kubernetes: Windows Kubernetes - Kube-Proxy panics/exits
What happened?
Kube-Proxy version: Kubernetes v1.24.10-eks-7abdb2b AWS EKS 1.24
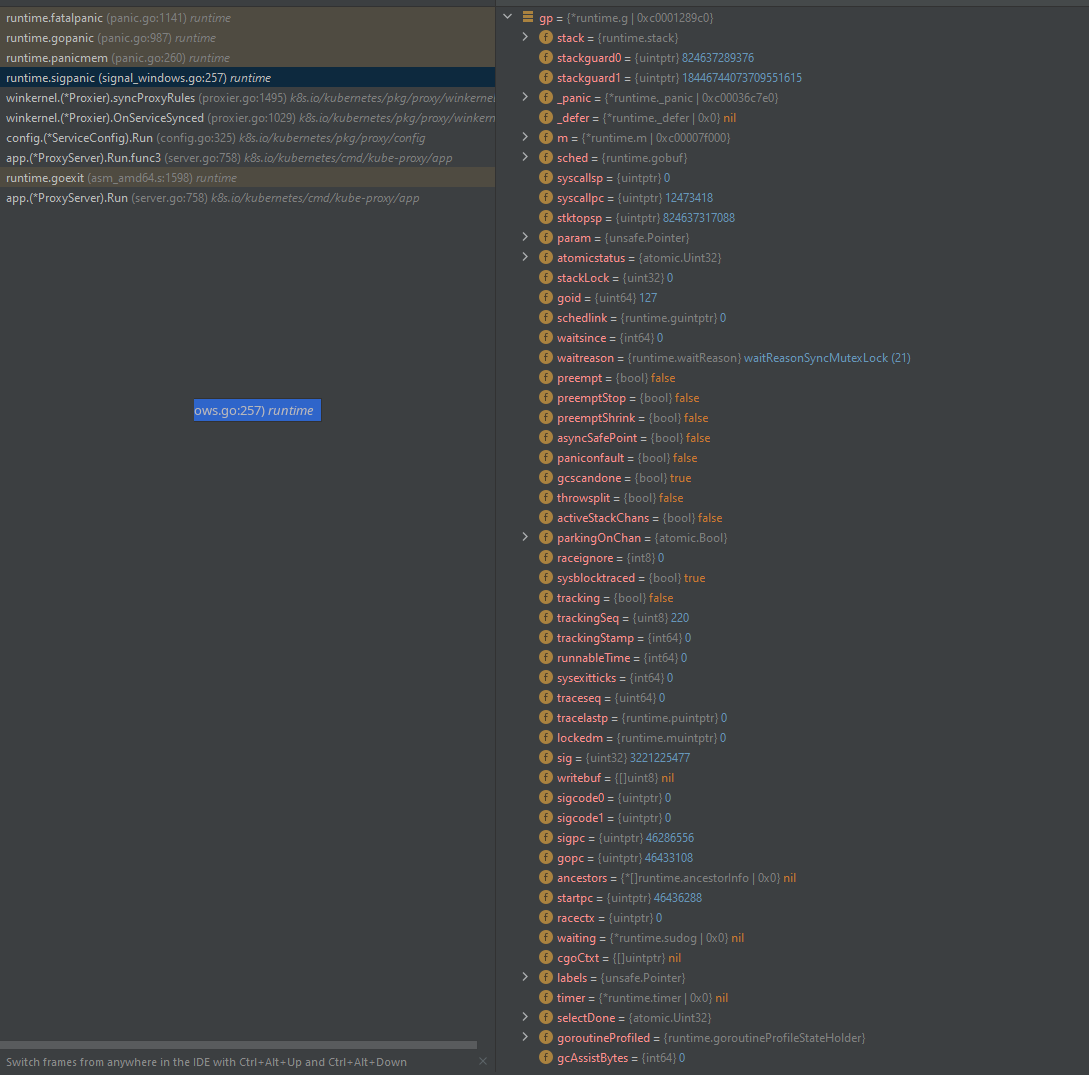
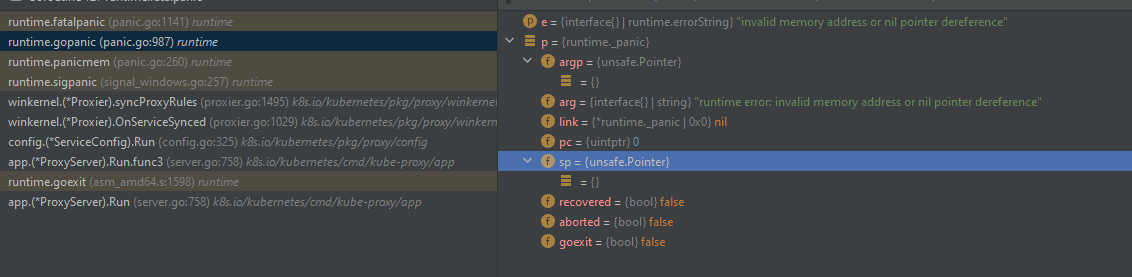
runtime.fatalpanic (panic.go:1141) runtime
runtime.gopanic (panic.go:987) runtime
runtime.panicmem (panic.go:260) runtime
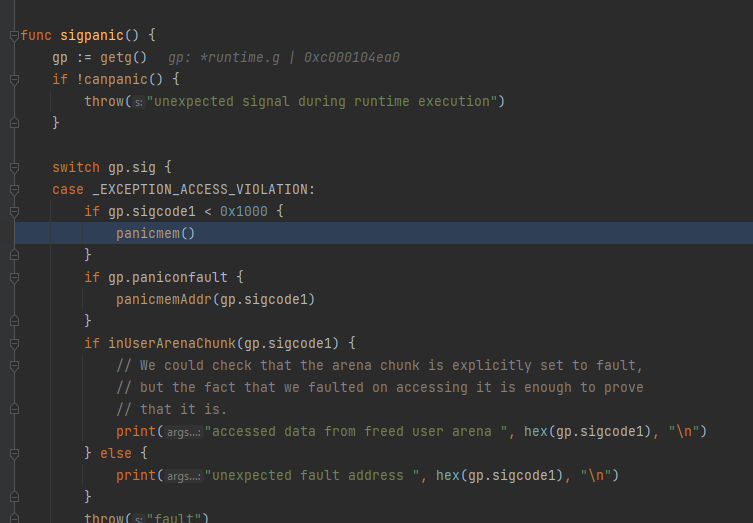
runtime.sigpanic (signal_windows.go:257) runtime
winkernel.(*Proxier).syncProxyRules (proxier.go:1495) k8s.io/kubernetes/pkg/proxy/winkernel
