kubernetes: Topology Aware Hint does not consider node taints
What happened?
Consider a K8S cluster which is spread across several zones. In each zone there can be many node-groups which is the unit for Cluster-Autoscaler. Typically you would create different node groups either with different node labels or taints which will help the Cluster Autoscaler to scale a specific node group (optionally in a specific zone) in case there are unscheduled pods or over-utilised nodes.
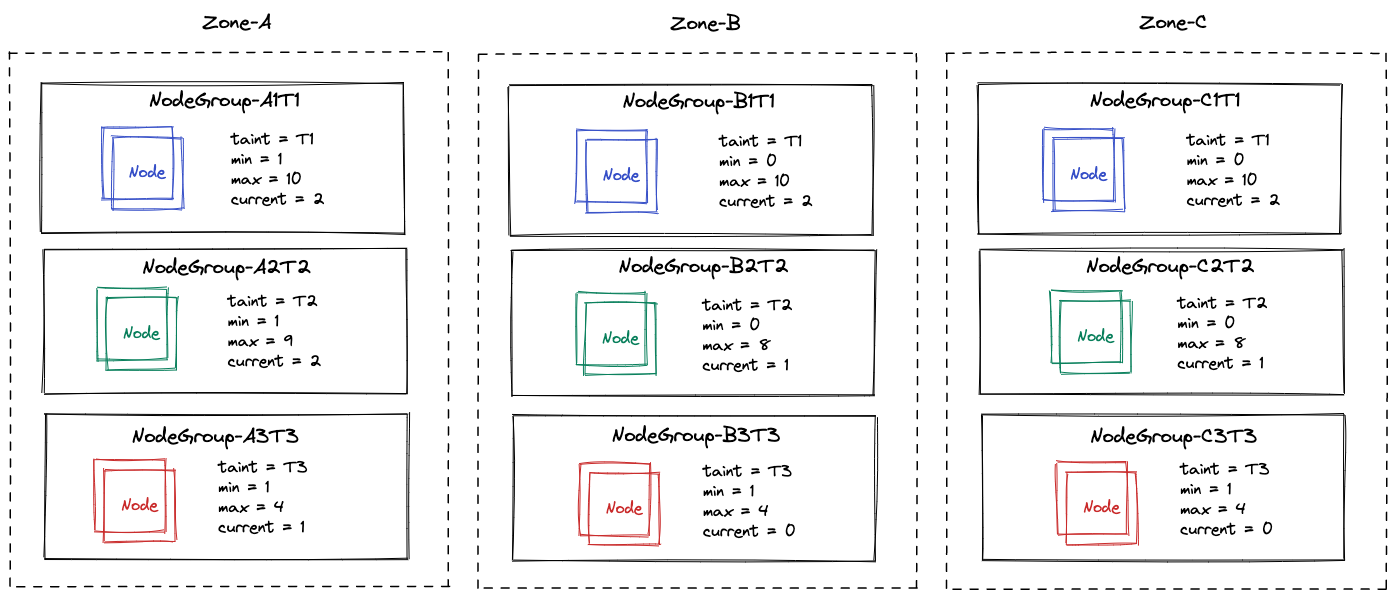
In the above setup for nodes in each node group across zones taints are added so that workloads which have tolerations to the taint can be scheduled across zones.
