kubernetes: RingGrowing readable will be negative, which leads `index out of range`
What happened?
When I restart my pod while the cluster in high load, the restarted pod will panic.
The stack trace told me the panic was caused by index out of range in k8s.io/utils/buffer/ring_growing.go
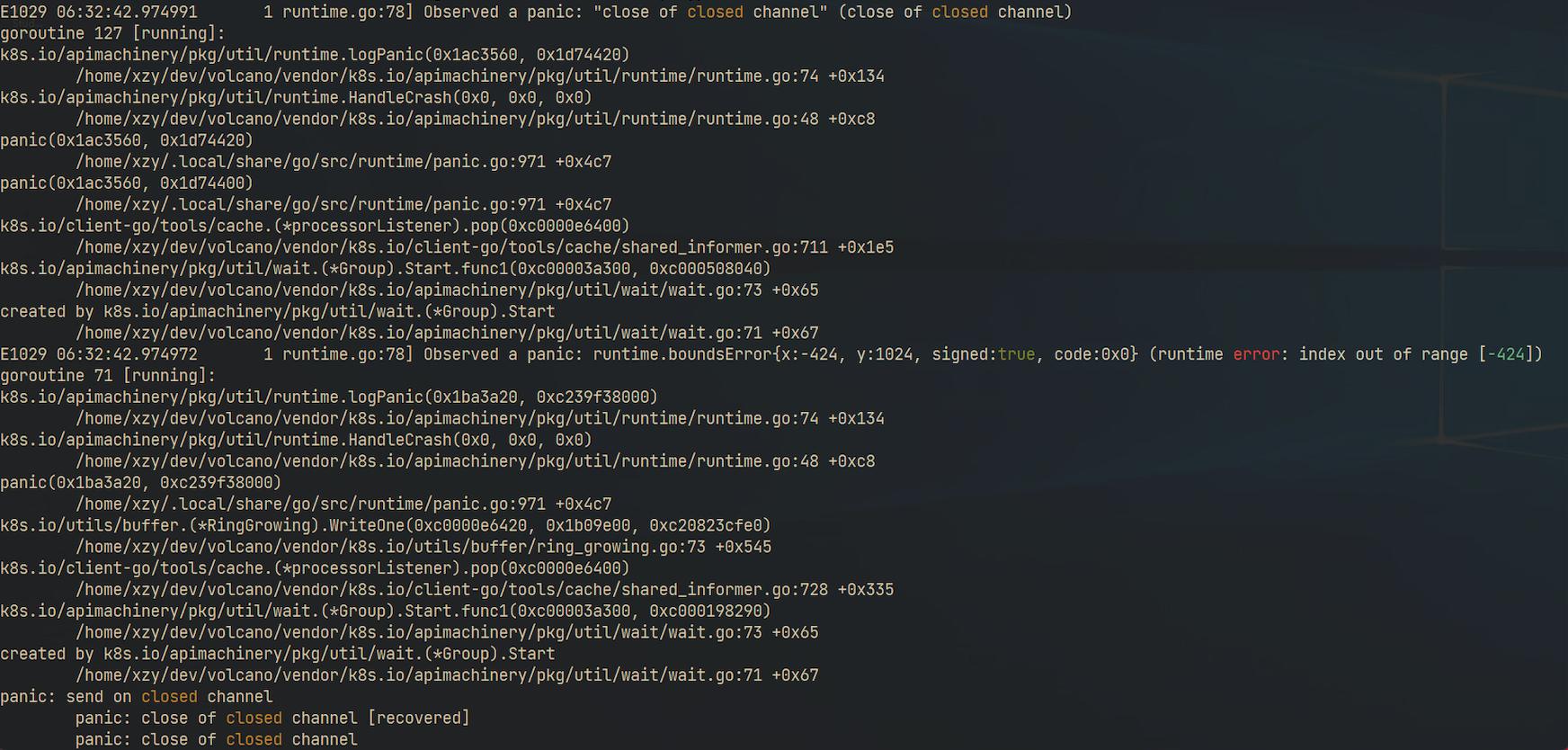
Then I read the source code of k8s.io/utils/buffer/ring_growing.go, and I found the reason.
The comment has pointed out the RingGrowing is not thread safe.
After I add the lock to RingGrowing when read/write, no panic occurs again.
What did you expect to happen?
The panic should never occur.
How can we reproduce it (as minimally and precisely as possible)?
We have over 100k(running and completed) pods in our cluster, and it’s in high load. And we use volcano as our default scheduler. When I restart the volcano-controller, the controller will panic.
Anything else we need to know?
No response
Kubernetes version
$ kubectl version
# paste output here
Cloud provider
OS version
# On Linux:
$ cat /etc/os-release
# paste output here
$ uname -a
# paste output here
# On Windows:
C:\> wmic os get Caption, Version, BuildNumber, OSArchitecture
# paste output here
Install tools
Container runtime (CRI) and and version (if applicable)
Related plugins (CNI, CSI, …) and versions (if applicable)
About this issue
- Original URL
- State: closed
- Created 3 years ago
- Comments: 23 (15 by maintainers)
Ah ha! Perhaps it is that the
.runmethod uses a read lock, but writes tolistenersStarted. theAddEventHandlerWithResyncPeriodacquires a full lock and reads thelistenersStarted, but it may not observe the written value oflistenersStarted.Do you have reliable reproducer you can try making the
.runmethodp.listenersLock.Lock()anddefer p.listenersLock.Unlock()?