winkernel.(*Proxier).OnServiceSynced (proxier.go:1029) k8s.io/kubernetes/pkg/proxy/winkernel
config.(*ServiceConfig).Run (config.go:325) k8s.io/kubernetes/pkg/proxy/config
app.(*ProxyServer).Run.func3 (server.go:758) k8s.io/kubernetes/cmd/kube-proxy/app
runtime.goexit (asm_amd64.s:1598) runtime
app.(*ProxyServer).Run (server.go:758) k8s.io/kubernetes/cmd/kube-proxy/app
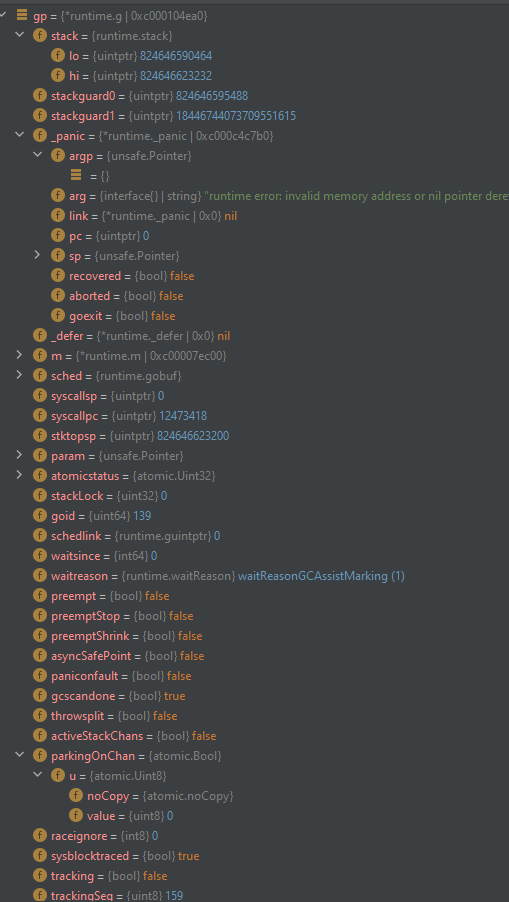
I pulled the 24 branch locally and built with debug so I could run it on the same instance.
