external-dns: AWS provider triggers lots of "Throttling: Rate exceeded\n\tstatus code: 400"
This issue is related to #891 It has not been fixed by #966
AWS limits 5 api requests to Rout53 per account every second. Details here.
If hosted zone ids or domain names are not provided, AWS provider list records of all hosted zones. See code here.
For account with multiple hosted zones (or multiple EKS clustesr with external-dns), this results in Throttling: Rate exceeded\n\tstatus code: 400 every minute and dns changes do not propagate on schedule.
We can provide hosted zone ids or domain names to external-dns at startup, however that ties cluster infrastructure with services being deployed on the cluster. That’s not ideal.
This article describes how to deal with api request limits.
Few suggestions to fix this:
- Do not list records from a hosted zone if none of the endpoints being managed are in hosted zone domain or subdomains
- Look for this error and do exponential backoff
About this issue
- Original URL
- State: closed
- Created 5 years ago
- Reactions: 51
- Comments: 33 (13 by maintainers)
Commits related to this issue
- Add cache at provider level **Description** In the current implementation, DNS providers are called to list all records on every loop. This is expensive in terms of number of requests to the provide... — committed to tjamet/external-dns by deleted user a year ago
- Add cache at provider level **Description** In the current implementation, DNS providers are called to list all records on every loop. This is expensive in terms of number of requests to the provide... — committed to tjamet/external-dns by deleted user a year ago
For what it’s worth, I worked around the issue by using this external-dns Helm chart with these values: https://artifacthub.io/packages/helm/bitnami/external-dns
The default interval is 1 minute, which is really short - it spams Route53, which gives us these rate exceeded messages. I set mine to 10 minutes, and then turned on triggerLoopOnEvent, so I don’t actually have to wait 10 minutes for it to create a record. It creates records immediately when the ingresses are created. I could probably turn the interval up to 60 minutes or higher at this point. I haven’t experimented more with it because I no longer have the problem…
Hi! We are also suffering hardly this issue. On our side, we have deployed a temporary fork of external-dns with several improvements I am currently backporting and contributing to the main code.
We currently have opened #2009 and #2010 that, combined, help reduce the total amount of AWS calls by a factor of around 6 under specific circumstances.
Currently, the API call rate is only reduced by a factor of 3 if several instances of external-dns are run towards the same zone and different owner IDs. We are working to contribute the fixes for those as well. Either by the use of #1724 that should help in this area or other means.
Just a quick request for an update, is there any estimated date that this will proceed.
We are also using the event flag, with a sync period of 10 minutes We have 8000+ objects monitored in 6 clusters, using the same zone.
With the current Minimum Sync Interval of 5 seconds, and the necessity of listing all records at least once during the sync, it raises the number of calls to the AWS API.
With this in mind, we are now running, in addition to the changes of #2009 and #2010, a change where the MinInterval has been set to a configurable 1 minute proposed in #2013, and few more improvements relying on #1724
All of those combined leads us to a significant decrease in API calls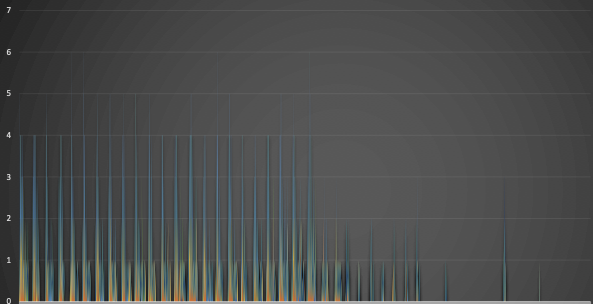
And made our whole registry errors disappear: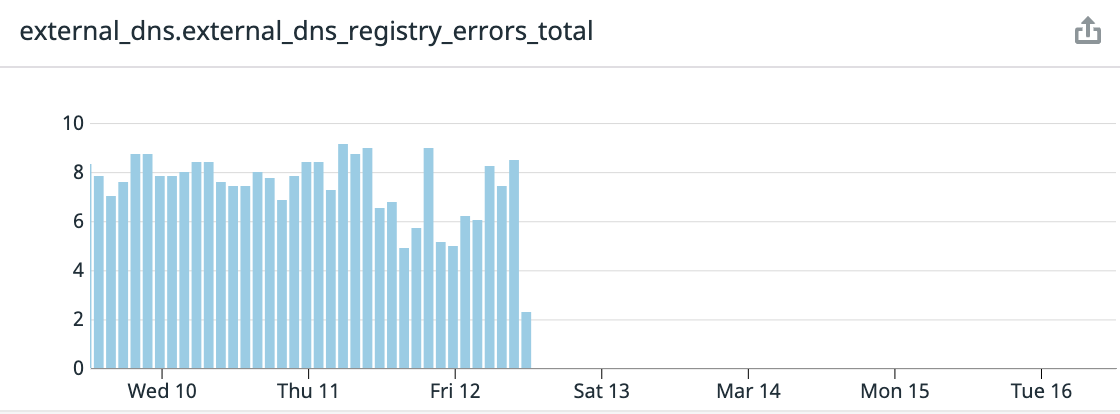
/remove-lifecycle stale Having this issue as well.