kubernetes: Slow connect (TCP retransmits) via NodePort
What happened: In out archutecture we have some kinda external (out-of-cluster) Ingress Controller, based on HAProxy + self-written scripts for Kubernetes service discovery (2 instances). ~60 Kubernetes services exposed via NodePort on 8 Kubernetes nodes. Each node runs kube-proxy in iptables mode.
Everything worked fine. But after cluster got more load (HTTP requests per second / concurrent connections), we are experiencing slow connects to services exposed via NodePort because of TCP retransmits.
For now have 4k RPS / 80k concurrent peak. TCP retransmits starts at ~1k RPS / 30k concurrent.
But most strange thing in this situation - retransmit count not same for haproxy/kube-node pair. For example, haproxy1 have retransmits from kube-nodes 1,2,3 and 8, but haproxy2 have almost zero retransmits from that nodes. Instead haproxy2 have retransmits from kube-nodes 4,5,6 and 7. As you can see, it is like mirrored.
See attachments for clarification. HAProxy configured with 100ms connect timeout, so it redispatches connection on timeout.


What you expected to happen: No TCP retransmits, fast connects.
How to reproduce it (as minimally and precisely as possible): Commit 50-60 deployments + NodePort-exposed services on few nodes. Load with 1k+ RPS, 30k+ concurrent cons. Observe slow connects (1s, 3s, 6s…)
Anything else we need to know?: Intercluster communication via flannel w/o cni in hostgw mode.
Tried different sysctls on nodes and haproxies. Tried ipvs mode and got much more TCP retransmits. Also tried with iptables 1.6.2 with latest flanneld to fix NAT bugs according to this article: https://tech.xing.com/a-reason-for-unexplained-connection-timeouts-on-kubernetes-docker-abd041cf7e02
For test installed on kube-nodes out-of-cluster reverse-proxy to pass traffic from outside to kubernetes services and pods - no problems. Also no problems with HostPort-exposed services.
Environment:
- Kubernetes version (use
kubectl version):Client Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.6", GitCommit:"b1d75deca493a24a2f87eb1efde1a569e52fc8d9", GitTreeState:"clean", BuildDate:"2018-12-16T04:39:52Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"} Server Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.6", GitCommit:"b1d75deca493a24a2f87eb1efde1a569e52fc8d9", GitTreeState:"clean", BuildDate:"2018-12-16T04:30:10Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"} - Cloud provider or hardware configuration: Masters: 5 x kvm VMs 16.04.6 LTS (Xenial Xerus) / 4.15.0-45-generic. Nodes: Baremetall Supermicro Intel® Xeon® CPU E5-2695 / 128 Gb RAM
- OS (e.g:
cat /etc/os-release): Prod nodes:16.04.6 LTS (Xenial Xerus)Test node:Debian GNU/Linux 9 (stretch) - Kernel (e.g.
uname -a): Prod nodes:Linux hw-kube-n1.alaps.kz.prod.bash.kz 4.15.0-45-generic #48~16.04.1-Ubuntu SMP Tue Jan 29 18:03:48 UTC 2019 x86_64 x86_64 x86_64 GNU/LinuxTest node:Linux hw-kube-n8.--- 4.9.0-8-amd64 #1 SMP Debian 4.9.144-3.1 (2019-02-19) x86_64 GNU/Linux - Install tools: Mix of hard way / ansible.
- Others: Don’t know if it is kube-proxy / iptables problem or maybe I’m just missing some sysctls / kernel params.
About this issue
- Original URL
- State: closed
- Created 5 years ago
- Reactions: 6
- Comments: 54 (26 by maintainers)
We’ve been experiencing a nearly identical problem with a nearly identical haproxy setup as @zigmund. From the haproxy side, it manifests as a high
Tcvalue, which we can mitigate somewhat by setting a lowtimeout connect+ a high number of retries. It manifests both for ingress into NodePort services and also egress from the Pod network to outside of the cluster. In both cases, we see a delay between the SYN and SYN-ACK when opening connections (both into and out of the cluster). The egress is more difficult to mitigate and results in failed connections to external services such as databases.In a packet capture, it looks like this:
Note: there is a 750ms delta between the SYN and SYN-ACK packet.
This occurs on all of our clusters regardless of Kubernetes, Calico (our CNI), or kernel version. Our clusters range from Kubernetes 1.10 up to 1.14.1 w/ kernel version 4.9 or 4.19. More heavily utilized clusters see this problem more frequently, but even mostly idle clusters demonstrate this behavior.
We did identify a single workload that seemed to be exacerbating this problem, though we don’t know why. Removing the application improved performance, but did not eliminate the behavior. The only defining characteristics of this application was that it is:
To quantify this, we have a DaemonSet that does nothing but make tiny http calls out to an extermal load balancer with a low tcp connect timeout and lots of retries & exponential backoff. We find that frequently even after 10 retries, the TCP connection will still timeout.
I’m happy to provide packet captures, settings, and communicate anything we find along the way.
If it’s helpful https://github.blog/2019-11-21-debugging-network-stalls-on-kubernetes/ describes the approach we took at GitHub to finding and mitigating most of these network stalls.
It is our native load depending on daytime. I added kube-proxy rule at ~9:30 and docker rule at ~13:00.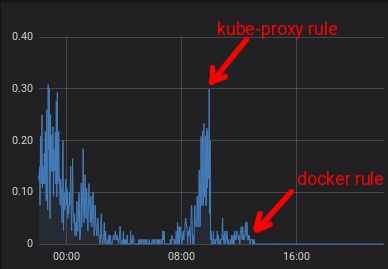
Since Docker have masquerade rule I decided to add random-fully to this rule too. The rule is for outgoing traffic from containers.