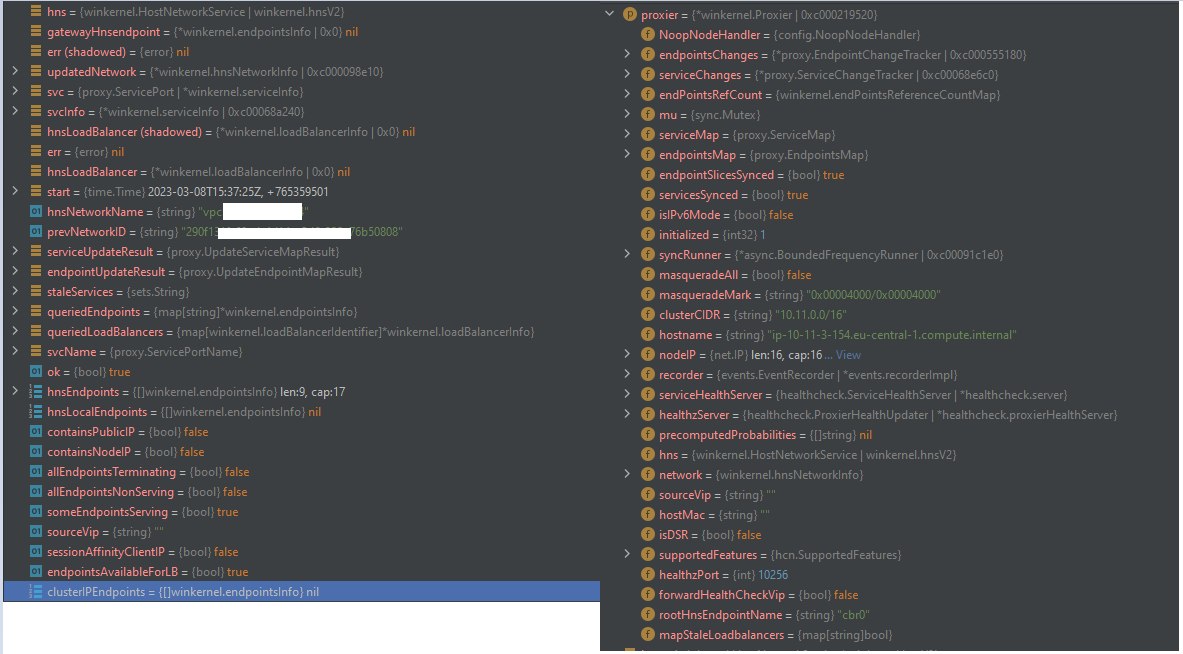
The error appears to be from proxier.syncProxyRules() > syncProxyRules (winkernel/proxier.go line 1495)
the hns.getLoadBalancer call is made but the load balancer etc are null

etLoadBalancer doesn’t error and instead returns nill, leaving the hnsLoadBalancer property access in the next assignment (svcInfo.hnsId = hnsLoadBalancer.hnsID) to blow.
Running an older docker based ami seems fine (kube-proxy Kubernetes v1.23.16-eks-7abdb2b) as in it doesn’t panic and quit. In order to isolate it a bit more I’ve copied the kube-proxy off the EKS23 image into the EKS24; which works fine also (excluding the issue being the windows machines itself)
kubelet-config-json.txt delv_log.txt kubeconfig.txt goroutines.txt Kube-Proxy Event Logs EKS23-working-kube-proxy.log EKS24-failing-kube-proxy.log EKS24-running-kube-proxy23.log
What did you expect to happen?
Kube proxy should never panic as far as I’m aware. The service does it repeatedly without failure.
How can we reproduce it (as minimally and precisely as possible)?
Not sure to be honest; but if you require more logs etc I have the logs collected by the microsoft sdn for the instance (from https://github.com/microsoft/SDN/blob/master/Kubernetes/windows/debug/Debug.md) that I can send on request (they’re verbose as heck).
It’s an EKS 1.24 cluster in frankfurt. The datadog install is a standard helm affair running on the linux nodes alone.
helm repo add datadog-direct https://helm.datadoghq.com
helm repo update
helm upgrade --install datadog-linux datadog-direct/datadog --namespace datadog -f datadog_agent_nix.yaml
contents of datadog_agent_nix.yaml
registry: public.ecr.aws/datadog
targetSystem: "linux"
datadog:
apiKey: xx
appKey: xx
clusterName: aws-eks-xx
logLevel: error
nonLocalTraffic: false
site: datadoghq.eu
kubeStateMetricsCore:
enabled: false
kubeStateMetricsEnabled: false
orchestratorExplorer:
enabled: false
clusterChecksRunner:
enabled: false
dogstatsd:
port: 8125
nonLocalTraffic: true
useHostPort: true
useSocketVolume: true
ignoreAutoConfig: true
clusterAgent:
replicas: 2
createPodDisruptionBudget: true
agents:
enabled: true
useConfigMap: false
Anything else we need to know?
No response
Kubernetes version
Cloud provider
OS version
Install tools
Container runtime (CRI) and version (if applicable)
Related plugins (CNI, CSI, …) and versions (if applicable)
About this issue
- Original URL
- State: closed
- Created a year ago
- Comments: 18 (11 by maintainers)
ok so … sounds like we need to push this cherry-pick also to 1.25.x ?
I’m going to close this: For folks wanting the up to date Kube-proxy windows code w/o this bug, make sure to upgrade to 25.8/24.12 !
ok I see, these commits will be in
1.25.8 1.24.12
So pull those latest Kube proxy and you’ll have these fixes…!!!
^ were going to suspect 1.24.12 fixes this for now… let us know thanks @ChrisMcKee !