Also consider the following Allocatable CPU for each node across node groups/zones:
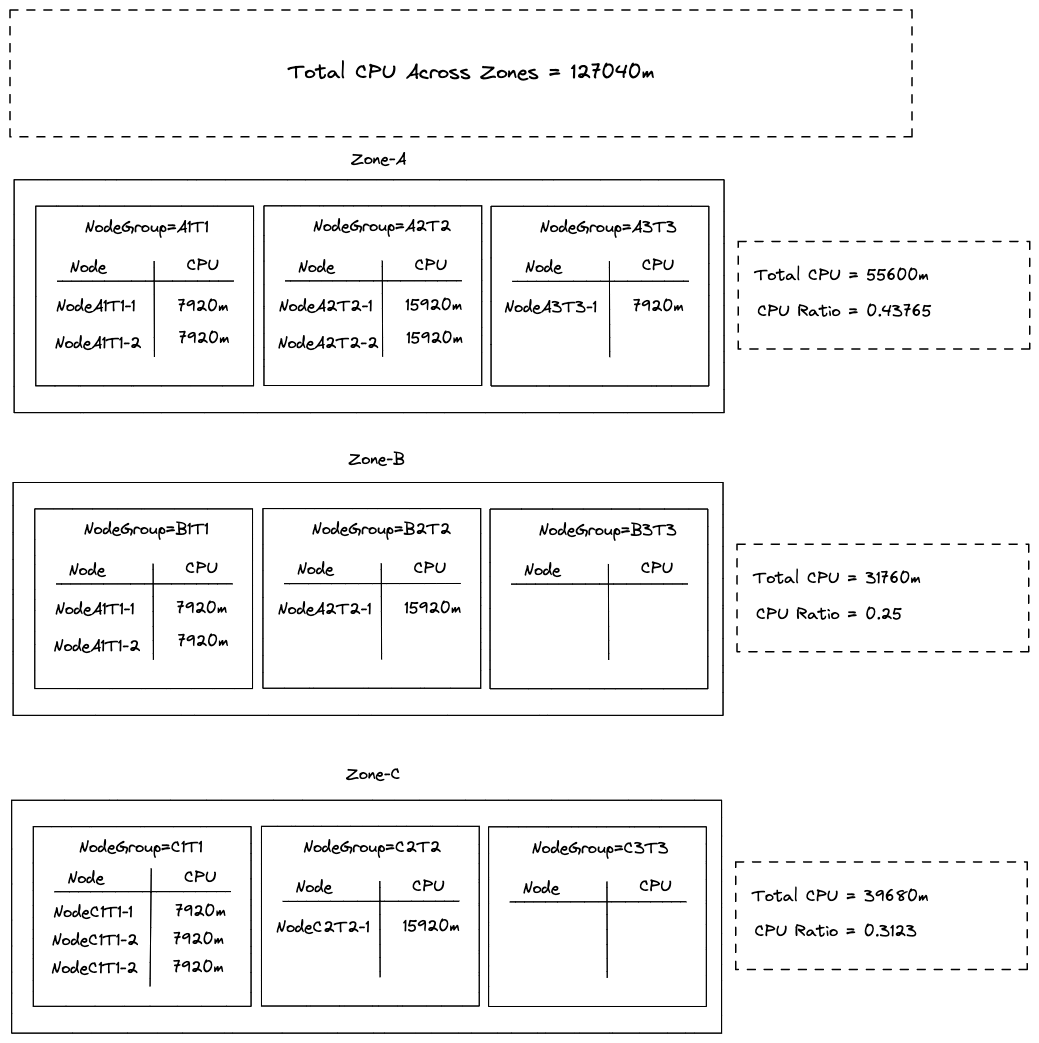
Now consider a service whose pods are only deployed on nodes where the taint = T1. This will target node groups: NodeGroup-A1T1, NodeGroup-B1T1 and NodeGroup-C1T1. If you look at the cpu ratio per zone then as per the current implementation of endpointslice controller the hints will be removed.
Why is this the case?
It is because: cpu-ratios of Zone-A is almost twice as large as cpu-ratio of Zone-B.
In topologycache.go method getAllocations will return nil which will cause any hints to be removed.
Cluster-Autoscaler can scale each node group at anytime resulting in change of cpu-ratios in a zone. This further impacts the determinism with which topology aware hints will be effective.
What did you expect to happen?
If you consider only the nodes which are having a specific taint (T1) then you will get the following total allocatable CPU:
Zone-A: { Total CPU: 15840m} Zone-B: {Total CPU: 15840m }
Zone-C: { Total CPU: 15840m` }
This is an equitable distribution and therefore should result in addition of hints. However, in the current implementation taints are not considered to filter the nodes that should be considered for a specific service endpoints. Considering that there can be several node groups per zone which can have different taints it would be prudent if taints/labels should be considered for filtering candidate nodes.
