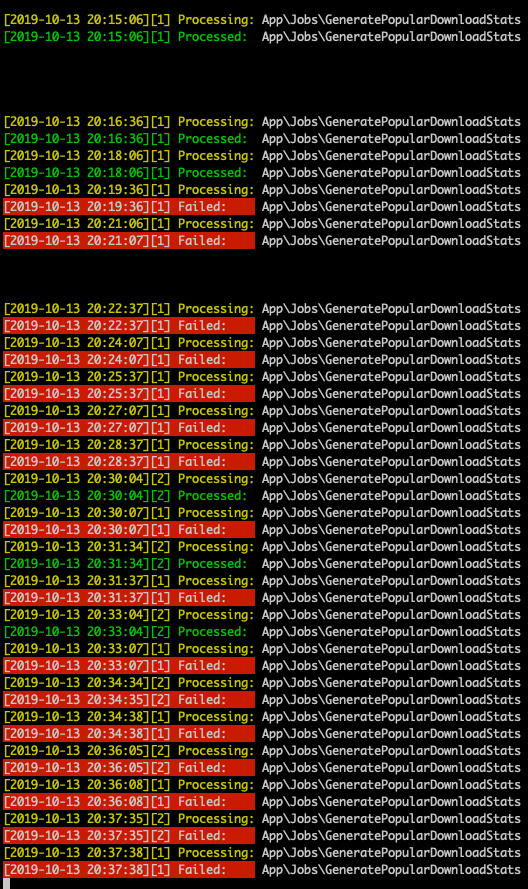
So the first run was OK and right on the 15 min mark of the hour. Then after a minute it for some reason decides to run again, and again the next minute. After that it keeps being run every min but fails with the error shown above.
BUT on the next full quarter of the hour (20:30) the job completes successfully again? And then it fails and then it’s successful again after which it keeps failing. What the actual fuck?
I am really lost on this one. How does it even run multiple times per minute when the cronjob for the scheduler only runs every minute?
About this issue
- Original URL
- State: closed
- Created 5 years ago
- Comments: 22 (4 by maintainers)
We’re seeing this issue as well even with predis. After a couple of days of debugging and trying out different things we realized that
retry_afterwas retrying a running job. For the time being we increased that value to be over the job’s timeout.Maybe it’s worth reopening this.
Ah, yeah. I remember it running all queues but my brain is so chaotic because of all the debugging that I’m most probably wrong.
Thanks for the help btw! Hopefully this issue helps others who try to run Redis/Laravel with IGBinary (with or without laravel-lodash).