How can we reproduce it (as minimally and precisely as possible)?
Have the above setup and just deploy a simple nginx pod (replicas = 3) + service across 3 zones as shown above. This will result in a total number of endpoints = 3. No topology aware hints will be added.
Anything else we need to know?
Write now i have tested this with k8s version 1.22 where this is an alpha feature. However i have also verified that the code in beta has no changes w.r.t computing the cpu rations for each zone.
Kubernetes version
$ kubectl version
Client Version: version.Info{Major:"1", Minor:"23", GitVersion:"v1.23.5", GitCommit:"c285e781331a3785a7f436042c65c5641ce8a9e9", GitTreeState:"clean", BuildDate:"2022-03-16T15:51:05Z", GoVersion:"go1.17.8", Compiler:"gc", Platform:"darwin/arm64"}
Server Version: version.Info{Major:"1", Minor:"22", GitVersion:"v1.22.7", GitCommit:"b56e432f2191419647a6a13b9f5867801850f969", GitTreeState:"clean", BuildDate:"2022-02-16T11:43:55Z", GoVersion:"go1.16.14", Compiler:"gc", Platform:"linux/amd64"}
Cloud provider
OS version
# On Linux:
$ cat /etc/os-release
# paste output here
$ uname -a
# paste output here
# On Windows:
C:\> wmic os get Caption, Version, BuildNumber, OSArchitecture
# paste output here
Install tools
Container runtime (CRI) and version (if applicable)
Related plugins (CNI, CSI, …) and versions (if applicable)
About this issue
- Original URL
- State: open
- Created 2 years ago
- Reactions: 6
- Comments: 30 (20 by maintainers)
@thockin, @robscott, @aojea WDYT about adding support for “static”/“deterministic” hints? For example with the annotation
service.kubernetes.io/topology-aware-hints=static.“Static” hints:
insufficient number of endpointshints won’t be addedVerticalPodAutoscaler) as a safeguard mechanism in case a Pod/Endpoint is overloadedDoes this also make sense to you?
For ratio calculation, can we include only the nodes which pods located in? Most of the Kubernetes cluster runs multiple workloads. In current implementation, CPU is counted in zonal level, which other workloads may interference the calculation.
Consider a extreme case on a shared cluster. I run a compute-intensive workload on a single AZ with a lot of dedicated instances. Meanwhile I run another application on 3 AZs. Even I use Topology Spread Constraints to balance the pods count on 3 AZs, I can’t enable topology aware hints in any situation, which will cause “overload”. But if we only consider nodes with application pods, it’s balanced and hints can be set.
Also, is there a way to change the “overload” threshold? A hard-coded 20%/30% may not suits all situation. I also agree with “static” or a “always-on” option for creating hints. Cluster administrators can choose to accept the risk, and earn reduced cross-AZ cost (which is very high for some cloud providers).
So the original “Auto” mode for topology assumes that the user has not or can not ensure that pods are distributed evenly across zones. I think there is a subset of users that want to be able to say “keep my traffic in the same zone, I’ll make sure my workloads are evenly distributed”. Fundamentally I think this requires a separate deployment + HPA per zone today. We could either make that a prerequisite of the “Auto” approach (probably a breaking change), or we could make a separate option that relies on this. Similar to the problems/limitations of the current approach, this does not work well when there are a small number of pods, say 4 pods distributed over 3 zones, but this kind of user configuration would be more predictable when it comes to autoscaling.
With the current approach, it’s not obvious from an autoscaling perspective which Pods are serving traffic for which zones. So even if you had per-zone HPAs and Deployments set up, there’s still a chance that one of your pods from one zone would get allocated to another zone, and autoscaling logic would be entirely messed up from that point on.
Obviously in the long term we want all of this to be easier, so if we could work with sig-autoscaling and sig-scheduling to scale pods up in zones that are currently receiving the most traffic/utilization, we could eventually remove the requirement for a single deployment/HPA per zone.
My concerns with this idea would be that I think many users would want different weights per Service. In many k8s environments, nodes are also upgraded/replaced pretty frequently, so keeping that label up to date could be challenging.